本文主要是介绍走进头条数据中心:高速扩张背后的“硬”实力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说起“字节跳动”可能大多数人都不知所云,但如果说“今日头条”或者“抖音”你一定非常熟悉。今日头条和抖音只是字节跳动公司旗下两款最为人所熟知的产品,其他产品还包括西瓜视频、火山小视频以及悟空问答等等。
抖音,这个突然在今年火爆起来的App已经成为诸多年轻人打发时间的首选。“刷抖音”这句时髦词的后背是字节跳动令人惊艳的成绩:最新数据显示,抖音在8月的日均视频播放量超过10亿次,日均活跃用户数超过1.5亿,月度活跃用户数超过5亿。
视频上传需要存储,并进行合规性检查;视频播放需要编解码,这需要消耗大量的计算资源;用户体验需要恰当的推荐系统与CDN……等等,这些都对抖音背后的IT系统带来了前所未有的挑战。据数据显示,字节跳动在2017年初的时候只有2~3万台服务器,而今年服务器数量一下猛增到17万台。
这也使得其原有的数据中心租赁模式彻底不可行,必须自建数据中心,且速度要快。仅7个月时间,字节跳动就在怀来拥有了第一个属于自己的数据中心,一系列新技术的采用让这个数据中心拥有多项头衔:国内首个大规模分布式全预制、国内首个大平层预制框架结构、国内首个整体电源模块预制、国内首个间接蒸发自然冷却模块、国内首个计算模块一体化预制。
“数字中国万里行”的第三站,我们来到了这个目前国内用时最短而构建起来的数据中心,揭开字节跳动迅猛发展背后的秘密。

先看一段视频,数字中国万里行团队带你走进头条数据中心,体验身临其境的感觉:
技术驱动 七个月提前交付
字节跳动首个已经交付使用的数据中心坐落在怀来官厅湖新媒体产业园。怀来是新能源输出大县,70%以上的电能都是水力发电、风能发电和太阳能发电产生的清洁能源,但这之中有50%的清洁能源无法上网,低廉的电价对于数据中心这种耗电大户而言,具有莫大的吸引力。
而且,怀来年均气温只有6.5度,空气质量也好,利用新风散热有助于降低数据中心的PUE值,有效降低数据中心的运营成本。高效应用自然冷却技术,也是官厅湖新媒体产业基地的一大特点,也是首个规模使用间接新风制冷技术的数据中心产业基地。

字节跳动首个已经交付使用的数据中心一期工程,5万台服务器已经入驻
字节跳动最初规划首个数据中心将在9个月内完成,而得益于新媒体产业基地采用的大平层预制建筑结构整体规划,再加上为了追求快速建设以满足字节跳动服务器规模高速增长需求,字节跳动采用了一系列新锐技术,如大规模分布式全预制、整体电源模块预制、间接蒸发自然冷却模块、计算模块一体化预制等等技术,让一期数据中心在7个月内就完成交付使用。

