本文主要是介绍数据化思维、 数字化陷阱和 0.01 突破,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文选自易开出行首席数据官兼首席技术官曾涛于2019年6月12日在清华大数据“应用·创新”系列讲座上所做的题为《数据化思维、 数字化陷阱和0.01突破》的演讲。

困局:数字化变革
在座同学们即将进入社会,面临的一个很大的变化就是数字化变革。也常被称作数字化治理、数字化转型,但我认为根本上还是一场变革。商业模式在变革,技术上也在变,数据随着技术创新对于整个商业模式的改变非常普遍,比如网约车对传统出租车行业的冲击。5G的出现,不仅仅是速度快了,更是带来整个包括物联网模型应用的质变。
那么未来,数字化的人工智能是否会取代我们?事实上,首先取代我们的不是人工智能,而是人工智能武装起来的新生代。

那么,我们如何应对变革?有三个关键词:技能、思维、同理心。
首先就是技能,清华大学数据分析的课程选修率非常高,数据分析是一个普遍的技能。我们当年找工作,说你不会OFFICE是很难想象的,以后数据分析就是基础技能。其次是思维,数据化思维是什么?你知道你不知道什么?理解数据化的思维怎么运转。最后是同理心,就是要让大家学习从企业的决策者,从领导角度来看待数据化的工作对于企业能起到多大的作用,我们在这个过程中能够起多大的作用。(这篇演讲更多从企业和客户角度出发,而不是个人数据技能。对此,我有过纠结:中规中矩讲些概念技能算了。但这些年磕磕绊绊告诉我,不以企业盈利为目标的数据挖掘会造成多大损失,个人与企业利益合一是职场成长的快行道,但愿师弟师妹们们能理解我的苦心。)
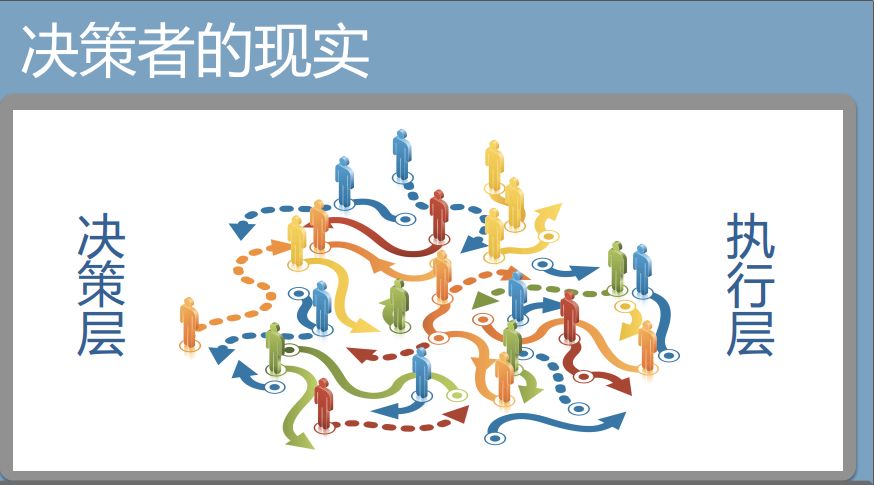
