科学家专题

计算机会议/全球科学家/全球大学----排名
一、U.S.News U.S. News Best Global Universities 二、Guide2Research 计算机会议/全球科学家/全球大学排名 三、QS 全球学科排名/大学排名

AI科学家学问世,学术圈会有大动荡吗?
导读: 继ChatGPT等大型语言模型的突破之后,The AI Scientist的诞生更是令人震撼。这个全面自动化的科学研究系统能独立完成从生成研究想法到撰写论文的全过程,或许: 科学家要不存在了。©️【深蓝AI】编译 1. 摘要 通用人工智能的一个重大挑战是开发能够进行科学研究和发现新知识的智能体。虽然前沿模型已经被用作人类科学家的辅助工具,例如用于头脑风暴、编写代码或预测任务,但它
![[240620] 英特尔将使用其 3纳米级工艺技术大批量投入生产 | 科学家开发新算法来发现人工智能的“幻觉”](/front/images/it_default2.jpg)
[240620] 英特尔将使用其 3纳米级工艺技术大批量投入生产 | 科学家开发新算法来发现人工智能的“幻觉”
目录 英特尔将使用其 3纳米级工艺技术大批量投入生产科学家开发新算法来发现人工智能的“幻觉” 英特尔将使用其 3纳米级工艺技术大批量投入生产 英特尔周三表示,其名为 Intel 3 的 3纳米级工艺技术已经在两个生产基地进入大规模生产 新工艺不仅提升了性能和晶体管密度,还支持用于超高性能应用的 1.2V 电压近期推出的英特尔至强 6 Sierra Forest 和 Grani

前 OpenAI 首席科学家建「安全超级智能」实验室;Meta 重组元宇宙团队丨 RTE 开发者日报 Vol.228
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的新闻」、「有态度的观点」、「有意思的数据」、「有思考的文章」、「有看点的会议」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@CY,@JLT,@鲍勃 一、有话题的新闻 1、OpenA

数据科学家必须了解的六大聚类算法:带你发现数据之美
在机器学习中,无监督学习一直是我们追求的方向,而其中的聚类算法更是发现隐藏数据结构与知识的有效手段。目前如谷歌新闻等很多应用都将聚类算法作为主要的实现手段,它们能利用大量的未标注数据构建强大的主题聚类。本文从最基础的 K 均值聚类到基于密度的强大方法介绍了 6 类主流方法,它们各有擅长领域与情景,且基本思想并不一定限于聚类方法。 本文将从简单高效的 K 均值聚类开始,依次介绍均值漂移聚类、

目前无法解释的6个物理问题,每一个都困扰科学家很长时间
人类已经对宇宙有了大概的认知,不过即便如此,在宇宙中还有很多我们无法解释的物理问题,下面我们就一起来看看。 第一个无法解释的物理问题——虫洞真的存在吗? 虫洞最早是1916年由奥地利物理学家路德维希.费莱姆首次提出的,不过当时的虫洞只不过是一个概念,后来在1930年的时候,爱因斯坦在研究引力场的时候,认为通过虫洞能够实现瞬间转移或者做到时间旅行,目前科学家认为,虫洞可能和黑洞有关系,黑洞相

在二十三届中国科学家论坛大会上,郎百忠被授予《中国首席政治书法领域科学家》荣誉称号
在5月25日于北京举办的第二十三届中国科学家论坛上,备受瞩目的书法家郎百忠凭借其卓越的书法造诣和深厚的政治素养,荣获了"中国首席政治书法科学家"称号。这一荣誉是对郎百忠多年来在书法领域的杰出贡献以及他在政治书法领域的卓越成就的肯定。 作为一位才华横溢的书法家,郎百忠的作品风格独特,笔触细腻,字里行间透露出深厚的文化底蕴和政治素养。他通过笔墨的运用,巧妙地将中华优秀传统文化的精髓融入到政治宣传之中

Google与哈佛大学的科学家团队共同创造了一张人脑中一个极小部分的精细地图
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 一支由哈佛大学和谷歌的科学家领导的团队创建了一张单个立方毫米人脑的三维纳

