本文主要是介绍单线程爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Requests介绍与安装
1 Requests介绍:HTTP for humans
是Python的第三方HTTP库,可方便地实现Python的网络连接;
完美替代了Python的urllib2模块;
拥有更多自动化、更友好的用户体验、更完善的功能;
2 安装
在Windows下,执行pip install requests;
在Linux下,执行sudo pip install requests;
3 第三方库安装技巧
3.1 少使用easy_install,因为只能安装不能卸载;
3.2 多使用pip方式安装;
3.3 撞墙怎么办?请戳http://www.lfd.uci.edu/~gohlke/pyhtonlibs/
4 举例
教学视频是根据上述网站下载requests库,但现在没法打开,因此在搜索引擎上搜索查找到requests下载链接:https://pypi.python.org/pypi/requests/
选择“requests-2.10.0-py2.py3-none-any.whl (md5)”进行下载;
修改下载文件的拓展名为.zip,并复制requests文件夹到Python安装目录下的Lib文件夹下即完成安装;
二、第一个网页爬虫
使用requests获取网页源代码,再使用正则表达式匹配出感兴趣的内容,这是单线程简单爬虫的基本原理;
1 使用requests获取网页源代码
1.1 直接获取源代码
#-*-coding:utf8-*-
import requestshtml=requests.get('http://www.nowcoder.com/courses')print html.text但有时通过上述Python程序是无法获取网页源代码,因为有的网页会有反爬虫机制;
1.2 修改HTTP头获取源代码;
import re
import requests# 相当于面具,让访问的网站误以为是浏览器再查看源代码
# 获取User-Agent内容:在该网页右击选择审核元素,切换到Network栏,刷新页面,随便点击一项,在Headers一栏最下方就有相关信息
# hea是字典,键是User-Agent,值就是后面一长串内容
hea={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.152 Safari/537.36'}# 在此处调用hea
html=requests.get('http://jp.tingroom.com/yuedu/yd300p/',headers=hea)# 将编码转为utf-8,否则中文会显示乱码
html.encoding='utf-8'print html.text
2 requests配合正则表达式提取感兴趣的内容:打印该网页中的日文
先获取整个网页源代码;
再查看想要获取的内容的上下文有什么共同点,可以看到想要获取的内容都是以<span style="color:#666666;">开头,以</span></p></li>结尾,中间部分就是带获取内容(.*?);
import re
import requestshea={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.152 Safari/537.36'}html=requests.get('http://jp.tingroom.com/yuedu/yd300p/',headers=hea)html.encoding='utf-8'# print html.textcourse=re.findall('<span style="color:#666666;">(.*?)</span></p></li>',html.text,re.S)for i in course:print i执行结果:
第二章 昔々、といってもせいぜい二十年ぐらい前のことなのだ...
挪威的森林(中日对照) 内容简介: 汉堡机场一曲忧郁的《挪...
藤野先生名文选读中日文对照 東京も格別のことはなかつた。上...
夏目漱石 我是猫(中日对照) 吾輩は猫である 夏目漱石 一 吾輩...
それお皿の絵柄よ 足のケガで中クラスの総合病院に入院しまし...
あるけちん坊(ぼう)な男がおりました。 毎日毎日,ご飯どき...
あるところに,たいへんへそまがりな息子(むすこ)がおりま...
向こうから,お医者(いしゃ)がやってきました。そこへ店(...
お盆休み(ぼんやすみ)に帰ってきた者(もの)同士(どうし...
昔(むかし),三太(さんた)という,ばかな息子がおりまし...
ある日のこと。 そこつ者が,瀬戸物(せともの)屋(や)へ,...
植木(うえき)の大好きな旦那(だんな)がおりました。 ある...
息子が表(おもて)で,凧(たこ)を揚(あ)げておりました...
ある夜(や)のこと,お寺(てら)の庭(にわ)で,小僧(こ...
はくうんしゅうしょく 一匹のトンボが夏の終わりを告げるわけ...
先日、ある研修で聞いた言葉ですが、 「学習」の本質を端的に...