决策者在进行决策的时候,面对的现实却是:各种各样的人情、利益和冲突。上面的决策下来以后,被各方利益层层扭曲,执行力度减弱。哪怕现在最好的这些企业,也都会多多少少存在这样的问题。
以前没有大数据,组织怎么做决策的呢?两个措施:一个是决策权的集中,比如从秦朝开始,中国的历朝历代都会集中决策权,尤其是进行变革的时候,你会发现历史上的改革者,往往要集权,如商鞅、张居正、王安石等。第二个是执行权下放,最好的例子是中国的改革开放。
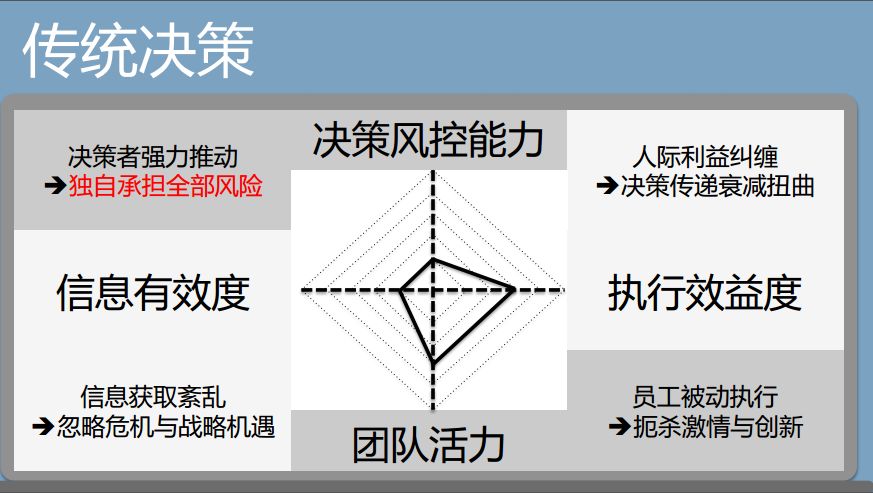
在传统决策模式里,要想做决策,首先要获取信息。但越是集权型的企业,老板获得的信息越是偏的。其次,老板做下来的决策,在组织里会因为人情、利益等各种各样的原因被层层扭曲。第三,决策风险太大。商鞅也好,王安石也好,张居正也好,因为你要推动整个的系统改变,所有的系统反弹都会集中在决策者的身上。意味着决策者要承担所有的风险。最后,这样的决策体系,员工被动执行,扼杀激情和创新。到了数字化变革时代,传统的决策方式越来越难走了。
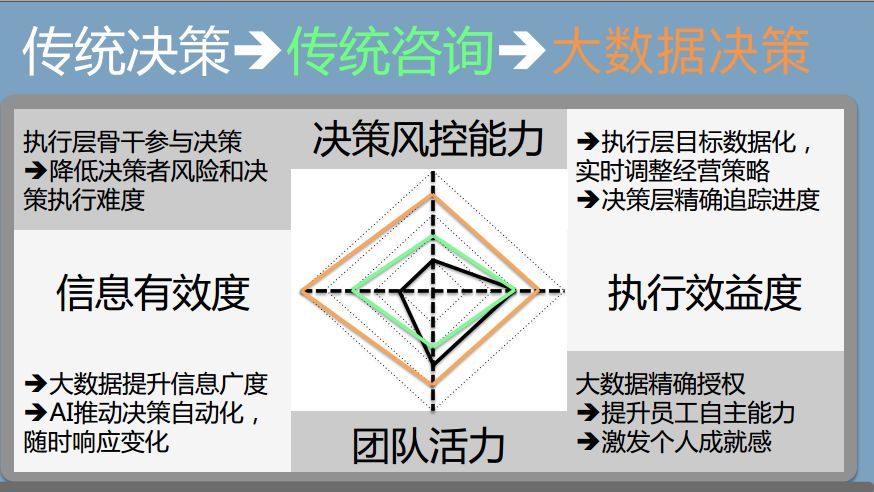
首先,从决策风险来讲,因为有大数据的支持,决策者可以不必通过金字塔式的这种结构获得信息,为什么中国的大数据发展这么快,国家决策层的确是有强烈的需求,需要大数据来贯穿整个官僚集团,直接下沉到第一线去获取数据;第二,数据获取的精度、广度都提升了;第三,能够及时让基层看到改进带来的效果,所以对于执行层也是有很大的帮助,团队活力会提升。
所以,顺应数字化变革是我们企业和个人的共识。不管我们打工还是创业,都要顺应这个潮流。

