本文主要是介绍SPP/Fast R-CNN/Faster R-CNN/r fcn,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1,SPP spatial pyramid pooling空间金字塔池,基于图像金字塔
SPP-net解决了R-CNN重复提取候选区域特征的问题,同时允许各种尺寸图像作为输入,解决了图像畸变的问题,
2,R-CNN的作用比较强,其主要缺陷就是效率问题:
计算量大,速度慢:每张图像的每个Propasal均需要通过CNN提取高阶特征、SVM进行分类操作。
图像失真:每个Propasal区域在输入CNN网络之前,需要进行warp拉伸操作,可能会影响图 像质量以及模型效果。
3,SPP Net优化改进:
直接送入整个图像,所有区域共享卷积计算(一遍) • 在Conv5层提取所有区域的高阶特征
引入空间金字塔池(Spatial Pyramid Pooling)
为不同尺寸的区域,在Conv5层上提取不同的特征,然后映射到尺寸固定的全连接上 retufit
4, 卷积的计算
output=(input-窗口+步长-2 *padding)/步长

反过来就是这个了。ri就是第i层featuremap大小
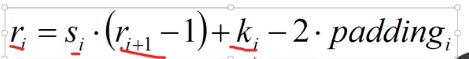
5,感受野
计算中心点位置

6 ,SPP Layer计算
spp net 卷积核ceil,和步长计算。池化是不做填充的,输出向下取整,ceil向上取整,stride向下取整。

7,spp介绍
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪(crop)和拉伸(warp)。
这样做总是不好的:图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。而Kaiming He在这里提出了一个SPP(Spatial Pyramid Pooling)层能很好的解决这样的问题, 但SPP通常连接在最后一层卷基层。
SPP 显著特点
1) 不管输入尺寸是怎样,SPP 可以产生固定大小的输出
2) 使用多个窗口(pooling window)
3) SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
先对整张图片进行卷积然后,在把其中的目标窗口拿出来Pooling,得到的结果用作全连接层的输入。
特点:只需要计算一次卷积层,训练速度快。
8,Fast R-CNN

9,特征信息,比如圆形信息
10,R CNN系列算法比较
R-CNN
(1)image input;
(2)利用selective search 算法在图像中从上到下提取2000个左右的Region Proposal;
(3)将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征;
(4)将每个Region Proposal提取的CNN特征输入到SVM进行分类;
(5)对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标.
缺陷:
(1) 训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器;
(2) 训练耗时,占用磁盘空间大;5000张图像产生几百G的特征文件;
(3) 速度慢:使用GPU,VGG16模型处理一张图像需要47s;
(4) 测试速度慢:每个候选区域需要运行整个前向CNN计算;
(5) SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新.
FAST-RCNN:
(1)image input;
(2)利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
(3)将整张图片输入CNN,进行特征提取;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比R-CNN,主要两处不同:
(1)最后一层卷积层后加了一个ROI pooling layer;
(2)损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练
改进:
(1) 测试时速度慢:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成的图像都会单独通过CNN提取特征.实际上这 些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费.
FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享.
(2) 训练时速度慢:R-CNN在训练时,是在采用SVM分类之前,把通过CNN提取的特征存储在硬盘上.这种方法造成了训练性能低下,因为在硬盘上大量的读写数据会造成训练速度缓慢.
FAST-RCNN在训练时,只需要将一张图像送入网络,每张图像一次性地提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算且不再需要把大量数据存储在硬盘上.
(3) 训练所需空间大:R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间.FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储.
(4) 由于ROI pooling的提出,不需要再input进行Corp和wrap操作,避免像素的损失,巧妙解决了尺度缩放的问题.
FASTER -RCNN:
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比FASTER-RCNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
改进:
(1) 如何高效快速产生建议框?
FASTER-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.
概念了解
1,SPP 多尺度特征提取出固定大小的特征向量
2, ROI pooling SPP精简版,ROI pooling layer只需要下采样到一个7x7的特征图
3,Bbox 回归 寻找一种关系是的输入原始的窗口p经过映射得到一个跟真实窗口G更接近的回归窗口G`
4, RPN RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
原文链接:https://blog.csdn.net/weixin_43198141/article/details/90178512
全卷积和全连接
https://github.com/Captain1986/CaptainBlackboard/blob/master/D%230025-CNN%E4%B8%AD%E4%BD%BF%E7%94%A8%E5%8D%B7%E7%A7%AF%E4%BB%A3%E6%9B%BF%E5%85%A8%E8%BF%9E%E6%8E%A5/D%230025.md
这篇关于SPP/Fast R-CNN/Faster R-CNN/r fcn的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