闇夜(やみよ)に,二人の若い男が,こそこそ話しております...
ある役人が誕生日のときに、下役たちは彼が鼠年だと聞き、お...
東京の郊外に住む木村さんは、お酒を飲んでの失敗の多い人で...
ある人が新調した絹の裾/裙(すそ、はかま)を着用して外出...
三、向网页提交数据
1 Get与Post介绍
Get从服务器上获取数据,通过构造url中的参数实现功能;
Post向服务器传送数据,将数据放在header提交数据;
2 分析目标网站
目标网站:https://www.crowdfunder.com/browse/deals
爬取内容:网页的所有公司名称
辅助工具:Chrome浏览器的审核元素中Network功能
核心方法:requests.post
核心步骤:构造表单 -> 提交表单 -> 获取返回信息
1‘ 打开网站,点击查看网页源代码,这是网页爬虫的必要习惯!
在源代码中,可先用公司名称搜索其在源代码中的位置,如公司名称MYFORCE在源代码位置如下:

公司名称可使用正则表达式"card-title">(.*?)</div>进行匹配,此时可匹配到19个公司名称;
2‘ 在网站正下方点击SHOW MORE按钮,出现更多公司信息(以追加形式);
值得注意的是,此时网站网址仍是https://www.crowdfunder.com/browse/deals,说明该网站使用异步加载技巧;
(异步加载,指先加载网页基本框架,对于剩下的信息,需要哪里就加载哪里,提高网页加载效率)
重新打开网站源代码,搜索"card-title">,发现仍然是19,说明后面加载的公司信息在源代码中无法找到;
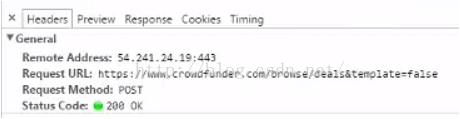
3' 使用Chrome的审核元素中Network功能,当前没有任何信息;点击SHOW MORE按钮,出现信息,点击第一条:
在General项,请求方法是Request Method: POST,说明使用POST向网页提交数据;
提交地址是https://www.crowdfunder.com/browse/deals&template=false
在Form Data项,页数是Page: 2,说明构造Form Data向网页进行提交,可以得到想要的信息;

4‘ 打开Pycharm,
#-*-coding:utf8-*-
import requests
import re
url='https://www.crowdfunder.com/browse/deals&template=false'
data={ # 字典,有2个元素,构造Form Data'entities_only':'true','page':'1' # 可修改页数值
}
html_post=requests.post(url,data=data)
title=re.findall('"card-title">(.*?)</div>',html_post.text,re.S)
for each in title:print each结果执行:
MYCROWD QA
DIGITZS
GOCOIN
SANTO DIABLO MEZCAL
RAGEON!
SELFIE WITH ME
四、实战——极客学院课程爬虫
1 目标网站
http://www.jikexueyuan.com/course/
2 目标内容
前20页的课程名称、课程介绍、课程时间、课程等级、学习人数
3 涉及知识
requests获取网页、re.sub换页、正则表达式匹配内容
4 抓取关键步骤
1’ 打开网站,首页网站为http://www.jikexueyuan.com/course/;点击下一页后,第2页网站为http://www.jikexueyuan.com/course/?pageNum=2;
则首页网站也可以是http://www.jikexueyuan.com/course/?pageNum=1;
2‘ 首先点击审核元素中放大镜图标,将鼠标箭头放在第一个课程的名称处,审核元素就会自动定位到当前源代码相应位置,在其附近也可找到课程介绍、时间、等级和学习人数对应的源代码位置;
3’ 采用先抓大后抓小的原则。对于先抓大,在审核元素中,每个课程信息都是在标签<li id="和标签</li>之间,可以使用re.findall()匹配出所有课程信息并保存在列表中;对于再抓小,对列表进行遍历,每个课程信息进行细划分,如下:
课程名称在标签class="lessonimg" title="和标签" alt=之间;
课程介绍在标签display: none;">和标签</p>之间;
课程时间在标签<em>和标签</em>之间;
课程等级在标签<em>和标签</em>之间;
学习人数在标签"learn-number">和标签</em>之间;
其中,对于相同的标签标识,可使用re.findall()匹配出2个符合要求的元素,课程时间在列表的第一个元素,课程等级在列表的第二个元素;
5 编写程序——从小到大功能实现
5.1 实现单页的课程信息爬取
#-*-coding:utf8-*-
import requests
import reimport sys
reload(sys)
sys.setdefaultencoding("utf-8")url='http://www.jikexueyuan.com/course/?pageNum=1'html=requests.get(url).text
course=re.findall('(<li id=".*?</li>)',html,re.S)
