本文主要是介绍数据分析师的完整流程与知识结构体系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【编者注】此图整理自微博分享,作者不详。一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。完整的数据分析流程:1、业务建模。2、经验分析。3、数据准备。4、数据处理。5、数据分析与展现。6、专业报告。7、持续验证与跟踪。
(注:图保存下来,查看更清晰)
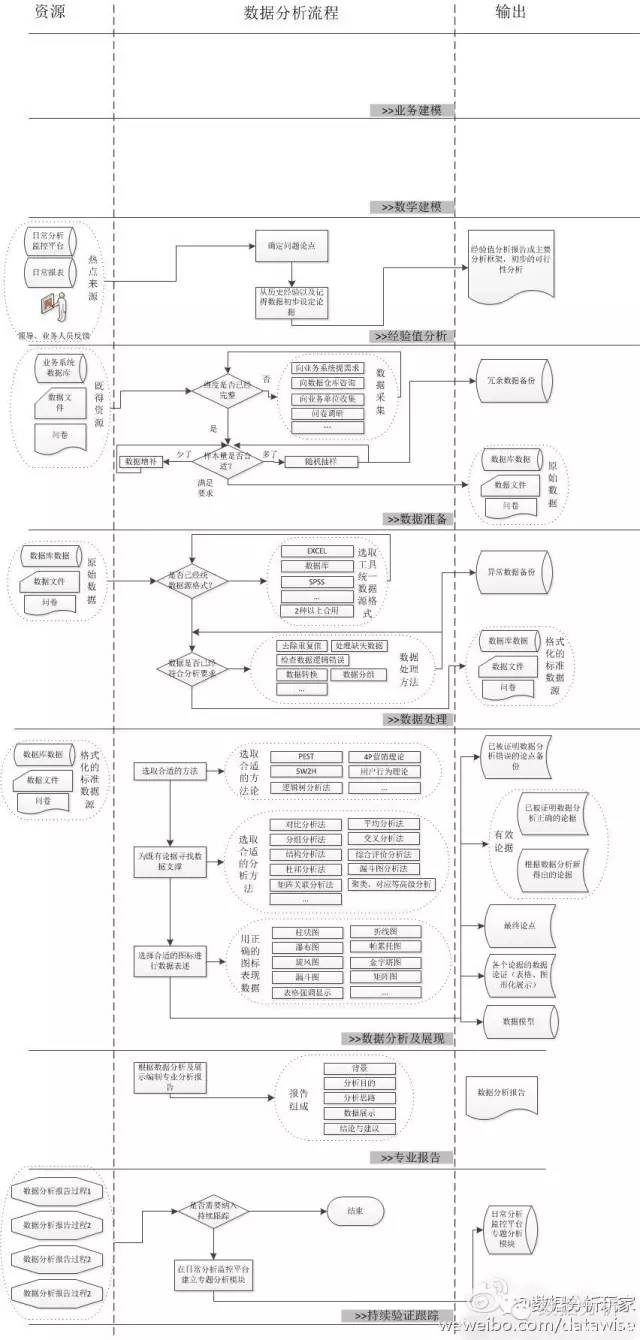
作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。
1. 数据采集
了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如:
Omniture中的Prop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。
在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(Webtrekk基于请求量付费,请求量越少,费用越低)。
当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。
在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。
2.数据存储
无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如:
数据存储系统是MySql、Oracle、SQL Server还是其他系统。
数据仓库结构及各库表如何关联,星型、雪花型还是其他。
生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。
生产数据库面对异常值如何处理,强制转换、留空还是返回错误。
生产数据库及数据仓库系统如何存储数据,名称、含义、类型、长度、精度、是否可为空、是否唯一、字符编码、约束条件规则是什么。
接触到的数据是原始数据还是ETL后的数据,ETL规则是什么。
数据仓库数据的更新更新机制是什么,全量更新还是增量更新。
不同数据库和库表之间的同步规则是什么,哪些因素会造成数据差异,如何处理差异的。
在数据存储阶段,数据分析师需要了解数据存储内部的工作机制和流程,最核心的因素是在原始数据基础上经过哪些加工处理,最后得到了怎样的数据。由于数据在存储阶段是不断动态变化和迭代更新的,其及时性、完整性、有效性、一致性、准确性很多时候由于软硬件、内外部环境问题无法保证,这些都会导致后期数据应用问题。
3.数据提取
数据提取是将数据取出的过程,数据提取的核心环节是从哪取、何时取、如何取。
从哪取,数据来源——不同的数据源得到的数据结果未必一致。
何时取,提取时间——不同时间取出来的数据结果未必一致。
如何取,提取规则——不同提取规则下的数据结果很难一致。