潮流虽好,但现在数字化转型做得并不顺利。首先,数字化的工作给企业带来的效益很难量化;其次,企业数字化成本非常高,如果大家选择数据行业,以后不管是人工智能也好,还是数据分析师、数据科学家,你们的薪资会很高,这会大大提高人力成本。此外还有风险成本和时间成本,选择了这种数据化的决策,也有可能对企业造成伤害。最后,任何一个员工也不希望天天被数字盯着,数字化会受到来自执行层的阻力。这三方面因素就是所说的数字化陷阱,层层阻力之下,数字化决策变成了老板的一把手工程,变相又回到了传统决策模式:“决策者承担最大的风险”。
好在经过这几年新媒体的耳濡目染,大部分的团队和公司实际还是认可数字化的必要性,但是满意度非常之低,感觉满意的只有四分之一,70%多的人是处于无所谓和不满意。
转变:数据化思维
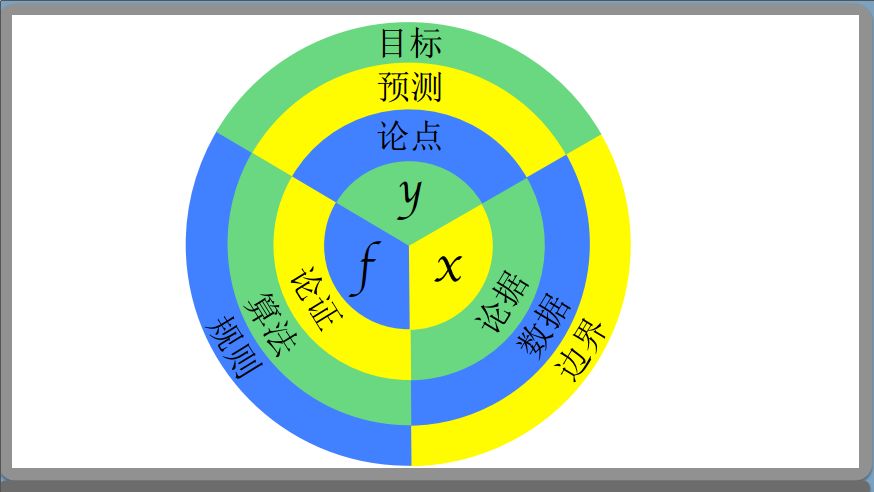
避开数字化陷阱,就先从数据化思维的转变开始。
什么是“数据化思维”?我认为就是函数“Y=F(X)”,X是论据,F函数是论证方法,得到的是论点Y。如果是从数据上,X是获取的数据,F是算法模型,Y是预测的结果。所以数据化思维就是这么简单,是这三段关系。
举一个信息回归的例子,一个订单的行驶里程和行驶时长,这是一个线性的关系,就是Y=F(X)。F代表一个因果关系,如果大家去学数据分析的话,基本上会遇到相关性的问题。我们分析出来的结果,很多都是一个相关性,而不是因果。但是你想说服老板、同事,仅有相关性是不够的,需要你解释因果。对因果的追求是人类一个强烈的进化动力,包括科学也是因果的一个关系,当然我们在分析的时候,部分的相关性是可以替代因果关系。
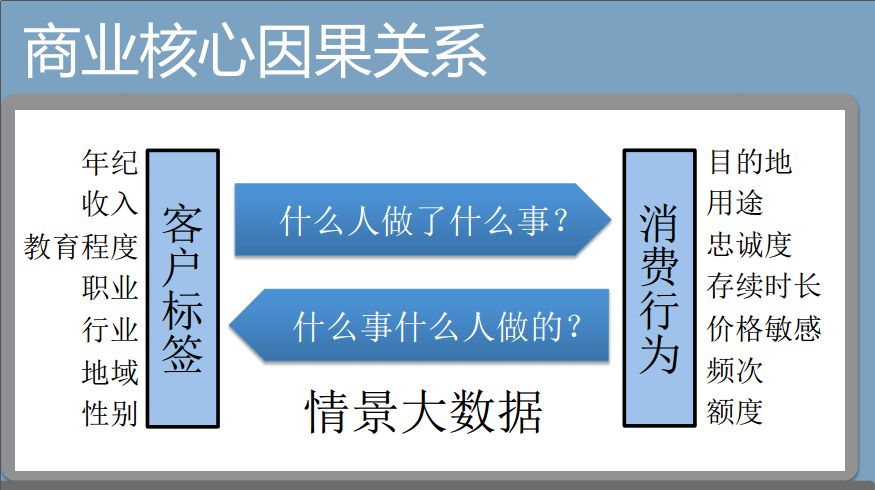
