本文主要是介绍Linux下软硬链接和动静态库制作详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
软硬链接
概念
软链接的创建
硬链接的创建
软硬链接的本质区别
理解软链接
理解硬链接
小结
动静态库
概念
动静态库的制作
静态库的制作
动态库的制作
前言
本文涉及到inode和地址空间等相关概念,不知道的小伙伴可以先阅读以下两篇文章了解一下哦。
Linux文件系统
Linux进程地址空间
觉得内容对你有所帮助的话可以给博主一键三连哦
你们的支持将是我继续创作的动力
如果内容有错或者不足的话,还望能指出


软硬链接
概念
软链接(Symbolic Link):是一个特殊的文件,它指向另一个文件或目录。
硬链接(Hard Link):是指向文件数据块的另一个文件名。
软链接的创建
命令:ln -s [源文件] [链接文件]
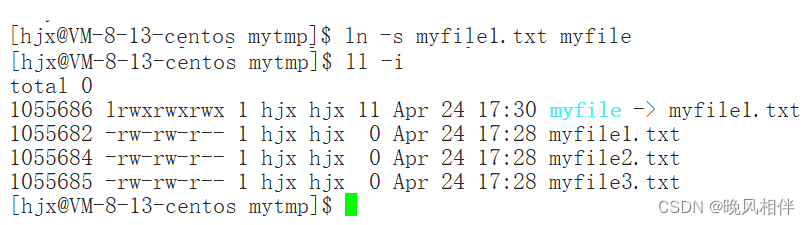
从inode编号可以看出软链接其实就是一个独立的文件。
硬链接的创建
命令:ln [源文件] [链接文件]

从inode编号可以看出这两个文件其实是同一个,只不过是不同的名字。
软硬链接的本质区别
软硬链接的本质区别就在于有没有独立的inode,软链接有独立的inode,所以软链接是一个独立的文件;硬链接没有独立的inode,所以硬链接不是一个独立的文件。可以这么理解软链接就相当于你在windows下给一个应用创建了一个快捷方式;硬链接就相当于你将一个文件拷贝了一下并且改了一下文件名。
理解软链接
软链接创建时会被占用一定的磁盘空间,它只是一个指向原始文件或目录的指针,如果原始文件或目录被删除,软链接仍然存在,但无法访问到真正的文件或目录。

理解硬链接
创建硬链接没有独立的inode,所以不是真正的创建了一个新文件,所以硬链接不占用空间。实际上创建硬链接就是在指定的目录下建立了不同文件名和指定inode的映射关系仅此而已。
再来看看下面的实验
在创建硬链接后,硬链接数由1变为了2

删除文件后,硬链接数由2变为了1

也可以用unlink进行删除。
如何理解这里的硬链接数呢?
其实这个硬链接数就是一个引用计数和C++智能指针中的shared_ptr差不多,当创建一个硬链接时,硬链接数会+1,删除文件时也只是在目录中将文件名和inode的映射关系删掉,并且把硬链接数-1,而inode还在并没有被删掉,只有当硬链接数减为0时才是真正意义上的将文件删掉了。
那么我们创建一个目录看一下硬链接数又会有什么现象?

为什么这个默认创建的目录,硬链接数是2呢?
在默认创建的目录下会有两个默认的文件.和..

默认创建的目录硬链接数是2,是因为:自己目录名和inode建立了映射关系,自己目录下的.和inode也建立了关系,所以这个.表示的是当前目录(所表示的就是tmp,只不过名字不同罢了)。
在这个tmp目录下,再创建一个目录硬链接数又会发生什么变化呢?

