本文主要是介绍清华军团推出中国首个对标Sora的视频大模型Vidu,扒一扒它背后的模型架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
就在前天,Vidu 在 2024 中关村论坛年会之中横空出世。

伴随着“中国首个”,“Sora 级视频模型”,“模拟真实的物理世界”等关键词下的刷屏式的报道,Vidu 一下成为国产视频模型的一剂强心针。
尽管目前 Vidu 支持的视频长度是 16 秒,尚未达到 Sora 的 60 秒级,但是单看 Vidu 的宣传视频,如果以 Sora 为对标,可以看出 Vidu 在如时空一致性、物理规律遵循以及多镜头等等方面都已经对 Sora 不遑多让。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
背靠清华军团,提出全球首个Diffusion + Transformer架构U-ViT,早于Sora
撇开视频的质量不说,笔者发现了一个更牛逼的事情:
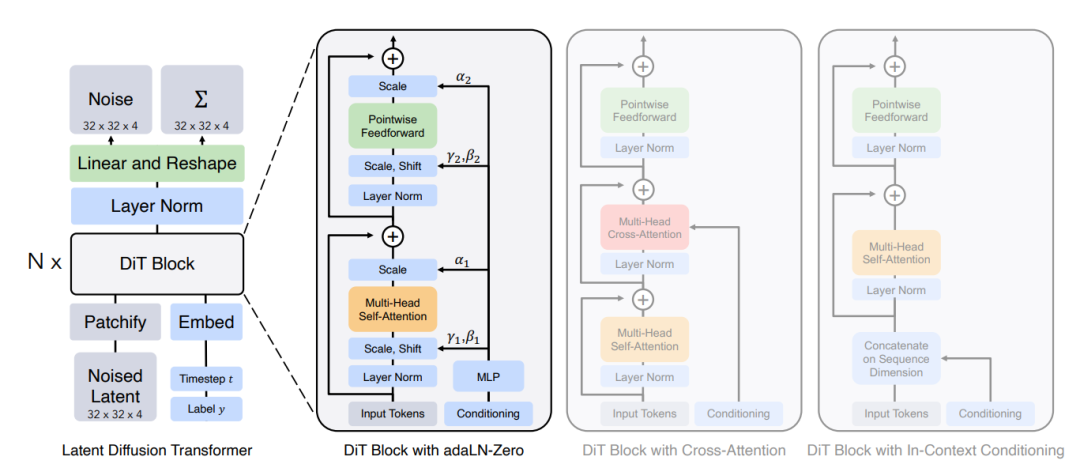
Vidu背后的模型架构U-ViT 和 Sora 的核心架构 Diffusion Transformer(DiT)完全一致,且更早于DiT的发表时间。
这家在 2023 年 3 月份成立的“清华军团”生数科技,其实早在 2022 年 9 月,其创业团队就发布了基于 Transformer 架构的底层统一网络框架 U-ViT。
而Sora 的核心架构 Diffusion Transformer(DiT) 发布于 2022 年 12 月。
但其实这两项工作在架构思路与实验路径上完全一致,核心 idea 都在于将 Transformer 与 Diffusion Model 进行结合。

