本文主要是介绍提速20倍!3个细节优化Tableau工作簿加载过程(附实例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Jeffrey A. Shaffer;翻译:张玲;校对:丁楠雅;
本文约3000字,建议阅读10分钟。
本文为你简要介绍快速加载Tableau工作簿的技巧,以优化其性能。
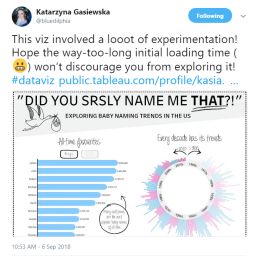
Katarzyna "Kasia" Gasiewska的Tableau Public主页上经常有一些精彩的可视化作品,她拥有100多位粉丝,如果你没有位列其中,那么你遗憾地错过了不少作品。
她在Twitter上发表的第一部可视化作品是她最近参加Iron Viz大赛的入选作品《Water, Water Everywhere》,所以当她上周发布新作品的时候,就立即引起了我的注意。这部作品叫《DID YOU SRSLY NAME ME THAT?》,是上周五的Tableau Viz。
《Water, Water Everywhere》:
https://public.tableau.com/profile/kasia.gasiewska.holc#!/vizhome/Watereverywhere/WaterFootprint
《DID YOU SRSLY NAME ME THAT?》:
https://public.tableau.com/profile/kasia.gasiewska.holc#!/vizhome/USBabyNames_4/BabyNames
我在看到作品图片时就立刻被牢牢吸引住,在最终点开作品链接前,我注意到她的推文里写到“初始加载时间太长太长”。当打开作品时,我立刻对她的痛苦感同身受。
仔细观察Viz
除了漫长的加载时间(我在Tableau Public上加载它花费了超过一分钟的时间),点击男孩/女孩名字也需要很长的时间才能筛选。但当我仔细观察时,我发现并没有任何太复杂的东西,只有一个条形图、一个径向条形图和一个点图而已。
所以,我决定下载整个工作簿一探究竟。这时,疼痛值明显增加,如果找一位医生按1到10等级评定疼痛,这肯定是很高级别的疼痛了。它在Tableau Public上加载和交互的速度就够慢了,当下载下来,想真的尝试拖拉拽操作以改变作品时,我的疼痛值很快达到最高级别。
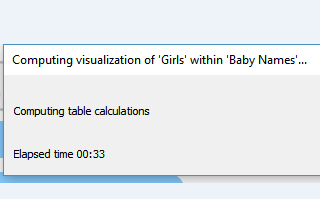
这时候,我非常同情Kasia,因为我知道她在设计这样一个作品时非常煎熬。可以想象当她调整形状、颜色、slider大小,或者作出其他任意改动时,每一步都必须等待,眼睁睁看着时间一分一秒的过去,直到Viz作品更新完毕为止。
后来,我们交流了一下,她也已经更新了她的作品,但我仍决定写这篇文章来介绍一下我为帮助她提升可视化作品加载速度所做的事情,并为那些无法摆脱这种糟糕速度的人提供一些链接和资源。
如果你想亲自体验一下,可以在这里下载她的原始工作簿:
工作簿:
https://dataplusscience.com/files/US%20Baby%20Names%20Original.twbx
分析工作簿
关于“如何优化Tableau工作簿”,会有很多资源介绍。即使你从未遇到过这类性能问题,我也鼓励你阅读一点有关这个主题的内容。从长远来看,只需了解一些注意事项和技巧就可以节省大量时间。
以下是我为改进此工作簿所做的一些事情,请注意,这个工作簿还可以进一步优化。Kasia做了这些改进,并结合其他一些改进,现在她的作品要比原来的版本快得多,具体改进如下:
文件中有一个未使用的额外数据源。
这很容易解决,右击数据源,然后选择关闭。如果你不确定它是否正在使用,请不要担心,Tableau会在关闭正在使用的数据源之前发出警告。这样,TWBX文件大小几乎会减少一半。
数据量有180万行,但大部分都未在可视化中用到。
在这个作品中,细节最详细的是点图,它显示了1990年至2014年男孩和女孩最流行的Top10名字。这意味着,我们在用180万行数据来显示2,300行数据(115年(1900-2014)*10(Top 10)*2(男孩/女孩))。冗余数据太多了,我们需要将数据减少到真正需要的量。这样才会大大提高工作簿的加载速度!
