本文主要是介绍【Java】Java基础 使用集合实现斗地主分牌,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

📝个人主页:哈__
期待您的关注

今天使用集合TreeSet来实现一个斗地主的分牌流程。
TreeSet集合的一个特点就是 元素有序,这样就方便我们分的牌自动排序。
0.思路
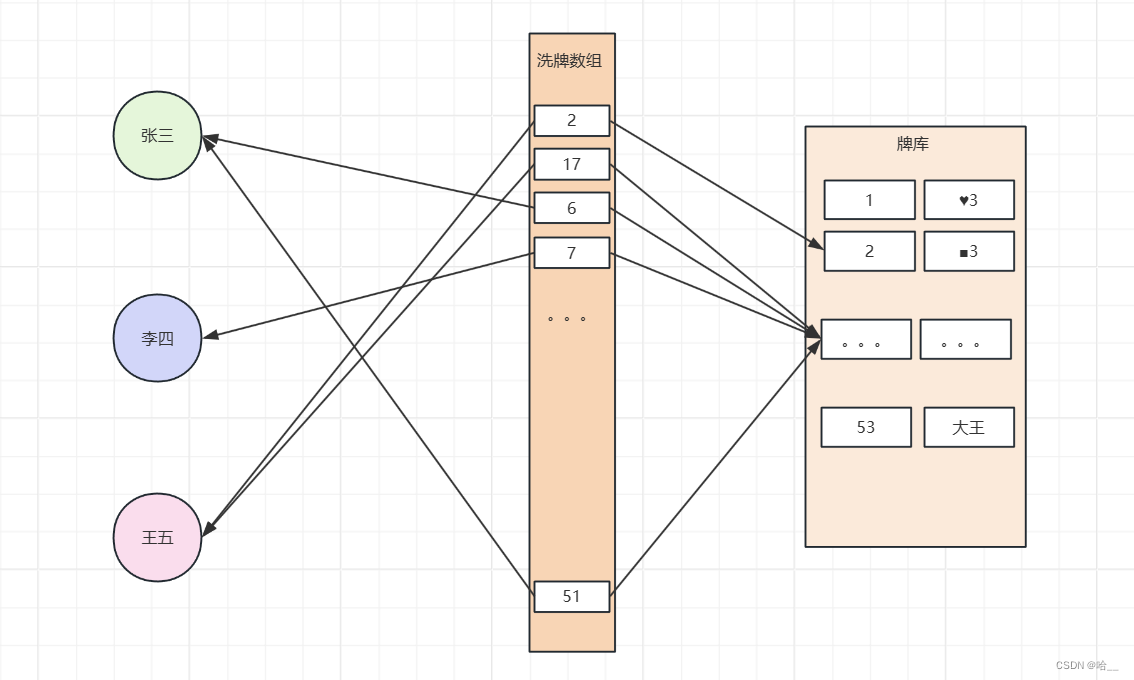
1.创建玩家手牌集合
我们到时候分的牌都存储在这里,但你可能会有疑问,因为存储的泛型是Integer,但扑克牌是有花色的,这该如何实现?
TreeSet<Integer> zhangsan=new TreeSet<Integer>();TreeSet<Integer> lisi=new TreeSet<Integer>();TreeSet<Integer> wangwu=new TreeSet<Integer>();TreeSet<Integer> dipai=new TreeSet<Integer>();2.创建牌堆
我们创建了一个名为poke的HashMap结构,poke用来存储我们的扑克,而poke的key是每一张牌的一个id,value就是具体的牌。
HashMap<Integer,String>poke=new HashMap<Integer,String>();String[] color={"♦","♣","♥","♠"};String[] number={"3","4","5","6","7","8","9","10","J","Q","K","A","2"};我们到时候洗牌的时候,洗的是这些id,但是并不是直接在poke中洗,poke的作用只是记录我们有哪些牌。所以 我们在创建一个用来洗牌的数组,并把所有的id放入。
ArrayList<Integer> xipai=new ArrayList<Integer>();3. 把牌放入牌堆
遍历我们的String数组,把花色和牌号组合一下并放入poke中,同时把poke中的key放入我们的洗牌集合中。最后不要忘了大小王。
int index=0;for(String Number:number){for(String Color:color){String POKE=Color+Number;poke.put(index,POKE);xipai.add(index);index+=1;}}poke.put(52,"小王");poke.put(53,"大王");xipai.add(52);xipai.add(53);4.洗牌
一行代码即可,使用Collecitons自带的数组打乱方法。
Collections.shuffle(xipai);5.进行分牌
如果只剩下最后三张了,就直接放入到我们的底牌集合当中,否则的话就进行模3取余操作进行判断应该分给谁。
for(int i=0;i<xipai.size();i++){if(i>=xipai.size()-3){dipai.add(xipai.get(i));}else{if(i%3==0){zhangsan.add(xipai.get(i));}else if(i%3==1){lisi.add(xipai.get(i));}elsewangwu.add(xipai.get(i));}}6.完整代码
public class Poker {public static void main(String[] args) {HashMap<Integer,String>poke=new HashMap<Integer,String>();String[] color={"♦","♣","♥","♠"};String[] number={"3","4","5","6","7","8","9","10","J","Q","K","A","2"};ArrayList<Integer> xipai=new ArrayList<Integer>();TreeSet<Integer> zhangsan=new TreeSet<Integer>();TreeSet<Integer> lisi=new TreeSet<Integer>();TreeSet<Integer> wangwu=new TreeSet<Integer>();TreeSet<Integer> dipai=new TreeSet<Integer>();int index=0;for(String Number:number){for(String Color:color){String POKE=Color+Number;poke.put(index,POKE);xipai.add(index);index+=1;}}poke.put(52,"小王");poke.put(53,"大王");xipai.add(52);xipai.add(53);Collections.shuffle(xipai);//进行发牌for(int i=0;i<xipai.size();i++){if(i>=xipai.size()-3){dipai.add(xipai.get(i));}else{if(i%3==0){zhangsan.add(xipai.get(i));}else if(i%3==1){lisi.add(xipai.get(i));}elsewangwu.add(xipai.get(i));}}//进行看牌,用方法实现LookPoker("张三",gyh,poke);LookPoker("李四",zch,poke);LookPoker("王五",wjq,poke);LookPoker("底牌",dipai,poke);//System.out.println(poke);}public static void LookPoker(String name,TreeSet<Integer>set,HashMap<Integer,String>map){System.out.print(name+"的牌是:");for(Integer i:set){String poke=map.get(i);System.out.print(poke+" ");}System.out.println();}
}这篇关于【Java】Java基础 使用集合实现斗地主分牌的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