在企业中的核心因果关系是什么?就是客户的标签和消费行为之间的关系。客户的标签有年龄、收入、职业,消费行为有忠诚度、频次,实际上F就是什么人做什么事,什么样的客户会产生什么样的消费。反过来说,什么事是什么人做的,某一类消费行为是哪个特征的客户造成的。
所以,商业的数据化思维,就是“收入=F(客户,成本)”。成本是你投入的资源,客户是选择投入资源的对象,最后的结果是收入。
数据化思维有两个基础思维,一个是对比,一个是分解。
先说对比,有四种对比的方法,分别是A/B测试,比如我将人群随机分为两组,可以认为这两组的人群客户是一样的;第二种是甲乙对比,比如把客户按照性别分别分析消费决策;第三种是前后对比,比如运营策略调整前后的收入变化对比;第四种是类比,指不同事物在同一个维度上的对比,比如同一时段,电力消费与GDP的对比。
在企业做数据分析的时候,老板会问说为什么这个业务下降,为什么这个业务没有做好,这时候光有财务分析是不够的,我们需要一种新型的数据分析模型,要把消费行为的过程解析出来。这就涉及到数据化思维的第二种思维,就是分解。遇到难题,人脑的习惯思维就是把它分解成几个小难题,机器学习模拟的就是人脑的思维模式。

数据分解的起点是企业目标,企业的最基本目标是赚钱,那么,分解以利润为起点,得到了一个简单的企业数字化管理框架案例(如下图)
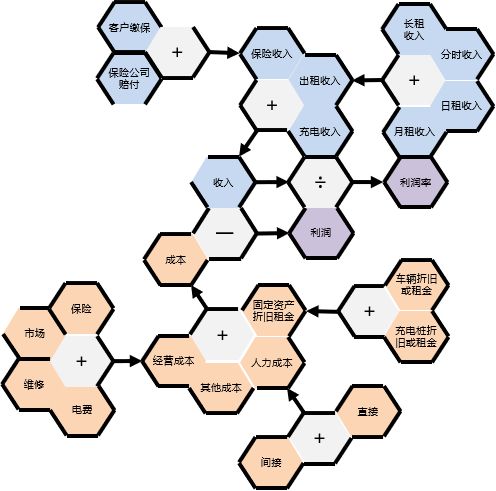
企业数据化驱动以利润为核心,这个企业就会唯利是图吗?为什么像亚马逊、京东这样的公司,一直没有盈利,却有很高的市值。那是因为资本市场对这样公司所拥有的未来客户价值的认可,而不是利润的认可。没有客户的支持就没有利润,所以亚马逊的价值趋向不是利润,而是客户价值。我们又找到了一个新的数据模型分解起点,就是客户价值。
