本文主要是介绍面试高频:什么情况下要用到缓存?如何应对缓存穿透、击穿及雪崩?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、为什么要使用内存数据库?
我们先来看一下以往单体的Web系统架构图是什么样的:

从图中可以看出,早期的单体架构基本上是以业务为导向,同时用户群体不是很大,这种单体的架构基本上可以应付大多数使用场景。但随着互联网的推广,用户体量的迅速攀升,响应要求的不断提高,单体架构的系统往往会频繁的出现请求延迟、响应超时或是系统宕机。特别是在数据库层面,更是无法满足高访问量的读写。
为什么会产生这种情况呢?由于数据库的数据是存在硬盘上,硬盘的 I/O 读写瓶颈会直接影响并发量。既然磁盘 I/O 读写时瓶颈,我们是不是可以采用速度更快的内存来存储常用但数据量不算大的数据呢?
为了解决这个问题,目前通用的做法是引入基于内存的数据库,这样的数据库一般是把数据先放到内存里,引入缓存中间件之后的项目 Web 服务架构图如下所示:
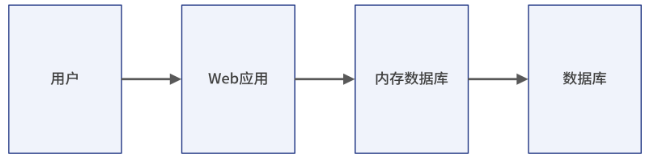
这样便可以较大程度缓解传统数据库带来的磁盘 I/O 读写瓶颈,而我们最常使用的基于内存的数据库就是 Redis 和 MemCached。
二、Redis和Memcached有何区别?
1、存储方式
- Memcached目前只支持单一的数据结构(Key-Value)。类似于java中的Map。
- Redis则支持多种数据结构,如字符串、列表、集合、散列表、集合等。
2、持久化
持久化就是把数据从内存永久存储到磁盘里,可以防止断电等异常情况下数据丢失等问题。目前 Redis 支持持久化,而 MemCached 不支持。遇到灾难,MemCached 无法恢复数据,Redis 可以恢复数据,保证了数据的安全性。但这里也要注意,Redis不是实时去存储数据到硬盘中的,也是根据配置的保存机制来存储的。大家可以在另外一篇文章中去查看Redis的配置。
三、SpringBoot集成Redis
1、导入Redis依赖
在 Maven 中引入 Spring Boot 使用的 Redis 类库,如下代码所示:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>2.4.2</version></dependency>2、获取RedisTemplate
通过注解方式获取 RedisTemplate,如下代码所示:
@Autowiredprivate RedisTemplate<String, String> redisTemplate;3、使用内置的API实现业务数据的缓存读写
@GetMapping("/getRedisTestData")public Result getRedisTestData(){String redisTestListData = null;try {redisTestListData = redisTemplate.boundValueOps("redisTest.findAll").get();//如果redis中没有数据的话if(null == redisTestListData){//查询数据库获得数据List<RedisTest> redisTestList = simulateSceneRepository.findAll();//转换成json格式字符串ObjectMapper om = new ObjectMapper();redisTestListData = om.writeValueAsString(redisTestList);//将数据存储到redis中,下次在查询直接从redis中获得数据,不用再查询数据库redisTemplate.boundValueOps("redisTest.findAll").set(redisTestListData);log.info("从Mysql数据库获得数据");}else{log.info("从redis缓存中获得数据");}} catch (Exception e){log.error("e:{}",e);}return Result.resultSuccess(null,redisTestListData,"数据读取成功");}四、Redis的特性及优缺点