info={}for each in course:info['title']=re.search('class="lessonimg" title="(.*?)" alt=',each,re.S).group(1)info['detail'] = re.search('display: none;">(.*?)</p>', each, re.S).group(1)temp=re.findall('<em>(.*?)</em>',each,re.S)info['date']=temp[0]info['class']=temp[1]info['number']=re.search('"learn-number">(.*?)</em>',each,re.S).group(1)f = open('info.txt', 'a')f.writelines('title: '+info['title']+'\n')f.writelines('detail: ' + info['detail'] + '\n')f.writelines('date: ' + info['date'] + '\n')f.writelines('class: ' + info['class'] + '\n')f.writelines('number: ' + info['number'] + '\n\n')f.close()
5.2 实现20页的课程信息爬取
#-*-coding:utf8-*-
import requests
import reimport sys
reload(sys)
sys.setdefaultencoding("utf-8")url='http://www.jikexueyuan.com/course/?pageNum=1'cur_url=int(re.search('pageNum=(\d+)',url,re.S).group(1))
page_group=[]
for i in range(1,21):links=re.sub('pageNum=\d+','pageNum=%s'%i,url,re.S)page_group.append(links)for link in page_group:print u'正在处理页面:'+linkhtml=requests.get(link).textcourse=re.findall('(<li id=".*?</li>)',html,re.S)info={}for each in course:info['title']=re.search('class="lessonimg" title="(.*?) alt=',each,re.S).group(1)info['detail'] = re.search('display: none;">(.*?)</p>', each, re.S).group(1)temp=re.findall('<em>(.*?)</em>',each,re.S)info['date']=temp[0]info['class']=temp[1]info['number']=re.search('"learn-number">(.*?)</em>',each,re.S).group(1)f = open('info.txt', 'a')f.writelines('title: '+info['title']+'\n')f.writelines('detail: ' + info['detail'] + '\n')f.writelines('date: ' + info['date'] + '\n')f.writelines('class: ' + info['class'] + '\n')f.writelines('number: ' + info['number'] + '\n\n')f.close()
5.3 实现使用类的课程信息爬取
#-*_coding:utf8-*-
import requests
import re# Windows下默认编码是GBK,网页默认编码是utf-8,编码不匹配易导致爬取内容乱码
import sys
reload(sys)
sys.setdefaultencoding("utf-8")class spider(object):def __init__(self):print u'开始爬取内容。。。'#getsource用来获取网页源代码def getsource(self,url):html = requests.get(url)return html.text#changepage用来生产不同页数的链接def changepage(self,url,total_page):now_page = int(re.search('pageNum=(\d+)',url,re.S).group(1))page_group = []for i in range(now_page,total_page+1): # 左闭右开link = re.sub('pageNum=\d+','pageNum=%s'%i,url,re.S)page_group.append(link)return page_group#geteveryclass用来抓取每个课程块的信息def geteveryclass(self,source):everyclass = re.findall('(<li id=.*?</li>)',source,re.S)return everyclass#getinfo用来从每个课程块中提取出我们需要的信息def getinfo(self,eachclass):info = {} # 字典info['title'] = re.search('lessonimg" title="(.*?)" alt',eachclass,re.S).group(1)info['content'] = re.search('display: none;">(.*?)</p>',eachclass,re.S).group(1)timeandlevel = re.findall('<em>(.*?)