那么如何衡量客户价值?收入的确是客户对企业服务的最直接的价值认可。但是,并不能用收入来衡量客户价值。因为,收入是结果而不是过程,是过去而不是未来,且不易分解到具体的岗位上,最关键的是,收入并不体现客户的潜在价值,曾经的摩拜估值很高,是因为投资本界对于用户未来的收入附加的服务能够产生的收入有很大的空间(看来是高估了),所以现在的收入是体现不出来潜在价值的。

我们引入一个新的变量“客熵”,来对客户价值增量进行衡量。消费额只是客户价值的一部分,另一部分是间接价值,有口碑价值和潜在消费。比如腾讯推广一个新的产品给老客户,并不需要广告,这是一种口碑价值。还有潜在消费,客户更有可能对它的未来的新服务进行付费。互联网企业相比传统企业,客户的数据很多,这点就说明为什么互联网企业会发展的比较快,是因为互联网是围绕着客户的满意展开的。
突破:易精数据决策
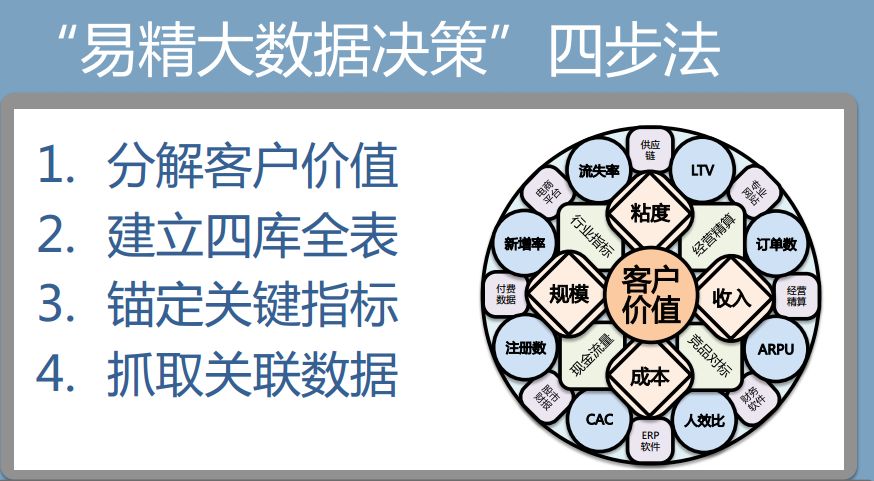
回到如何避开三个数字化陷阱“成本高企”、“收益难以衡量”和“人性冲突”主题。上一章数据化思维告诉我们,客户价值是企业数据化管理的核心。首先,以客户价值为起点,分解展开的数据模型,能大幅降低数据挖掘的不确定性,聚焦在企业的核心价值,避免数据团队的“炫技性”浪费,避免陷入成本陷阱。其次,客户价值分解包含了企业生存要害“利润=收入-成本”,就意味着这样的数据模型可让所有数据最终与利润关联,即可以预测和追踪数字化转型带来的收益,让企业决策者放心。最后,这样的数据化管理模型是与现有财务数据管理融合一体的,不是颠覆性变革,而是渐入佳境,丰俭由人的,大大降低了团队数字化转型中的阵痛。这就是我的讲演题目中的“0.01突破”的用意。
