本文主要是介绍【R语言】对EXCEL多行或多列数据合并成一行或一列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于很多行或很多列数据合并成一行或一列数据,手动是非常麻烦的,尤其当行列数无穷大,根本无法手动处理,在这里价绍一种解决办法:运行R语言,对数据的快速合并。
这里一多列合并成一列为例(如果是多行,可以转置成多列,再合并成一列)
例如我的数据形式:
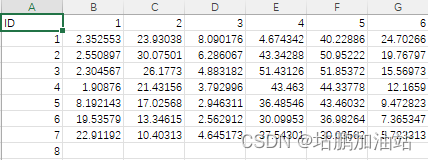
后面还有很多列,并且还有缺少和多余的情况,例如:
缺少:

多余:
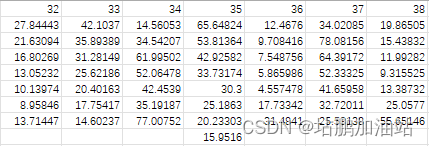
不过无妨,把这个结果存储成csv文件,我这边叫"模型结果"
然后运行以下R代码:
library(reshape2)
data<-read.csv("模型结果.csv")melted_df <- melt(data, id.vars = "ID", na.rm = TRUE)#对于缺少的情况,这里对NA值即空值的处理,多余的情况,在ID处多选一行就行了write.csv(melted_df$value, file = "模型结果处理后.csv", row.names = FALSE)
就变成一列数据了:

这篇关于【R语言】对EXCEL多行或多列数据合并成一行或一列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








