本文主要是介绍合合信息Embedding模型获得MTEB中文榜单第一,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近几年,可以说大语言模型汇聚了所有的光彩,大语言模型的飞速发展更是吸引着社会各界的目光,这些模型的强大能力源自于Embedding技术的支撑,这种技术将语言转化为机器可理解的数值向量。随着大型语言模型的不断突破,Embedding模型的关键性日益凸显,成为推动人工智能领域向前发展的核心动力。在这个充满无限可能的领域中,每一次技术的飞跃都预示着新的变革和机遇。 近期,合合信息发布了文本向量化模型acge_text_embedding(简称“acge模型”),获得MTEB中文榜单(C-MTEB)第一的成绩,相关成果将有助于大模型更快速地在千行百业中产生应用价值。
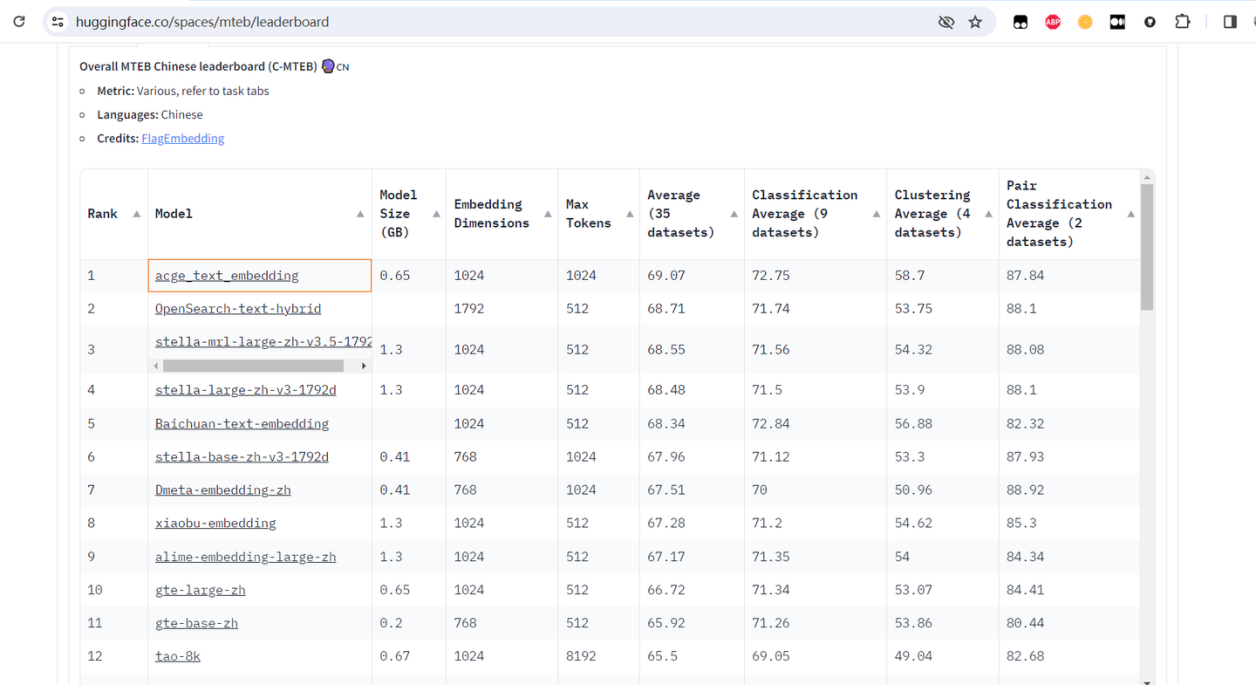
榜单第一是合合信息的acge模型
1、什么是MTEB
MTEB(Massive Text Embedding Benchmark)是衡量文本嵌入模型(Embedding模型)的评估指标的合集,是目前业内评测文本向量模型性能的重要参考。
而文本向量化模型是自然语言处理(NLP)中的一项核心技术,对应的Embedding模型能够将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,捕捉到数据的语义特征和关系,被广泛应用于搜索、推荐、问答、检索增强生成、数据挖掘等领域。互联网时代中,随着信息量急剧膨胀,人们接触信息的渠道不断拓展,大量无关的信息已成为信息检索的干扰项,Embedding模型能够显著提高信息搜索和问答的质量、效率和准确性,让搜索和问答引擎不再只是匹配文字,而是可以真正理解人的意图。如下图所示,文本向量化模型通过将“生活日常知识”转换为数值向量,可以将文本信息表示成能够表达文本语义的向量。

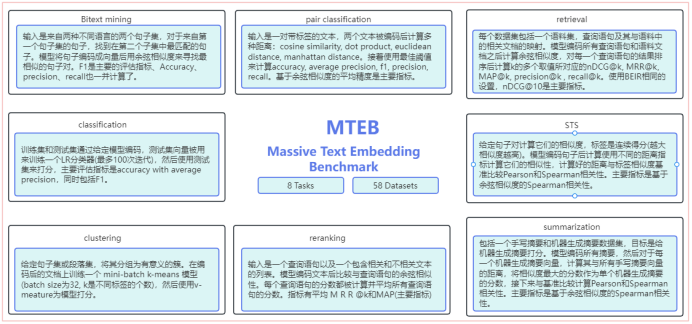
MTEB的目的是为了评估向量模型在不同向量任务上的表现,希望作为寻找适用于不同任务的通用文本向量的入口。在论文里说包括涵盖112种语言的58个数据集,针对如下8种任务:

2、C-MTEB
MTEB则是专门针对中文文本向量的评测基准,被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。阿里、腾讯、商汤、百川等多家厂商在此榜单测评发布模型。而本次合合信息上榜的acge模型也能够很好的处理一些需求:如文本分类、语义相似度计算、情感分析等。
文本分类:使用已经预训练好的Embedding模型来提取文本特征,并通过分类器(如SVM、LR等)对文本进行分类。例如,对于CSDN上的文章,我们可以使用Embedding技术将文本转换为向量,然后利用分类器判断文章的类别(如人工智能、微服务、嵌入式等)。
语义相似度计算:通过计算两个文本的Embedding向量之间的余弦相似度来判断它们之间的语义相似度。例如,在搜索引擎中,当用户输入一个查询词时,我们可以使用Embedding技术计算查询词与库中各个文档的语义相似度,从而返回最相关的文档。
情感分析:利用Embedding技术将文本转换为向量,然后利用机器学习算法(如SVM、神经网络等)对文本进行情感分析,判断文本的情感倾向(如正面、负面、中性)。
3、中文海量文本embedding任务排行榜:C-MTEB
从 Chinese Massive Text Embedding Benchmark 中可以看到目前最新的针对中文海量文本embedding的各项任务的排行榜,针对不同的任务场景均有单独的排行榜。此次合合信息的acge模型,荣获的就是C-MTEB榜单的第一。