硬链接数由2变为了3

从上图中可以看到dir目录下的..的inode编号是不是和tmp的inode编号一样,所以硬链接数由2又变为了3的原因是在dir目录下的..和指定的tmp的inode也建立了映射关系,而..代表的就是上级目录(所表示的也是tmp,只不过名字不同罢了),所以你在 cd ..时会返回到上级目录。
小结
- 硬链接就是同一文件的不同文件名,创建硬链接就是在指定目录下建立了不同文件名和指定inode的映射关系仅此而已。
- 软链接是一个独立的文件,相当与创建了一个快捷方式。
- 在默认创建的目录下会有两个默认的文件.和..,.代表的就是当前目录,..代表的就是上级目录。
- 硬链接数本质是一个引用计数。
动静态库
概念
静态库(.a结尾):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库
动态库(.so结尾):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
动态链接
一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码,在可执行文件开始运行以前,外部函数的机器码有操作系统从磁盘上的该动态库中复制道内存中,这个过程称为动态链接(dynamic linking)。动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
静态链接
静态链接是一种将程序所需的所有库函数和外部模块都在编译时候链接到最终的可执行文件中的链接方式。在静态链接中,编译器将程序中所有用到的库函数和外部模块的代码复制一份到最终的可执行文件中,使得最终的可执行文件可以独立运行,不依赖于系统中是否存在相应的库函数和外部模块。
动静态库的制作
这里就写了两个函数——一个累加函数和一个打印函数,用来演示动静态库的制作
累加函数
mymath.h///
#pragma once#include <stdio.h>extern int addToTarget(int from, int to);/mymath.c
#include "mymath.h"int addToTarget(int from, int to)
{int sum = 0;for(int i = from; i <= to; i++){sum += i;}return sum;
}
打印函数
myprint.h///
#pragma once#include <stdio.h>
#include <time.h>extern void Print(const char *str);myprint.c///#include "myprint.h"void Print(const char *str)
{printf("%s[%d]\n", str, (int)time(NULL));
}静态库的制作
制作的静态库要能被对方使用必须得将上面两个函数编译生成.o文件(目标文件),之后将编译好的.o文件和写好的.h文件打包给别人,别人就能使用了。

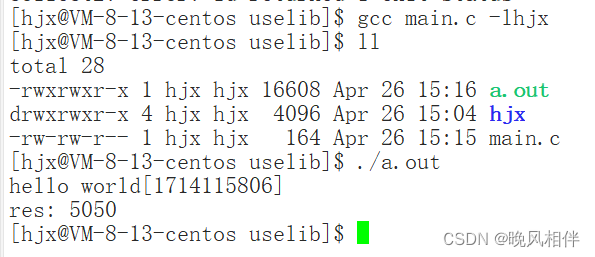
main.c
#include "myprint.h"
#include "math.h"int main()
{Print("hello world");int res = addToTarget(1, 100);printf("res: %d\n", res);return 0;
}将上面生成的两个.o文件和main.o文件共同链接形成可执行程序

虽然说这样的gcc写法是可以的,但是如果文件一多,编译的时候要把那么多的.o文件都写上去实在是太麻烦了。所以我们可以使用命令ar -rc将两个函数生成的.o文件进行归档。
ar(archive 归档)是gnu归档工具,rc表示的是(replace and create)
制作静态库

libhjx.a就是将mymath.o和myprint.o归档后生成的静态库,前面的lib和.a后缀是必带的,而hjx是这个静态库的名字(下面的动态库也是一样的)。所以使用ar -rc归档的过程就是在制作静态库。
查看静态库中的目录列表
t:列出静态库中的文件
v:详细信息
但是我们还想让它自动化的帮我们生成.o文件和静态库,那就需要使用makefile了。
编写makefile
libhjx.a:mymath.o myprint.oar -rc libhjx.a mymath.o myprint.o
mymath.o:mymath.cgcc -c mymath.c -o mymath.o
myprint.o:myprint.cgcc -c myprint.c -o myprint.o.PHONY:clean
clean:rm -rf *.o libhjx.a
我们要怎么将我们制作好的静态库给别人使用呢?
通常情况下,我们会弄一个目录,比如就叫做hjx,目录中包含一个include目录和一个lib目录,include目录下都是库的所有头文件,而lib目录下是对应的静态库文件。最后将这个目录打包给对方使用
因此我们编写的makefile还要添加自动化打包功能
libhjx.a:mymath.o myprint.oar -rc libhjx.a mymath.o myprint.o
mymath.o:mymath.cgcc -c mymath.c -o mymath.o
myprint.o:myprint.cgcc -c myprint.c -o myprint.o.PHONY:hjx
hjx:mkdir -p hjx/lib mkdir -p hjx/includecp -rf *.h hjx/includecp -rf *.a hjx/lib .PHONY:clean
clean:rm -rf *.o libhjx.a hjx
这样就不需要敲太多指令了,全部交给makefile自动帮我们生成了。

对方拿到了我们的这个hjx目录之后要怎么使用呢?
方法一:将我们的静态库拷贝到系统路径中
头文件gcc的默认搜索路径是:/usr/include
库文件的默认搜索路径是:/lib64 或者 /usr/lib64
所以我们要把我们的头文件拷贝到/usr/include下,库文件拷贝到/lib64下
- 拷贝头文件
- 拷贝库文件
在编译的时候我们要带上静态库名来表示我们要链接哪个静态库
-l:指定库名
而我们上面拷贝头文件和库文件到系统的默认路径下就叫做库的安装
但是这种方法还是不可取的,因为你写的库是没有做任何可靠性验证测试的,而系统的库都是经过大佬们精心打磨过的,你把你写的库拷贝到系统中可能就会造成库的污染。
方法二:手动指定静态库路径和头文件路径
gcc main.c -I ./hjx/include/ -L ./hjx/lib/ -lhjx
-I:指定路径搜索头文件
-L:指定库路径
注:一定要加上库名因为你lib目录下的库文件如果有很多,gcc就不知道你究竟要链接哪个库了,所以gcc要求带上库名指定你要链接哪个库。



