本文主要是介绍推荐 :降维是数据科学家的必由之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:shanthababu 翻译:王可汗 校对:欧阳锦
本文约2200字,建议阅读10分钟本文为大家介绍了降维的概念及降维技术主成分分析(PCA)在特征工程中的应用。
本文作为数据科学博客马拉松的一部分发表。
https://datahack.analyticsvidhya.com/contest/data-science-blogathon-7/
你好!我喜欢分享我作为一个初级数据科学家的有趣经历,我甚至可以说在那时我在这个数据科学领域只是一个初学者。
有个客户来找我们要用机器学习来实现他们的问题,不管以无监督形式还是有监督形式。我本以为这将是一如既往的执行模式和流程,因为根据我小规模实现或训练的经验,我们往往使用25~30个特征。我们用它来预测、分类或聚类数据集,并分享结果。
但这一次,他们提出了成千上万的特征,但我有点惊讶和害怕,开始晕头转向。与此同时,我的高级数据科学家把团队里的每个人都带到了会议室。

我的高级数据科学家(Senior Data Scientist ,Sr. DS)创造了新单词,对我们来说,这只不过是降维或维度灾难的问题,所有的初学者都认为他将解释物理层面的一些东西,因为我们几乎不记得我们培训项目中遇到过这类情况。接下来,他开始在画板上画(见图1)。当我们开始看1-D, 2-D时我们很舒服,但3-D时,我们开始晕头转向。
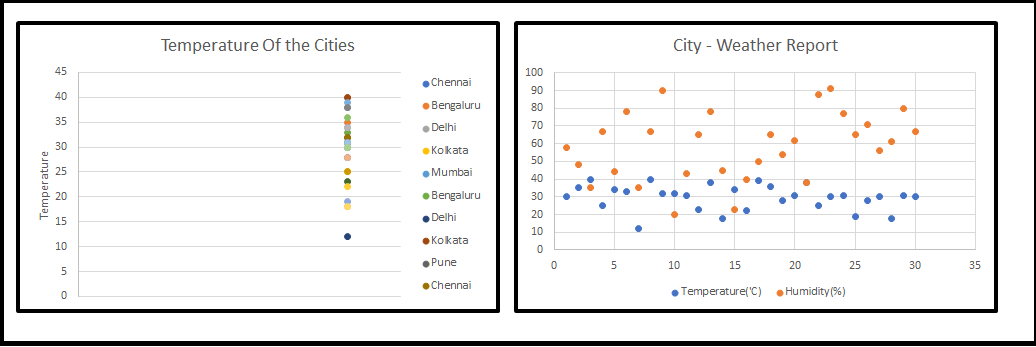
1-D,2-D

3-D
Sr. DS继续他的讲座,所有这些示例图片都是显著的特征,我们可以在实时场景中使用它们,许多机器学习问题涉及数以千计的特征,所以我们最终训练这些模型的速度会变得非常慢,以至于不能很好地解决业务问题,并且这时候我们不能冻结模型,这种情况就是所谓的“维度灾难”引起的。然后,我们开始思考一个问题,我们应该如何处理这个“维度灾难”问题。
他深吸了一口气,继续以自己的风格分享自己的经历。他从一个简单的定义开始,如下:
维度是什么?
我们可以说,我们的数据集中特征的数量被称为其维数。
什么是降维?
降维是对给定数据集进行(特征)降维的过程。也就是说,如果您的数据集有100列/特性,并将列数减少到了20-25列。简单地说,您是在二维空间中将柱面/球体转换成圆或立方体,如下图所示。
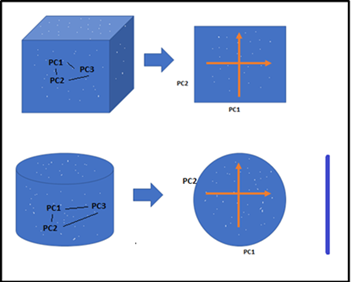
3d – 2d转换
他在下面清楚地描绘了模型性能和特征(维度)数量之间的关系。随着特征数量的增加,数据点的数量也成比例地增加。更直接的说法是越多的特征会带来更多的数据样本,所以我们已经表示了所有的特征组合及其值。