在数据提取阶段,数据分析师首先需要具备数据提取能力。常用的Select From语句是SQL查询和提取的必备技能,但即使是简单的取数工作也有不同层次。第一层是从单张数据库中按条件提取数据的能力,where是基本的条件语句;第二层是掌握跨库表提取数据的能力,不同的join有不同的用法;第三层是优化SQL语句,通过优化嵌套、筛选的逻辑层次和遍历次数等,减少个人时间浪费和系统资源消耗。
其次是理解业务需求的能力,比如业务需要“销售额”这个字段,相关字段至少有产品销售额和产品订单金额,其中的差别在于是否含优惠券、运费等折扣和费用。包含该因素即是订单金额,否则就是产品单价×数量的产品销售额。
4.数据挖掘
数据挖掘是面对海量数据时进行数据价值提炼的关键,以下是算法选择的基本原则:
没有最好的算法,只有最适合的算法,算法选择的原则是兼具准确性、可操作性、可理解性、可应用性。
没有一种算法能解决所有问题,但精通一门算法可以解决很多问题。
挖掘算法最难的是算法调优,同一种算法在不同场景下的参数设定相同,实践是获得调优经验的重要途径。
在数据挖掘阶段,数据分析师要掌握数据挖掘相关能力。一是数据挖掘、统计学、数学基本原理和常识;二是熟练使用一门数据挖掘工具,Clementine、SAS或R都是可选项,如果是程序出身也可以选择编程实现;三是需要了解常用的数据挖掘算法以及每种算法的应用场景和优劣差异点。
5.数据分析
数据分析相对于数据挖掘更多的是偏向业务应用和解读,当数据挖掘算法得出结论后,如何解释算法在结果、可信度、显著程度等方面对于业务的实际意义,如何将挖掘结果反馈到业务操作过程中便于业务理解和实施是关键。
6.数据展现
数据展现即数据可视化的部分,数据分析师如何把数据观点展示给业务的过程。数据展现除遵循各公司统一规范原则外,具体形式还要根据实际需求和场景而定。基本素质要求如下:
工具。PPT、Excel、Word甚至邮件都是不错的展现工具,任意一个工具用好都很强大。
形式。图文并茂的基本原则更易于理解,生动、有趣、互动、讲故事都是加分项。
原则。领导层喜欢读图、看趋势、要结论,执行层欢看数、读文字、看过程。
场景。大型会议PPT最合适,汇报说明Word最实用,数据较多时Excel更方便。
最重要一点,数据展现永远辅助于数据内容,有价值的数据报告才是关键。
7.数据应用
数据应用是数据具有落地价值的直接体现,这个过程需要数据分析师具备数据沟通能力、业务推动能力和项目工作能力。
数据沟通能力。深入浅出的数据报告、言简意赅的数据结论更利于业务理解和接受,打比方、举例子都是非常实用的技巧。
业务推动能力。在业务理解数据的基础上,推动业务落地实现数据建议。从业务最重要、最紧急、最能产生效果的环节开始是个好方法,同时要考虑到业务落地的客观环境,即好的数据结论需要具备客观落地条件。
项目工作能力。数据项目工作是循序渐进的过程,无论是一个数据分析项目还是数据产品项目,都需要数据分析师具备计划、领导、组织、控制的项目工作能力。
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
商务合作|约稿 请加qq:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于数据分析师的完整流程与知识结构体系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