动态库的制作
和静态库制作那里一样,我们也是要生成.o文件但是在使用gcc生成的时候要加-fPIC选项表示生成位置无关代码。

然后再用这里的.o文件来制作我们的动态库。在终端输入以下命令
gcc -shared myprint_d.o mymath_d.o -o libhjx.so这里的-shared选项表示的是生成动态库。
同样的这样让我们手动去将文件一个个写上去太麻烦了,所以我们需要重新编写makefile,让它自动化生成。
.PHONY:all
all:libhjx.so libhjx.alibhjx.so:mymath_d.o myprint_d.ogcc -shared mymath_d.o myprint_d.o -o libhjx.so
mymath_d.o:mymath.cgcc -c -fPIC mymath.c -o mymath_d.o
myprint_d.o:myprint.cgcc -c -fPIC myprint.c -o myprint_d.olibhjx.a:mymath.o myprint.oar -rc libhjx.a mymath.o myprint.o
mymath.o:mymath.cgcc -c mymath.c -o mymath.o
myprint.o:myprint.cgcc -c myprint.c -o myprint.o.PHONY:output
output:mkdir -p output/lib mkdir -p output/includecp -rf *.h output/includecp -rf *.a output/lib cp -rf *.so output/lib .PHONY:clean
clean:rm -rf *.o *.a *.so output使用动态库
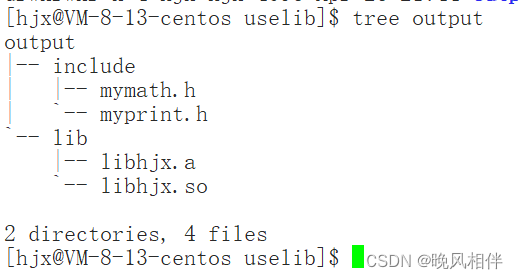
可以看到output文件中是我们制作的动态库
![]()
我们和静态库一样,手动指定库路径和头文件路径,但是静态库和动态库的名字都是一样的,那么gcc会使用哪一个库呢?

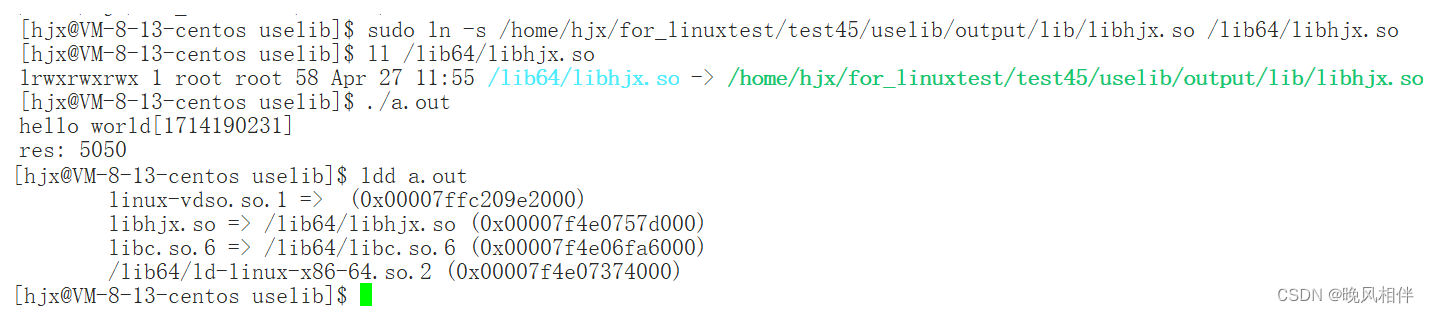
可以看到当我们运行生成的可执行程序时报错了,报错的内容是不能打开动态库,并且使用ldd来查看链接的动态库时法相libhjx.so没有找。但是我们可以得出结论gcc默认优先使用的是动态库,既然gcc默认优先使用的是动态库,那么我们想使用静态库怎么办,可以加-static选项。
gcc main.c -I ./output/include/ -L ./output/lib/ -lhjx -static-static的意义:摒弃默认优先使用动态库的原则,而是直接使用静态库的方案。
可是话说回来为什么上面会报错呢,output里面明明就有动态库啊?
首先要了解我们的可执行程序和动态库是分批加载的,可执行程序加载时,是先到地址空间中的代码区,然后通过页表映射到内存中,当我们的动态库加载时,先到内存中,然后通过页表映射到地址空间中的共享区(共享区存放的是库的起始加载虚拟地址+函数的偏移量),之后操作系统就可以通过共享区来拿到我们的动态库。因此虽然我们指出了动态库路径,但是是给gcc指出的,而我们的操作系统并不知道动态库在哪,所以导致了运行的时候会报错。