1、Redis特性
(1)主从复制
虽然数据在内存中读写速度比较快,但是在高并发情况下也会产生读写压力特别大的情况,Redis 针对这一情况提供了主从复制功能。
主从复制的好处有如下两点:
-
提供了 Redis 扩展性,当一台 Redis 不够用时,可以增加多台 Redis 作为从服务器向外提供服务;
-
提供了数据备份和冗余服务器,当 Redis 主服务器意外宕机,从服务器可以顶替主服务器向外提供服务,增加了系统的高可用性。
(2)脚本操作
Redis 提供了 lua 脚本操作,你可以将 Redis 存取操作写到 lua 脚本里,然后通过 Redis 提供的 API 来执行 lua 脚本,这样就可以实现 Redis 相关操作。
我们同样可以用 Redis 提供的 API 直接实现 Redis 相关操作,那么为什么有时候又要绕一圈去操作 lua 脚本呢?因为 lua 脚本能够保证操作的原子性,即所有的操作当作一个操作,要么全部失败要么全部成功。而直接使用 API 不一定能保证一连串操作的原子性,所以当需要保证原子性的时候需要使用 lua 脚本。
(3)发布订阅
该特性可以将 Redis 作为消息中间件,在服务端产生消息,然后在客户端消费消息队列里的消息,但是作为消息队列不是 Redis 的强项,所以不推荐使用。比如 Redis 作为消息队列消息并非完全可靠,会产生消息丢失的问题,并且也不支持消息分组。在性能上,如果入队和出队操作频繁,那 Redis 性能比起 RabbitMq 等常用消息队列来说还是有差距的。
2、Redis缺点
(1)缓存穿透
缓存穿透的情况是 Redis 和 MySQL 数据库都没有这条数据,但是用户不断并发发起请求,请求压力会同时落到数据库和缓存上,这样的情况相对于设计初衷来说,对系统的压力就会大很多了,而且这也是黑客发起攻击的手段之一,找寻系统是否存在漏洞。
那在项目中如果遇到缓存穿透我们该如何解决呢?
遇到缓存穿透,我们可以在请求访问缓存和数据库都没查到数据时,给一个默认值或者 Null 值,即 Key-Null。然后该缓存值的有效时间可以设置得短点,比如 30s。在业务代码中判断如果是 Null 值就取消查询数据库,或者间隔 30s 之后重试,这样的方式可以大幅度减轻数据库的查询压力。
(2)缓存击穿
单个数据在缓存中不存在,而在数据库中存在。一般这种情况都是缓存失效导致的,在缓存失效的时间段有大量并发用户访问,首先访问缓存,因为 Key 已经过期了,所以查不到数据,然后所有查询压力都会落到数据库上,造成数据库的压力过大。并且还有可能因为并发问题导致重复更新缓存而过多占用缓存资源。
在项目中如果遇到缓存击穿问题,该如何解决呢?
-
对于一些经常被访问的热点数据,可以根据业务特性主动检查使其 Redis 数据永不过期,当然这样的设置并不代表说这条数据一直不更新而处在 Redis 中,而是根据数据字段中的失效时间和系统时间的对比主动检查更新数据,使 Redis 数据不会过期;
-
通过后台定时刷新,根据缓存失效时间节点去批量刷新缓存数据,这个适合 Key 失效时间相对固定的场景。
(3)缓存雪崩
大量数据在同一时间失效,会造成数据库查询压力过大导致宕机。缓存雪崩与缓存击穿的区别在于缓存击穿是单个数据失效,缓存雪崩是多个数据同一时间失效。
在项目中如果遇到缓存雪崩的问题,我们该如何解决呢?以下 3 种方法可以帮我们解决。
-
如果程序设置的缓存过期时间统一为一个固定的值,比如 5s、10s、15s 等等,那么很有可能出现大量数据在同一时间失效。这个时候我们可以设置不同的过期时间,比如统一时间加上一个随机时间,这样可以让缓存的时间尽量均匀分布一点。
-
不设置过期时间,让程序的定时任务自动定时更新或者清除缓存
-
使用集群化的方式,保证高可用。
文章将持续更新,欢迎关注公众号:服务端技术精选。欢迎点赞、关注、转发。
这篇关于面试高频:什么情况下要用到缓存?如何应对缓存穿透、击穿及雪崩?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