具体的方法论有四步,第一个怎么样分解客户价值。客户价值包括收入、成本、客户黏度与规模。对于互联网公司,规模和成长速度都非常重要,黏度是指流失率、付费率、转化率,代表客户对你服务的满意程度。第二步有四个表,经营精算表,竞争服务产品对标表,现金流量表和行业指标表。第三步,锁定一些关键性指标来衡量企业,不同企业的关键性指标不一样。最后是选择有效数据源,通过技术手段抓取关联的数据。
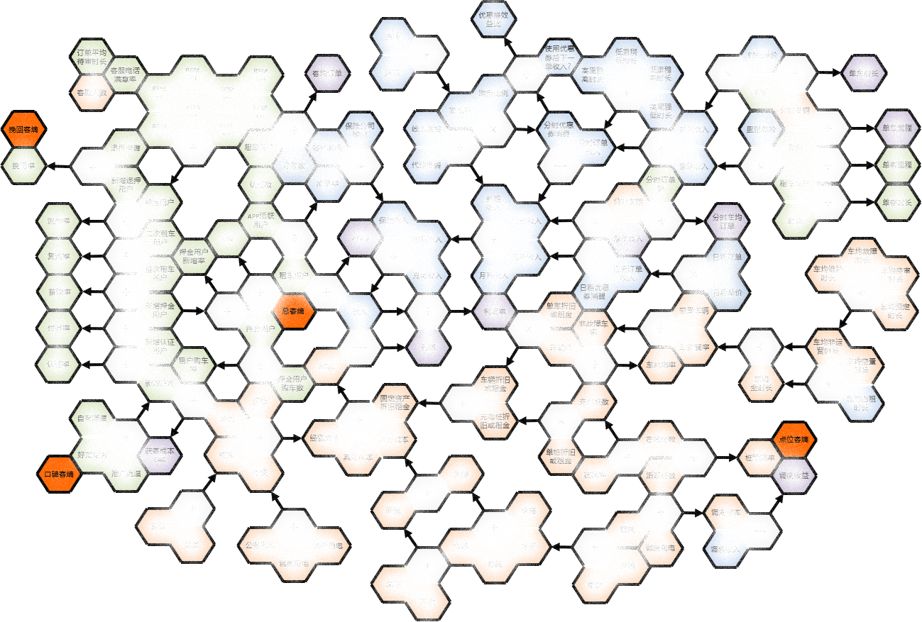
以客户价值为核心分解的企业数字化管理全息蜂巢图如下(因企业的数据安全隐去部分内容)。绿色为客户相关数据,蓝色为收入相关数据,橙色为成本相关数据。三部分数据互相关联,形成精细化数据运营网络。
实战:新能源车联网应用案例
说一个共享出行的例子。

客户在一线沿海的发达城市和中部的欠发达城市之间的一个过渡。这样的话,我们业务的拓展方向,开始一些尝试或者改走一些点就特别清楚,这是数据化方法给企业决策过程带来的一个好处:减少情绪性和个体利益引发的无效争议。
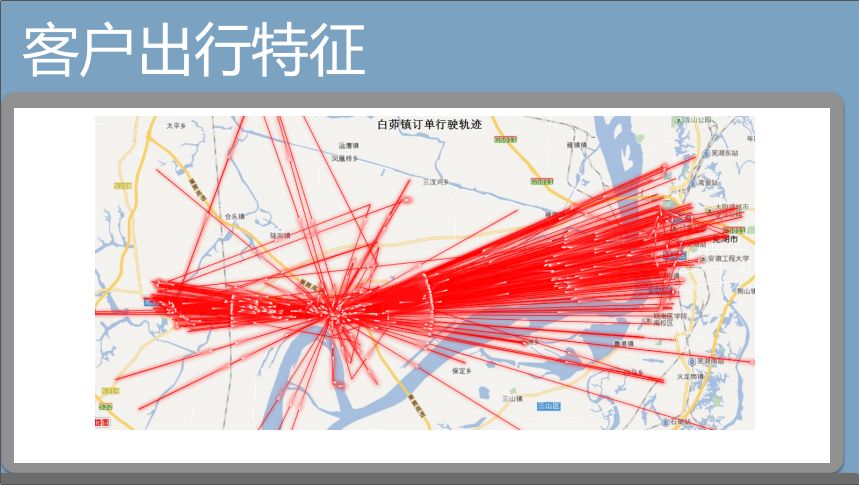
另一个是客户出行的特征。我们有一个收入很高的网点白茆镇,是在市中心和无为县城中间的节点,这样的点的特征会大大地提升我们整个业务收入模型,包括车辆的轨迹,不同地方人去不同地方,什么时间可以代表什么的消费习惯,都可以分析出来。一个城市,根据收入和轨迹的热点情况,去判断哪一个地方增加网点,对于零售行业新零售都需要这样的分析。
我们希望达到一个数字化的状态是数字孪生出行(如下图)
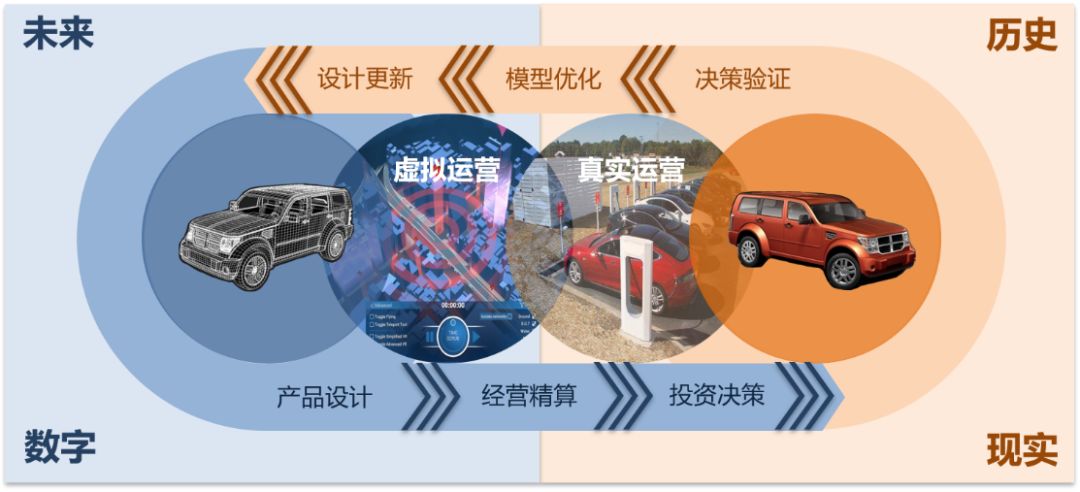
(案例描述因篇幅原因略过)
总结
希望大家能够掌握易精大数据决策法,来判断行业趋势和未来的就业选择,学会和投资者、老板、客户相处方式。当面临事业的选择,不妨问问自己:“我为什么要坚守?为什么要离开?”答案是否经过了经过数据和逻辑的验证,而不是人云亦云,或者随“薪”所欲。