3.1、max tokens
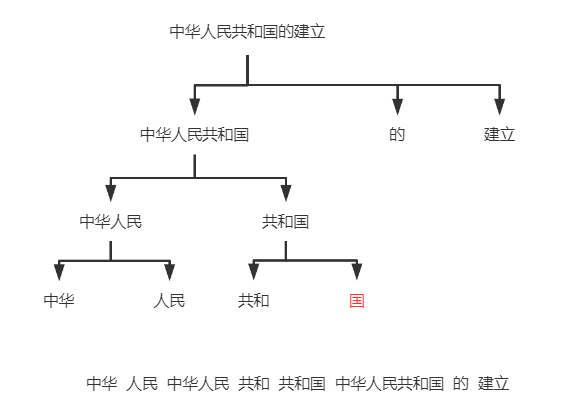
token是什么呢?在自然语言处理中,token通常指对文本进行分割和标记后得到的最小单元。这个最小单元可以是单词、子词、字符或者其他更小的单元。
例如下面的例子,一个短句可以分词成单个的字、词语、字句等。
3.2、文本聚类指标
聚类(clustering)是无监督学习(unsupervised learning)中研究最多、应用最广的技术之一,其基本思路是通过对无标记训练样本的学习来揭示数据内在的聚合性质与规律。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇(cluster),每个簇可能对应于一些潜在的概念(类别),但这些概念的语义需由开发者来把握和命名。
3.3、acge模型的特点
3.3.1、5种模型对比分析
acge模型居于MTEB中文榜单(C-MTEB),那么我们拿它与其他前5的模型对比一下,看看这五个模型的区别。
第一名:acge_text_embedding
- Token:acge模型支持最大1024 tokens,可以满足大多数场景的分词需求;
- 模型大小:0.65GB,模型较小,占用资源少,又便于部署和维护;
- 分类任务性能: acge的平均准确率(Average)为69.07%,在所有模型中排名最高;
- 向量维度:模型输入文本长度为1024,可以有效的输入更丰富的信息。
第二名:OpenSearch-text-hybrid
- Token:OpenSearch模型支持最大512 tokens,没有acge模型拆分文本细致;
- 分类任务性能: 平均准确率为68.71%,聚类任务性能也表现不错,但整体上不如acge。
第三名:stella-mrl-large-zh-v3.5-1792
- Token:stella-mrl-large模型支持最大512 tokens,没有acge模型拆分文本细致;
- 模型大小: 较大的模型 1.3GB,是acge模型的2倍,会导致更高的计算和存储需求。
- 分类任务性能: 平均准确率为68.55%,聚类任务性能也表现不错,但整体上不如前2个模型。
第四名:stella-large-zh-v3-1792d
- Token:stella-large模型支持最大512 tokens,没有acge模型拆分文本细致;
- 模型大小: 较大的模型 1.3GB,是acge模型的2倍,会导致更高的计算和存储需求。
- 分类任务性能: 平均准确率为68.48%,聚类任务性能也表现不错,但整体上不如前3个模型。
第五名:Baichuan-text-embedding
- Token:OpenSearch模型支持最大512 tokens,没有acge模型拆分文本细致;
- 分类任务性能: 平均准确率为68.34%,聚类任务性能也表现不错,但整体上不如前4个模型。
3.3.2、acge模型优势分析
与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型较小,占用资源少,聚类分数也比较高,支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
例如在企业管理、市场营销、医疗、电商、金融、教育、社交网络、旅游等领域都可以产生广泛的应用。
电商领域领域预测
由于acge模型的上述特点,可以用于电商领域,对比现在的推荐系统,在单位时间内,可以处理更多的文档信息,利用相似度分析,也可以更快速的响应推荐结果。
在用户层的感受,就是比以往的推荐更多精准,更加迅速,而且在618、双11等电商节,能同时容纳更多的用户个性推荐。

教育医疗领域的分析