字节跳动数据中心采用大量预制和模块化产品,体现了数据中心高度模块化的未来发展趋势。钢平台底座、变压器、配电柜、UPS设备均采用在原厂设计、安装和调试在20天内分批交付,二次系统连接、监控系统集成和电源模块测试可以在7天内完成,由40尺集装箱整体运输到现场,施工现场只需连接电缆,拼装调试即可交付使用,这个过程需要十天左右。这一系列的细节时间控制,让字节跳动数据中心刷新了国内数据中心建设交付的最短时间记录。
据字节跳动技术总监王剑介绍,2017年12月字节跳动开始在怀来数据中心放置服务器,目前一期园区约5万台服务器已经投入使用,正在紧邻一期园区建设二期,规模增加一半但预计工期相同,大概能容纳9万台服务器。
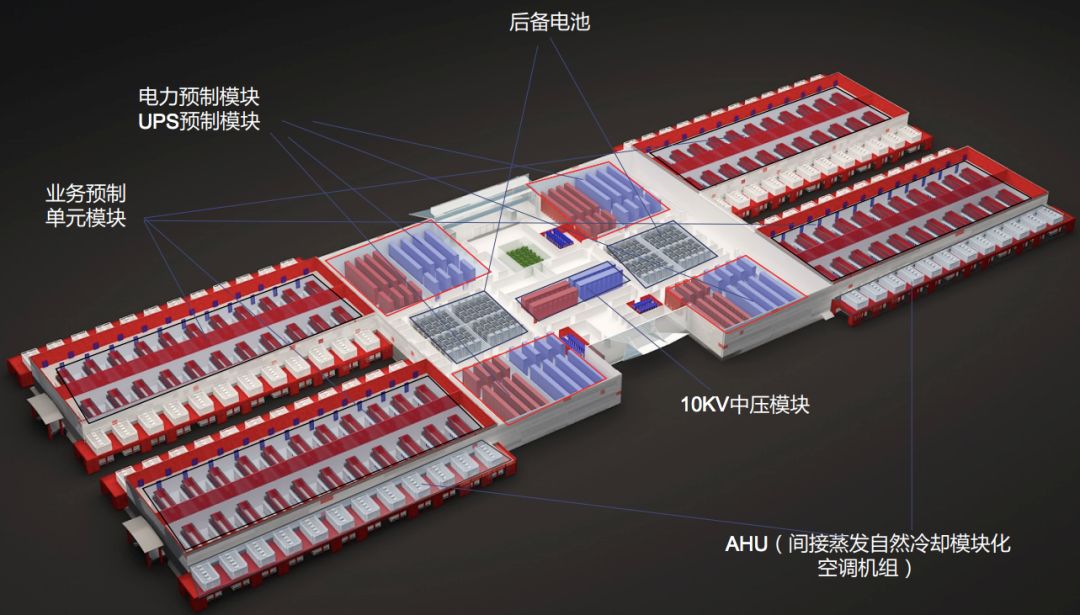
字节跳动预制件与模块化建设数据中心示意图
数据驱动基础设施创新
大多数人对“今日头条”的印象似乎都是一家泛媒体平台,但字节跳动则认为自己是一家AI(即人工智能)公司,因为不管是今日头条也好,抖音也好,字节跳动很少自己生产内容,而是鼓励用户进行创作,并把用户创作的内容推荐给最适宜的用户群体。
所以字节跳动最核心的系统实际包括头条推荐系统与广告系统、评论系统,以及内容合规性审核系统,这背后实际上就是AI技术在不同领域或场景的应用。
比如在在推荐系统里面最核心的就是内容推荐算法。用AI去做推荐,是字节跳动重要战略,目前也是应用最广的技术,不管是今日头条还是抖音等产品,AI都在里面发挥着重要作用。使用AI进行推荐,需要大量的数据进行训练才能达到更好的效果,据介绍,仅今日头条一款产品30天的训练模型,其数据量就会超过4PB,而正常训练一个完整的模型则需要至少一年的数据量。而在视频的合规性审核方面,字节跳动不但使用计算机视觉技术对视频图像进行分析,同时利用语音识别技术对音频进行合规性分析。而这些技术的大规模应用会对系统的基础设施带来极大的挑战,比如计算能力、网络带宽以及存储性能等等。
随着字节跳动数据中心规模的扩大,服务器数量的高速增长,为了最大化资源利用率,字节跳动与Intel公司成立了创新实验室,全部采用Intel最新的可扩展处理器平台,并根据不同应用场景对软件堆栈进行深层次优化。据介绍,成果非常显著,能够实现大约30%的能力提升,更好的资源利用率意味着更好的购置成本和运营成本节省。
并且,不管是推荐系统,还是审核系统,其每天都会处理海量的数据,这对底层存储系统的性能有着苛刻的需求,SSD已经成为字节跳动的必然选择。但并不是说使用SSD就能直接解决问题,尤其NVMe SSD使用,通常会给计算、网络系统带来直接的压力,将原本存储的性能瓶颈转移到计算或者网络。
为了提升整体系统的综合性能表现,还需要站在更高层次对各个子系统进行系统性优化,比如在与Intel的合作中,双方共同针对人工智能、Cascade Lake,最新64层Nand存储技术,高速网络的产品以及FPGA在不同系统中应用进行了探索,并与DPDK、SPDK、BigData以及OS kernel等软件层的优化相结合,取得了极大的进展,获得了极为显著的成功。
字节跳动所取得的辉煌成绩不仅意味着中国互联网市场的巨大潜力,同时也意味着中国数据中心技术的飞速发展正逐步接近国际领先水平。
跟着新至强特快专列的先遣队伍,走进中国最先进的数据中心,快戳“阅读原文”!

这篇关于走进头条数据中心:高速扩张背后的“硬”实力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