过程中进行了大量的计算。
首先,对每个名字进行计数求和,接着用另一个计算来对该计数的总和进行排名,然后是采用两个计算来算出用于显示男孩/女孩名字集合的大小和形状。这四个计算具有复杂的if-then-elseif-then-elseif-then-else-end结构,而且还包含很多OR语句。此外,这些计算的结果是一个字符串,例如“Size1”和“Size2”。
解决这些问题
我在Tableau Performance上看到的最好资料是Alan Eldridge撰写的白皮书,它是一本只有88页的迷你书,但涵盖了优化Tableau工作簿性能所需的广泛主题,是一个让人惊艳的资源!如果你想提升你的工作簿性能,你必须阅读它:
白皮书链接:
https://www.tableau.com/learn/whitepapers/designing-efficient-workbooks
以下是Alan白皮书的摘要点:
1. 改进低效工作簿没有灵丹妙药。从观察性能记录器开始,了解时间进展。是否有长时间查询?查询太多?计算慢?绘制复杂?这种洞察力可以确保你的努力方向是正确的。
2. 本书的建议仅供参考。虽然它们代表了最佳实践水平,但你仍需要测试它们是否会在特定情况下提高性能。其中许多建议依赖于数据结构和正在使用的数据源(例如,flat file或者RDBM或数据提取)。
3. 数据提取是一种快速简便的方法,可以使大多数工作簿运行的更快。
4. 数据越干净,和问题的结构越匹配,你的工作簿也会运行的越快。
5. 大多数慢的仪表盘都是由设计不佳引起的,特别是图表过多或者试图同时显示很多数据的仪表盘。让仪表盘简单一点吧!允许你的用户逐步向下钻取,了解细节信息,而不是尝试一下子显示所有内容,然后再进行筛选。
6. 仅使用你需要的数据,包括引用的字段和返回记录的粒度。这不仅可以使Tableau生成更少、更好、更快的查询,减少从数据源传输到Tableau引擎的数据量,还可以减少工作簿的大小,以便轻松分享和快速打开。
7. 在缩减数据的同时,请确保有效地使用筛选器。
8. 字符串和日期很慢,数值和布尔值很快。
让我们把其中一部分技术应用到Kasia的工作簿,看能否够提升这部可视化作品的加载速度。
仅使用你需要的数据
在继续之前,让我们来查阅一下Tableau 的操作顺序。
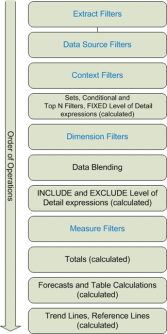
来源:https://onlinehelp.tableau.com/current/pro/desktop/en-us/order_of_operations.html
以下是Kasis对列和行进行计算的度量值以及她所用的筛选器:
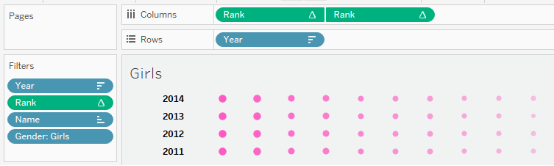
先使用Year和Gender筛选器,接着对Sales的求和进行排序。不幸的是,这些筛选器只把180万行数据减少到1,052,480行。接下来对计数值进行求和,然后对求和值排序,最后再把筛选器应用到排序上。换句话说,求和和排序计算是在维度筛选之后的100万条记录上进行的。这并不是必要的,因为我们只需要很少的数据来创建视图。
Alan写道,“仅使用你需要的数据”,这是非常棒的建议。这个工作簿有180万行数据,而在细节粒度最小的视图中也只用了2300行数据。理想情况下,我们会将数据减少到所需要的量,而不是使用整个数据集。接下来,我将使用数据源筛选器这种快速简便的方法来减少数据量。
请注意,在Tableau的操作顺序中,数据源筛选器(和提取筛选器)需要在其他类型筛选器之前应用,远在其他计算之前。因此,利用它可以真正地加快工作簿的加载速度。在Kasia Viz作品中,我用了2个快速简便的数据源筛选器:
Year筛选器
数据集最早的年份是1880年,但Kasia仅使用1900至2014年的数据,筛选“至少1900年”,将删除56,000条未在分析中使用的记录。
Count筛选器
这很重要,每个男孩/女孩的名字每年都有一个计数,这个计数用来确定每年的Top 10。使用的最低计数是1906,通过添加最低计数1906的数据源筛选器,可以删除未使用的180万行数据。
应用这两个数据源筛选器,可以将数据集从1,825,433行减少到24,130行。尽管这20,000条数据仍然比我们需要的多,但已经可以快速简便地筛掉冗余数据,加速底层计算。实际上,仅凭这一点,就可以使Tableau Public上的Viz作品更加可用。
字符串/日期 VS 数值/布尔值