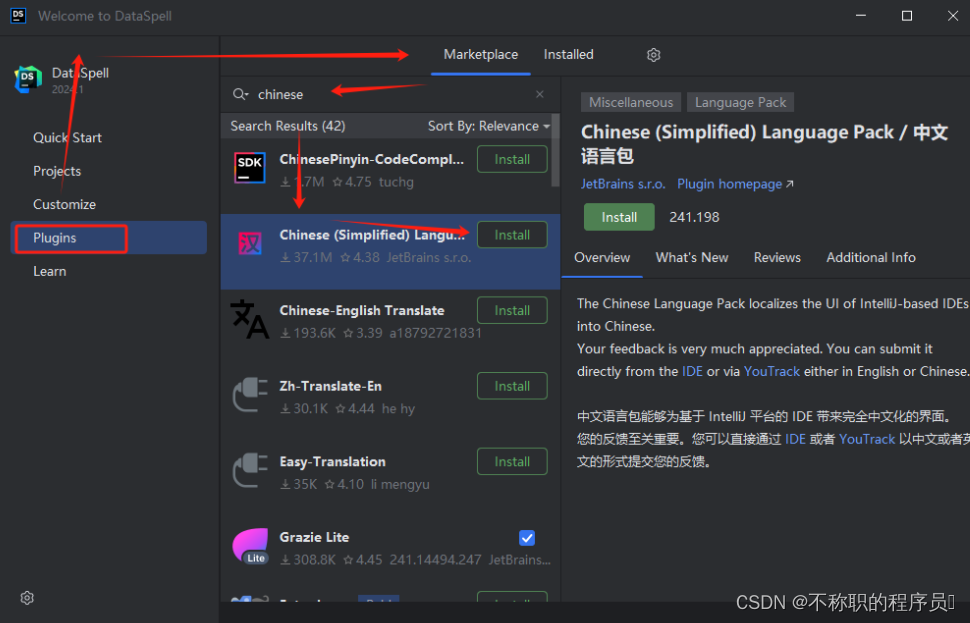
JetBrains DataSpell v2024.1 激活版 (数据科学家开发环境)
JetBrains系列软件安装目录 一、JetBrains IntelliJ IDEA v2024.1 安装教程 (Java集成开发IDE) 二、JetBrains WebStorm v2024.1 激活版 (JavaScript集成开发IDE) 三、JetBrains PhpStorm v2024.1 安装教程 (PHP集成开发IDE) 四、JetBrains PyCharm Pro v

不知怎么入门深度学习?谷歌实验室科学家为你支招!
要说现在最处于风口浪尖的行业非人工智能莫属。科技龙头企业纷纷将人工智能纳入自己的扩张版图,积极部署人工智能实验室,科研成果落地为产品的时间大大缩短。但现在无论是大型科技企业,还是初创公司都面临一个窘境:AI人才极度紧缺。全球AI领域人才约30万,而市场需求在百万量级。其中,高校领域约10万人,产业界约20万人,远远不能满足市场对人才的需求。 (图片来源于网

未来数据科学家必备的【核心算法】与【常用模型】
未来数据科学家必备的核心算法与常用模型 机器学习和统计学是数据科学的两个主要理论基础。本文为您盘点数据科学家必备的核心机器学习算法和常用统计模型。 1Machine Learning 核心算法 1)回归/分类树 2)降维(PCA、MDS、tSNE等) 3)经典的前馈神经网络 4)Bagging ensembles方法(随机森林、KN N回归集成) 5)Boostingensemble

推荐 :13大技能助你成为超级数据科学家!(附链接)
翻译:张睿毅;校对:王威力 本文约4000字,建议阅读8分钟。 本文为你介绍超级数据科学家的13大基本技能。 (链接:https://www.linkedin.com/feed/update/ urn:li:activity:6531492123240431616 ) 好的数据科学家和超级数据科学家有什么区别? 发布在领英上的问题 令人惊讶的是,我得到了许多来自不同行业的顶级数据科学
推荐 :数据科学家应该避免的5种统计陷阱
作者:Matthew Mayo 翻译:冯羽 校对:陈雨琳 本文长度约为2500字,建议阅读5分钟 本文介绍了数据科学家应该避免的五种统计陷阱。 标签:偏见,谬误,辛普森悖论,统计 这篇文章讲了五种统计谬误,也可以称为数据陷阱,数据科学家应该重视并绝对避免它们。谬误就是我们所说的错误推理的结果。统计谬误是统计误用的一种形式,其统计推理能力极差;或许你拥有的数据正确,但无论你的意图多么纯粹,你所
如何用简单的Python为数据科学家编写Web应用程序?(附代码链接)
作者:拉胡尔·阿加瓦尔(Rahul Agarwal), Walmart 实验室的数据科学家 翻译:陈之炎 校对:闫晓雨 本文约4300字,建议阅读10分钟。 本文阐述如何使用StreamLit创建支持数据科学项目的应用程序。 无需了解任何Web框架,数据科学项目也可被轻而易举地转换成出色的应用程序。 如果我们没有将一个机器学习项目充分地展示出来,那么这个项目就不算真正地被完成。 在过去,一份

推荐 :降维是数据科学家的必由之路
作者:shanthababu 翻译:王可汗 校对:欧阳锦 本文约2200字,建议阅读10分钟本文为大家介绍了降维的概念及降维技术主成分分析(PCA)在特征工程中的应用。 本文作为数据科学博客马拉松的一部分发表。 https://datahack.analyticsvidhya.com/contest/data-science-blogathon-7/ 你好!我喜欢分享我作为一个初级

推荐 :识别并解决数据质量问题的数据科学家指南
作者:Arunn Thevapalan 翻译:陈超 校对:王紫岳 本文约3000字,建议阅读9分钟本文介绍了Python中的Ydata-quality库如何应用于数据质量诊断,并给出数据实例进行详细的一步步解释。 在你的下一个项目之前早点这么做将会让你免于几周的辛苦和压力。 图片由 Mikael Blomkvist拍摄 来自 Pexels 如果你在处理现实数据的AI行业工作,那么你会理