作为一个数据分析师,我认为数据挖掘有三重境界,借用王国维先生的人生三重境界,但次序不同。第一重是“为伊消得人憔悴,衣带渐宽终不悔”,如果你选择数据行业,要有心理准备,这是非常苦逼的工作,特喜欢新浪的一位同行的自评:与业务“贴身肉搏”。第二个阶段才是“昨夜西风凋碧树,独上高楼望尽天涯路”,为什么不是第一个阶段就有这个,因为像王国维这样的大师是生而知之的,普通人需要后天努力,数据分析师或者数据从业者要追求认知规律,减少一些情绪性和利益性的影响,需要一定人生历练。第三个阶段,“众里寻他千百度,蓦然回首,那人却在灯火阑珊处”。第一个阶段是向下看,埋头耕地;第二个阶段是向远处看,第三个阶段往回看,走了这么多的路,吃了这么多的苦,原来苦苦追求的大道竟然就是那些传承了上百年的公理和普世价值。
最后说两句心里话:
首先,“认知重于结果”。不是为优化而优化,也不是为收入而收入,数据工作的核心是获得因果关系F。有了因果关系,我们才有可能在未来应对快速变化的世界环境,因为这个F是整个变革中不变的那个“1”。有些项目没有物质回报,但只要能得到因果认知就值得干了。
其次,“善意先于能力”。“拿人钱财替人消灾”,真心为雇主/客户着想,帮助人家多赚钱多省钱。与人多结善缘,一时虽然没有合作,可能多少年以后带来一个惊喜。
果真如此,一生足矣!谢谢大家!
END
本文转自:数据派THU ;获授权;
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于数据化思维、 数字化陷阱和 0.01 突破的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!