</em>',eachclass,re.S)info['classtime'] = timeandlevel[0]info['classlevel'] = timeandlevel[1]info['learnnum'] = re.search('"learn-number">(.*?)</em>',eachclass,re.S).group(1)return info#saveinfo用来保存结果到info.txt文件中def saveinfo(self,classinfo):f = open('info.txt','a')#追加方式打开for each in classinfo:f.writelines('title:' + each['title'] + '\n')f.writelines('content:' + each['content'] + '\n')f.writelines('classtime:' + each['classtime'] + '\n')f.writelines('classlevel:' + each['classlevel'] + '\n')f.writelines('learnnum:' + each['learnnum'] +'\n\n')f.close()#####程序入口
#如果是程序自己使用jikexueyuan.py,则__name__的值是__main__
if __name__ == '__main__':classinfo = [] # 空列表,用以保存课程信息url = 'http://www.jikexueyuan.com/course/?pageNum=1'jikespider = spider() # 实例化spider()类all_links = jikespider.changepage(url,20)for link in all_links:print u'正在处理页面:' + linkhtml = jikespider.getsource(link)everyclass = jikespider.geteveryclass(html)for each in everyclass:info = jikespider.getinfo(each)classinfo.append(info)jikespider.saveinfo(classinfo)
6 涉及知识点总结
6.1 修改默认编码
Windows默认编码是GBK,网页默认编码是UTF-8,需设置默认编码,否则易导致爬取内容乱码;
注意:在设置前必须对sys模块进行reload;
import sys
reload(sys)
sys.setdefaultencoding("utf-8")6.2 __name__内置属性
如果import一个模块,则模块的__name__的值为模块文件名,不带路径或文件扩展名;
如果直接执行当前文件,则__name__的值为__main__。
6.3 类的定义和实例化
6.4 re.search(pattern, string, flag)方法
pattern为匹配的正则表达式,string为要匹配的字符串,flag为标志位;
匹配整个字符,只提取第一个符合要求的内容,返回一个正则表达式对象;
使用匹配对象函数group(n)获取第n个匹配字符串,或group()获取整个字符串;
6.5 re.findall(pattern, string, flag)方法
匹配所有符合要求的内容,结果以列表形式返回;
可使用下标对列表元素进行访问;
6.6 re.sub(pattern, repl, string)方法
pattern为匹配的正则表达式,repl为替换的正则表达式,string为要匹配的字符串;
如re.sub('123(.*?)','123%d'%123,s)表示将123后面的字符串替换成123,这里的%d可以是任何一个字母;
6.7 正则表达式\d+
\d表示[0-9]
\l表示[a-z]
\u表示[A-Z]
\w表示[a-zA-Z0-9]
\s表示任意空白字符
上述大写形式表示其相反意义,如\D表示非数字字符
+表示有多个,如\d+表示至少有1个、最多不限制的数字串
^表示以其后紧跟的字符类型开头,如^[0-9]表示以数字字符为开头,注意:[^0-9]表示非数字字符
$表示以其前紧跟的字符类型结尾
6.8 文件I/O
用file对象实现文件操作;
a 打开:open()方法
file_object=open(file_name[, access_mode]);
file_name表示要访问的文件名的字符串值,access_mode表示打开文件模式:只读r、写入w、追加a等;
b 关闭:close()方法
刷新缓存区重任何还没写入的信息,并关闭该文件;
file_object.close();
c 写:
write()方法:
file_object.write(string);
将任何字符串写入一个打开的文件;
writelines()方法:
file_object.writelines(sequence);
将序列以迭代形式写入一个打开的文件;
d 读:
read()方法:
string=file_object.read([len]);
从打开的文件中读取一个字符串,默认读到文件末尾,否则读取前len个字符,以字符串形式返回;
readline()方法:
string=file_object.readline();
从打开的文件中读取整行,包括换行符,以字符串形式返回;
sequence=file_object.readlines();
从打开的文件中读取所有行,以列表形式返回;
---------------------------------------------------------------
课程总结:
1 requests获取网页源代码
2 修改http头绕过简单的反爬虫机制
3 向网页提交内容
这篇关于单线程爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