来自Alan下一个非常有用的,有助于提升工作簿性能的提示是“字符串和日期很慢,数值和布尔值很快”。
这是一个不相关的例子。我们可以使用布尔输出,而不是使用IF语句将高亮颜色指定为字符串。
将高亮颜色指定为字符串:
IF [State] = [State Parameter] then "Blue"
ELSE "Gray"
END
将高亮颜色指定为布尔值:
[State] = [State Parameter]
请注意,在这种情况下,布尔值是一个更优雅的解决方案,它将在大数据集上表现更好。
Kasia的工作簿对复杂的IF语句进行了一些计算,这些语句输出到一个字符串(而且是在一百万条记录上计算它们)。我们不能使用布尔解决方案进行Kasia的计算,但是,我们可以通过将它们转换为数字来更快地进行这些计算。
Kasia将Size作为字符串的原始计算:
if [Circles - Boys]=0 then "Size1"
ELSEIF [Circles - Boys]=1 OR [Circles - Boys]=2 OR [Circles - Boys]=4 then "Size2"
ELSEIF [Circles - Boys]=3 then "Size3"
else "Size4" end
以下是一个获得相同结果的改进计算,但它输出一个数字而不是字符串:
case [Circles - Boys]
when 0 then 1
when 1 then 2
when 2 then 2
when 4 then 2
when 3 then 3
else 4
END
注:在这种情况下,还可以将它们分组,例如1,2和4分组为2,并使用组大小,而不使用计算。
最后,改动就变得非常简单。Kasia能够进行一些小的改动,将数据减少到她需要的数据并更新一些计算,并且工作簿的性能显著提高。在Tableau Desktop中,使用Tableau的性能记录器(“帮助”菜单 - >“设置和性能” - >“开始性能记录”),我们可以看到做了这些改进的工作簿与之前相比,有巨大的差异。
原来版本:39.57秒打开工作簿,23.15秒表计算
更新版本:2.075秒打开工作簿
我希望这个信息对你有所帮助。如果你有任何问题,请随时给我发电子邮件:
邮箱地址:
Jeff@DataPlusScience.com
原文标题:
Optimizing Tableau Workbooks
原文链接:
https://www.dataplusscience.com/OptimizeTableau.html
译者简介:张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。
「完」
本次转自:THU数据派 微信公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读
原创系列文章:
1:从0开始搭建自己的数据运营指标体系(概括篇)
2 :从0开始搭建自己的数据运营指标体系(定位篇)
3 :从0开始搭建自己的数据运营体系(业务理解篇)
4 :数据指标的构建流程与逻辑
5 :系列 :从数据指标到数据运营指标体系
6: 实战 :为自己的公号搭建一个数据运营指标体系
7: 从0开始搭建自己的数据运营指标体系(运营活动分析)
数据运营 关联文章阅读:
运营入门,从0到1搭建数据分析知识体系
推荐 :数据分析师与运营协作的9个好习惯
干货 :手把手教你搭建数据化用户运营体系
推荐 :最用心的运营数据指标解读
干货 : 如何构建数据运营指标体系
从零开始,构建数据化运营体系
干货 :解读产品、运营和数据三个基友关系
干货 :从0到1搭建数据运营体系
数据分析、数据产品 关联文章阅读:
干货 :数据分析团队的搭建和思考
关于用户画像那些事,看这一文章就够了
数据分析师必需具备的10种分析思维。
如何构建大数据层级体系,看这一文章就够了
干货 : 聚焦于用户行为分析的数据产品
如何构建大数据层级体系,看这一文章就够了
80%的运营注定了打杂?因为你没有搭建出一套有效的用户运营体系
从底层到应用,那些数据人的必备技能
读懂用户运营体系:用户分层和分群
做运营必须掌握的数据分析思维,你还敢说不会做数据分析
合作请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于提速20倍!3个细节优化Tableau工作簿加载过程(附实例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