模型性能Vs特征数量
现在房间里的每个人都从一个更高的角度领会到了什么是“维度灾难”。
降维的好处
突然,一个团队成员问他能否告诉我们在给定数据集上进行特征降维的好处。我们的前辈并没有停止进一步分享他渊博的知识。他继续如下。如果我们进行降维,会有很多好处。
它有助于消除冗余的特征和噪声误差因素,最终增强给定数据集的可视化。
由于降低了维度,可以表现出优秀的内存管理。
通过从数据集中删除不必要的特征列表来选择正确的特征,从而提高模型的性能。
当然,更少的维度(强制性的维度列表)需要更少的计算效率,更快地训练模型,提高模型的准确性。
大大降低了整个模型及其性能的复杂性和过拟合。
是的!这是一个令人敬畏的,鲁棒的和动态的“降维”。现在,我可以将降维的优点总结如下图所示。希望对你也有帮助。
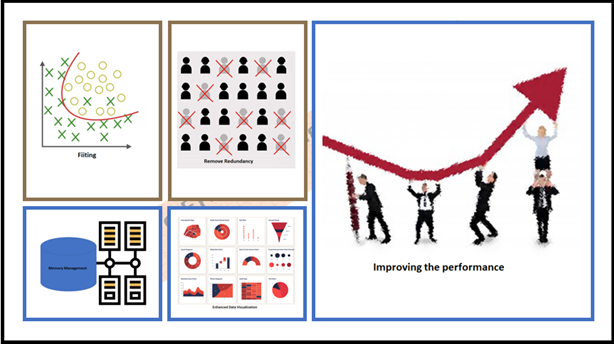
降维的好处
当然,下一步是什么!我们接下来探讨有哪些技术可以用于降维。
降维技术
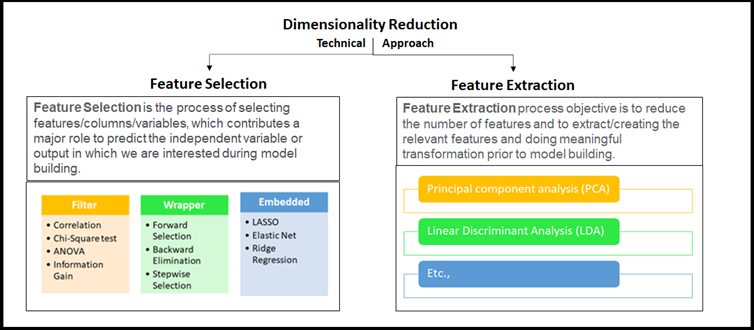
我们的Sr. DS对数据科学领域中任何可能的技术非常感兴趣,他继续他的解释。降维的方法被笼统地分为两种,如前面提到,考虑选择最佳拟合特征或删除给定高维数数据集中不太重要的特征。些高级技术通常被称为特征选择或特征提取,基本上,这是特征工程的一部分。他把这些点讲得很清楚。
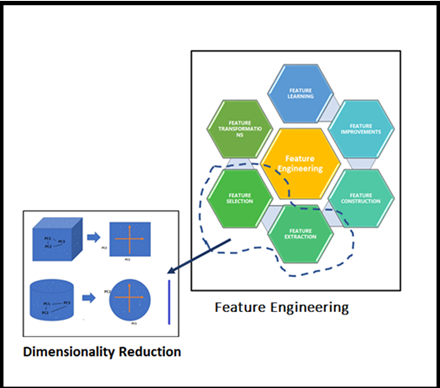
特征工程家族中的降维定位
他带领我们进一步深入概念,理解在高维数据集上应用“降维”的重点。一旦我们看到下图,我们就可以将特征工程和降维联系起来。看看这个图,我们Sr. DS的降维的精髓就在里面!
每个人都想知道如何通过简单的编码来使用Python库来使用这些降维技术。我们的Sr. DS要求我拿来彩色笔和板擦。
Sr. DS拿起新的蓝笔,开始用一个简单的例子来解释PCA,如下所示,在此之前,他解释了什么是降维PCA。
主成分分析(PCA):主成分分析是一种对给定数据集进行降维的技术,在信息损失可忽略的情况下,增加了可解释性。这里变量的数量在减少,因此进一步的分析更简单。它把一组相关的变量转换成一组不相关的变量。用于机器学习预测建模。他建议我们通过特征向量,特征值分析。
他取了熟悉的wine.csv来快速分析。