那么我们该怎样正确的使用动态库呢?
方法一:将我们的动态库拷贝到系统路径中
这个方法在静态库的制作那里演示过了,这里就不再演示了。
方法二:将动态库的路径添加到环境变量LD_LIBRARY_PATH中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:动态库路径注意:一定要加上之前的环境变量并且带上冒号进行分隔,否则之前的环境变量会被覆盖掉。

所以我们的动态库路径就添加进环境变量LD_LIBRARY_PATH了。
那么我们再运行一下试试
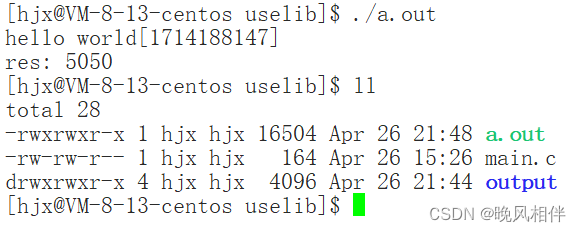
运行成功了
但是这个方法有个缺点,它只在本次登录有效,你下次登录时你添加的环境变量就会被抹去。
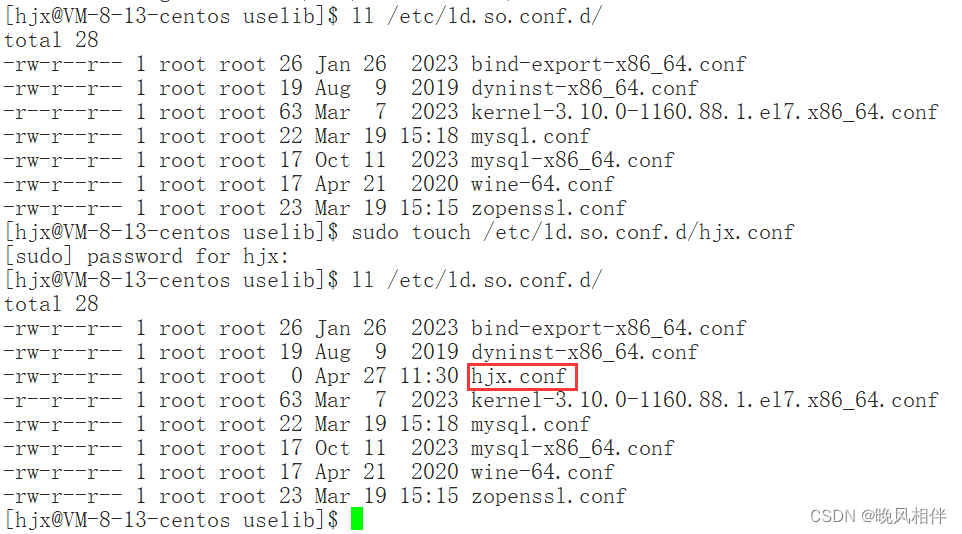
方法三:创建.conf文件将动态库的路径添加到/etc/ld.so.conf.d/目录下
1、创建hjx.conf文件
2、将动态库路径添加到/etc/ld.so.conf.d/hjx.conf中
3、ldconfig将我们的配置文件生效一下
这个方法可以永久有效


方法四:建立软链接
除了以上的方法外,还有其它方式可以用比如修改系统的配置文件等等。有兴趣的小伙伴可以自己去了解一下。
最后再来回答最后一个问题:为什么要有库呢?
站在使用库的角度,库的存在可以减少我们的开发周期,极大地提高开发效率,避免重复造轮子,同时也能够利用已有的经过测试和优化的代码提高系统的性能和稳定性。
站在编写库的人的角度,库使用起来非常简单,方便开发人员进行快速开发,并且库中的实现对方看不到,从而实现了代码的安全。此外库只需提供一些标准的接口和协议,就可以使不同的组件和系统之间能够进行有效的通信和交互。
这篇关于Linux下软硬链接和动静态库制作详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