论文链接:
https://arxiv.org/pdf/2209.12152
而也因此,人工智能领域的著名科学家,清华大学人工智能研究院副院长、也是生数科技的首席科学家朱军教授面对 Sora 就曾提到:“虽然Sora的出现表明美国在多模态大模型领域具有领先性,但是中国也并非完全从零开始的阶段”
其实就在 Sora 发布后不久,我们就梳理了当时国内「类Sora模型」的发展现状,在当时尽管文生视频模型国内已经有不少大厂创企进行过尝试,但是那时的视频生成可能还只能是说“让图片动起来”,大部分的改进也都是在于如何让这个动起来的图片更高清或分辨率更高,而不是像 Sora 一样直接作为一个 World Simulator 而出现。
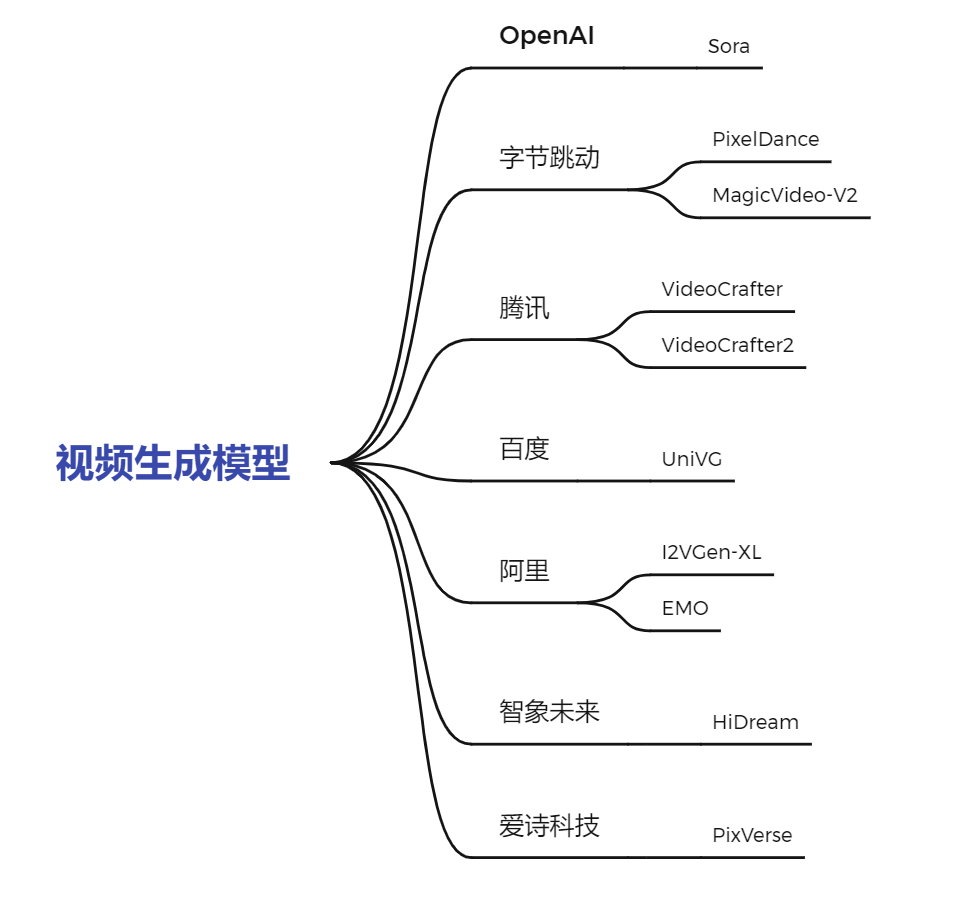
不单在国内,自 Sora 发布以来的三个月,Vidu 目前是世界唯一一个突破 Sora 级的视频大模型。其实如果从 Transformer + Diffusion Model 这个 idea 构建伊始去看 Vidu,我们可以发现从一开始 Vidu 与 Sora 事实上就在走同一条路线。
2023 年 3 月,对标文生图的 Stable Diffusion,生数科技就已经开源了全球首个基于 U-ViT 框架的多模态扩散大模型 UniDiffuser,其模型参数量从最早开源版的 1B 不断扩展至 3B(30亿)、7B、10B及以上,参数量和训练数据规模上都与 Stable Diffusion 直接对齐,成功完成 U-ViT 的可扩展性验证。
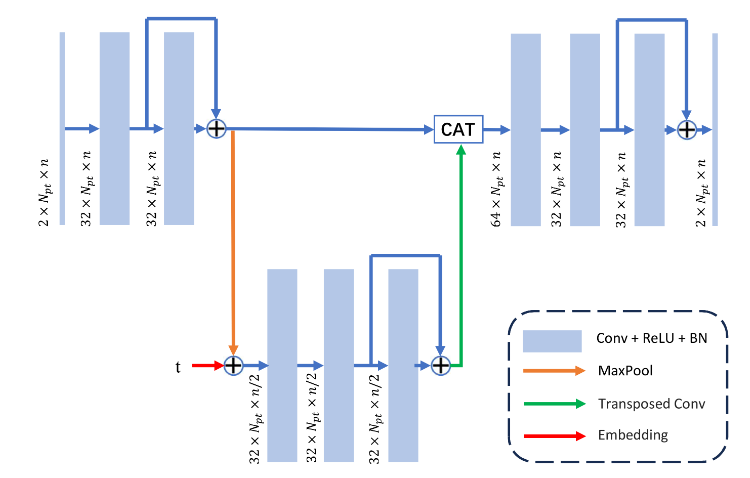
从 Diffusion Model 的最初的网络架构——基于 CNN 的 U-Net 架构出发,与 Sora 的 DiT 一样,U-ViT 的核心思想都在于将基于 CNN 的网络替换为基于 Transformer 的网络。
从 2019 年 Song Yang 那篇从 Score-Based Model 视角理解生成模型的文章首次使用 U-Net 伊始,后续扩散模型的各种标杆工作,如大名鼎鼎的 DDPM,ADM,Imagen 等等都基于 U-Net 架构对 Diffusion Model 中的“噪音”进行建模,一个传统的 U-Net 网络大致如下图所示:
而其实随着 Vision Transformer(ViT)逐渐在各类视觉任务中展露头面,一个很自然的想法其实就是“扩散模型网络架构是否一定需要基于 CNN?”,这个答案很快就被 U-ViT 与 DiT 所回答:“显然不是,甚至 Transformer 更好”
而为了验证最开始的“直觉”,U-ViT 设计了如下的基于 ViT 的网络架构,利用 ViT 的思路,U-ViT 将带噪图片划分多个 Patch,结合扩散模型中的扩散时间步,条件等等作为 Token 输入到 Transformer Block 之中。
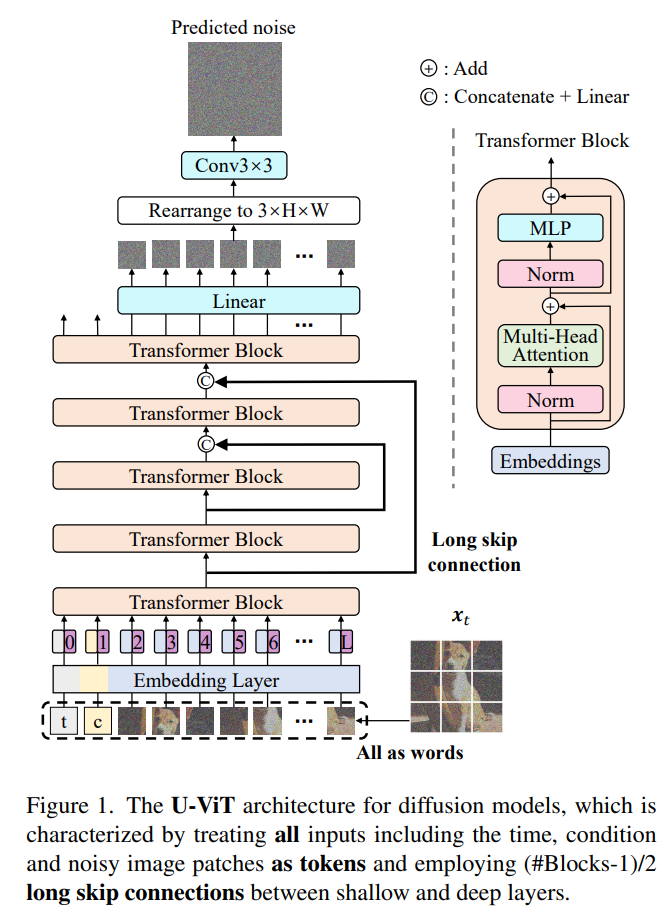
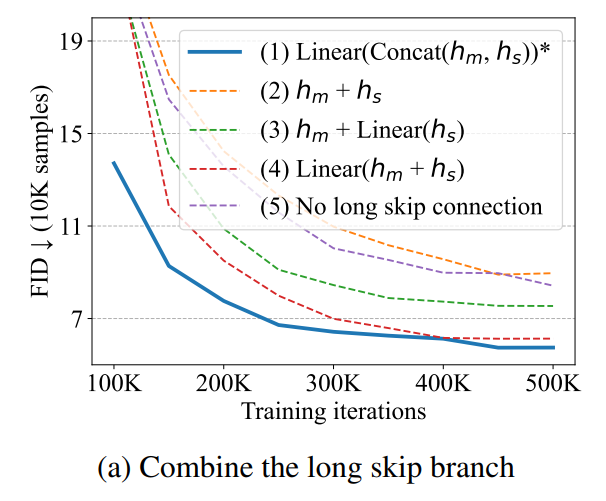
除了这步将 ViT 模式搬运到扩散模型中的一步以外,U-ViT 还受 U-Net 启发,采用了浅层和深层之间的 Long skip Connection。采取 Long skip Connection 的直观在于,扩散模型利用预测噪声“去噪”的过程,高度依赖图像中的“Low-Level Feature”,例如边缘,角,颜色等等,而这种连接通过将 Low-Level Feature 从网络的浅层引入到深层,从而大大提升了扩散模型的预测能力,也进一步的提升了模型的图像生成能力。
而 Sora 背后的 DiT 思路也几乎完全一致,最核心的一步都是将 ViT 引入到扩散模型之中,实现 VAE encoder + ViT + DDPM + VAE decoder 的组装:
U-ViT曾被CVPR 2023拒稿,后被ICCV 2023 接受
有意思的插曲是,DiT 最初也是投稿于 CVPR 2023,但是由于CVPR 2023 收录了 U-ViT 论文,因此 DiT 被以「缺乏创新」为由而拒稿,后来才被 ICCV 2023 接收:

当然彼时,无论是 U-ViT 还是 DiT 都还停留在图像生成的领域,尚且还未发展到视频生成这一步,不过在 2023 年 3 月,朱军教授团队的工作 UniDiffuser 在 U-ViT 的基础上,将扩散模型往多模态方向推进了一步。UniDiffuser 除了单向的文生图以外,还能实现如图生文,图文联合生成,图文改写等等能力,从「多模型」出发,UniDiffuser 其实早在一年前就为今天 Vidu 的出现埋下了伏笔。

在 Vidu 发布之后,朱军教授发声:“Vidu,we do, we did, we do together!感谢小伙伴们日以继夜的坚持,在实验室架构上开花结果。”
其实,可能与许多其他公司基于「复制」的“追赶者战略”不同,Vidu 实实在在的从机器学习与多模态大模型的理论研究与训练经验中走出了一条自己的道路,可能也正是因为这些积累,才让 Vidu 在短短两个月的时间内就突破了 Sora 背后的许多关键技术。
而甚至不同于 Sora 的视频生成,Vidu 一开始就建立在一个多模态扩散模型的基础之上。当下视频生成可能也仅仅是 Vidu 的一个展示形态,从这个意义上来讲,可能 Vidu 当下可以许诺的,不仅仅是一个“中国版的 Sora”那么简单吧!

这篇关于清华军团推出中国首个对标Sora的视频大模型Vidu,扒一扒它背后的模型架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