当代社会各种病毒释虐、天气异常,小孩子成了流感的重灾区,传播十分迅速。acge模型可以对这些医疗数据进行实时的分类和聚类分析,将流感分为病毒、天气、肺炎等不同类别,并对每个类别中的医疗数据进行聚类,以识别主要的人群和关注人群。
比如某个地区肺炎流感患者集中爆发,可以根据患者地理位置以及流动位置信息,为当地的小学、幼儿园提供预警,及时的做消杀卫生,拉起警戒线,防止病毒浸入校园。
4、实战演练
下面我们可以从acge_text_embedding模型入口(https://huggingface.co/aspire/
acge_text_embedding)进入,可以在线演练acge模型的效果。
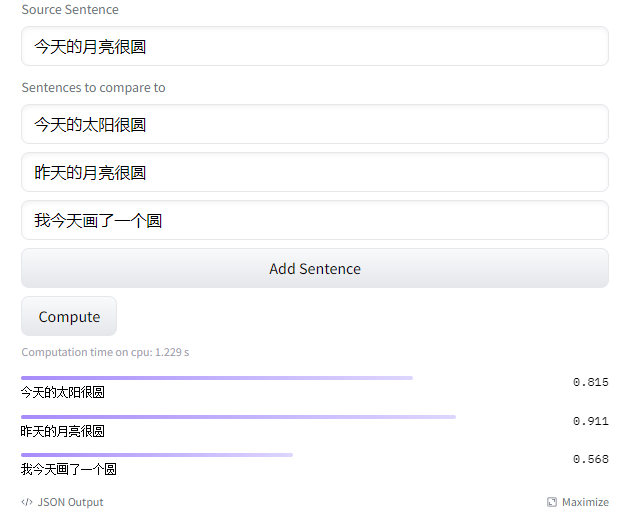
案例里,原文本是:“今天的月亮很圆”。“昨天的月亮很圆”相似度是最高的,“今天的太阳很圆次之”,“我今天画了一个圆”相似度很低,只有0.568分。
再次增加一个“我经常去海底捞吃火锅”,可以看到只有0.255分,相似度非常低了。

4.1、通过代码实现
在sentence-transformer库中的使用方法:
from sentence_transformers import SentenceTransformersentences = ["数据1", "数据2"]model = SentenceTransformer('acge_text_embedding')print(model.max_seq_length)embeddings_1 = model.encode(sentences, normalize_embeddings=True)embeddings_2 = model.encode(sentences, normalize_embeddings=True)similarity = embeddings_1 @ embeddings_2.Tprint(similarity)在sentence-transformer库中的使用方法,选取不同的维度:
from sklearn.preprocessing import normalizefrom sentence_transformers import SentenceTransformersentences = ["数据1", "数据2"]model = SentenceTransformer('acge_text_embedding')embeddings = model.encode(sentences, normalize_embeddings=False)matryoshka_dim = 1024embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensionsembeddings = normalize(embeddings, norm="l2", axis=1)print(embeddings.shape)# => (2, 1024)结语
合合信息是一家人工智能及大数据科技企业,基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。
欢迎各位感兴趣的朋友访问 合合信息旗下的OCR云服务产品——TextIn的官方网站,了解更多关于智能文字识别产品和技术的信息,体验智能图像处理、文字表格识别、文档内容提取等产品,更多惊喜等着你哦,快来试试吧:合合信息TextIn智能文字识别产品(https://www.textin.com/)
这篇关于合合信息Embedding模型获得MTEB中文榜单第一的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