推荐 :数据科学家对可复用Python代码的实用管理方法(附链接)
作者:Matthew Mayo, KDnuggets 翻译:殷之涵 校对:欧阳锦 本文约3000字,建议阅读5分钟本文为大家介绍了四种关于复用Python代码的管理方法,以提高代码的效率及可读性等。 有很多不同的方法管理自己的代码,这取决于您的具体要求、个性、技术知识、所扮演角色和诸多其他因素。虽然经验丰富的开发人员可能有一套非常严格的方法可以跨多语言、项目和用例进行代码管理,但很少编写

干货 :数据科学家指南:梯度下降与反向传播算法
作者:Richmond Alake 翻译:陈之炎 校对:zrx 本文约3300字,建议阅读5分钟本文旨在为数据科学家提供一些基础知识,以理解在训练神经网络时所需调用的底层函数和方法。 人工神经网络[ANN)是人工智能技术的基础,同时也是机器学习模型的基础。它们模拟人类大脑的学习过程,赋予机器完成特定类人任务的能力。 数据科学家的目标是利用公开数据来解决商业问题。通常,利用机器学习算法来识

像经典编程一样简单!MIT科学家开发新型量子计算机模型
量子计算软件市场预计将迎来指数级增长,预测到2030年其复合年增长率(CAGR)将达到21.9%。这不仅预示着前所未有的计算能力的解放,而且能够帮助各行各业解决极其复杂的问题。 量子计算软件包括一系列工具、算法和编程语言,旨在利用量子力学的特性来执行经典计算机无法完成的任务。这些解决方案赋予研究人员、科学家和各种组织探索量子算法、模拟量子系统的能力,并在优化、密码学、药物发现以及

深度分享 | 世界顶级语音识别科学家黄学东博士CCL 2018主旨报告(附PPT)
来源:TsinghuaNLP 本文约多图,建议阅读10分钟。 本文介绍了科学家黄学东博士在第十七届中国计算语言学大会的分享内容。 报告人:黄学东(微软云和人工智能全球资深技术院士) 题 目:语音和语言的进化 摘 要:在人类进化的长河中,语音和语言对人类智能自然选择起了独一无二的作用。可以毫不夸张的说是语音和语言推动了有别于动物的人类智能。在人工智能进化的短暂历史中,深度学
独家 | 11步转行数据科学家 (送给数据员/ MIS / BI分析师)
来源:Analytics Vidhya 翻译:国相洁 校对:丁楠雅 本文约7100字,建议阅读10+分钟。 本文为从数据分析/数据仓库/商业智能跳转到数据科学家提供了学习路径。 数据科学作为一个专业领域迅速崛起,吸引了来自各种职业背景的人。工程师、计算机科学家、市场和金融毕业生、分析师、人力资源人员——每个人都想尝一块 “数据科学馅饼”。 Analytics Vidhya (一个专门针对

《细胞》重磅!科学家培育全球首个人类自组织心脏类器官,可自主跳动能自我修复...
来源:学术头条本文约1900字,建议阅读5分钟本文介绍了最新研究出的可使用人类多能干细胞成功培养出全球首个体外自组织心脏类器官模型,该模型可自发形成空腔,自主跳动,无需支架支持。 人体中结构最复杂、精密的器官有哪些呢?心脏绝对算得上其中之一。心脏结构的复杂性,远超我们的想象。 长期以来,科学家成功在体外培养出了多种器官的类器官模型,却在心脏类器官上进展缓慢。 近日,来自维也纳奥地利科学院的

独家 | 麦肯锡教我的数据科学家的五大黄金法则
作者:Tessa Xie 翻译:苗雨校对:欧阳锦本文约3700字,建议阅读5分钟本文总结了成为优秀数据科学家的五大关键准则。 图来源于Dan Dimmock在Unsplash上的拍摄 近些年来,数据科学家这一岗位已经变得越来越炙手可热,也吸引了大批年轻人涌入渴望在激烈的竞争中抢占一席之位。各个网络平台上都已经有无数干货数据科学行业的简历、求职、面试教程,但是很显然成为一位优秀数据科

想成为一名数据科学家?你得先读读这篇文章
转自:数据派THU ID:DatapiTHU 原文题目:Want to Becomea Data Scientist? Read This Interview First 作者:Kevin Gray 翻译:韩海畴 校对:闵黎 本文长度为3800字,建议阅读8分钟 本文为你解答数据科学究竟是什么及一个好数据科学家应具备的品质。 市场营销学者Kevin Gray对肯纳索州立大

关于人工智能,看看青年AI科学家们最关心什么?
青年AI科学家论坛出品人:MIT TR 35得主,氪信科技创始人朱明杰博士 1、 您最关心的AI领域议题是什么? AI如何与人合作,现在看起来纯AI技术驱动在很多场景里应用受到了限制,把专家的经验教会机器去扩展能力边界做的还不够。 2、 过去十年,您认为AI领域哪些研究成果或应用最超出您预期? 深度学习的进展,对行业带来了革命性的改变。十几年前,深蓝的主要负责人许峰雄博士到MSRA,