# Import all the necessary packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn import metrics
%matplotlib inline
import matplotlib.pyplot as plt
%matplotlib inline
wq_dataset = pd.read_csv('winequality.csv')
对于给定数据集的数据分析
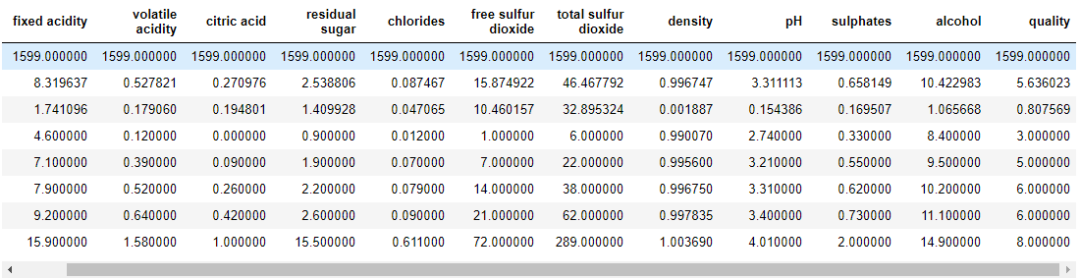
wq_dataset.head(5)

wq_dataset.describe()
wq_dataset.isnull().any()

在给定的数据集中没有空值,很好,我们很幸运。
找出每个特征的相关性
correlations = wq_dataset.corr()['quality'].drop('quality')
print(correlations)

使用热力图进行相关性表示
sns.heatmap(wq_dataset.corr())
plt.show()

x = wq_dataset[features]
y = wq_dataset['quality']
[‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’]
#使用train_test_split创建训练和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=3)
训练和测试集形状
print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)Traning data shape: (1199, 8)
Testing data shape: (400, 8)
PCA降维实现(2列)
from sklearn.decomposition import PCA
pca_wins = PCA(n_components=2)
principalComponents_wins = pca_wins.fit_transform(x)
命名为第1主成分,第2主成分
pcs_wins_df = pd.DataFrame(data = principalComponents_wins, columns = ['principal component 1', 'principal component 2'])
新的主成分及其值。
pcs_wins_df.head()
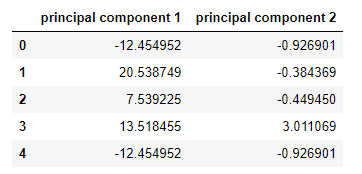
当我们看到上面两个新的列名和值时,我们都感到惊讶,我们问‘fixed acidity’, ‘volatile acidity, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’等列会发生什么变化。Sr. DS说所有的都没有了,在应用了PCA对给定数据进行降维后,我们现在只有两列特征值,然后我们将实现很少的模型,这将是正常的方式。
他提到了一个关键词“每一个主成分的变化量”
这是由主成分解释的方差的分数是主成分的方差和总方差之间的比率
print('Explained variation per principal component: {}'.format(pca_wins.explained_variance_ratio_))
Explained variation per principal component: [0.99615166 0.00278501]
随后,他演示了以下模型
逻辑回归
随机森林
KNN
朴素贝叶斯
这些模型的精度更好,每个模型之间的差异很小,但他提到这是为了实现PCA。房间里的每个人都觉得我们完成了一次很棒的挑战。他建议我们动手尝试其他的降维技术。
好了,朋友们!感谢您的时间,希望我能在这里以正确的方式讲述我在降维技术方面的学习经验,我相信这将有助于在机器学习问题陈述中继续处理复杂数据集的旅程。加油!
原文标题:
Dimensionality Reduction a Descry for Data Scientist
原文链接:
https://www.analyticsvidhya.com/blog/2021/04/dimensionality-reduction-a-descry-for-data-scientist/
译者简介:王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于推荐 :降维是数据科学家的必由之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




