本文主要是介绍基于matlab的文字识别算法-课程设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于MATLAB的文字识别系统
一、课题介绍
本设计主要运用MATLAB的仿真平台设计进行文字识别算法的设计与仿真。也就是用于实现文字识别算法的过程。从图像中提取文字属于信息智能化处理的前沿课题,是当前人工智能与模式识别领域中的研究热点。由于文字具有高级语义特征,对图片内容的理解、索引、检索具有重要作用,因此,研究图片文字提取具有重要的实际意义。又由于静态图像文字提取是动态图像文字提取的基础,故着重介绍了静态图像文字提取技术。随着计算机科学的飞速发展,以图像为主的多媒体信息迅速成为重要的信息传递媒介,在图像中,文字信息(如新闻标题等字幕)包含了丰富的高层语义信息,提取出这些文字,对于图像高层语义的理解、索引和检索非常有帮助。
二、课题实现功能
图像文字提取又分为动态图像文字提取和静态图像文字提取两种,其中,静态图像文字提取是动态图像文字提取的基础,其应用范围更为广泛,对它的研究具有基础性,所以本文主要讨论静态图像的文字提取技术。静态图像中的文字可分成两大类:一种是图像中场景本身包含的文字, 称为场景文字; 另一种是图像后期制作中加入的文字,称为人工文字,如右图所示。场景文字由于其出现的位置、小、颜色和形态的随机性,一般难于检测和提取;而人工文字则字体较规范、大小有一定的限度且易辨认,颜色为单色,相对与前者更易被检测和提取,又因其对图像内容起到说明总结的作用,故适合用来做图像的索引和检索关键字。对图像中场景文字的研究难度大,目前这方面的研究成果与文献也不是很丰富,本文主要讨论图像中人工文字提取技术。
其流程如图所示。
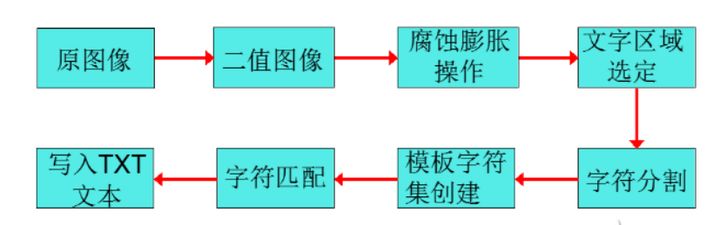
图1 静态文字处理流程图
四、源码
文字识别算法仿真代码如下:
function [Stroke]= StrDetect01(LeftD,Y1,Y2,ST,PT)
% ST为结构阈值,为了指定高度和宽度结构变化的不同
SL=0;
SR=0;
SV=0;
Count=0;
%PT=5; % 突变的阈值
Str='T'; % T表示结构未定,Str用于保存当前的基本结构
Stroke='T'; % 用于保存基本结构
Range=Y2-Y1+1; % 字符的宽度或者高度
for j=Y1:Y2Count=Count+1;if (abs(LeftD(j))<PT)if (LeftD(j)<0)SL=SL+1;else if (LeftD(j)>0)SR=SR+1;elseSV=SV+1;endend else % 检测到突变的决策if ((Count>=fix(Range/4)+1)) % 设定字符轮廓可能发生的突变范围if ((SL>=3)&&(SR>=3))Str='C';else if ((SV>=2*(SL+SR))&&((max(SL,SR)<3)||(min(SL,SR)<2)))Str='V';else if ((SL>SR)&&((SL>=0.5*SV)&&((SR<=1)||(SL>(SR+SV)))))Str='L';else if ((SR>SL)&&((SR>=0.5*SV)&&((SL<=1)||(SL>(SR+SV)))))Str='R';else if (max(SL,SR)>=3)&&(min(SL,SR)>=2) Str='C';endendendendendStroke=[Stroke Str]; endif ((j>=2+Y1)&&((j<=Y2-2)))Stroke=[Stroke 'P'];end SL=0;SR=0;SV=0;Count=0;Str='T';end
end
%========= 提取结构 ===============%
if (Count>=fix(Range/4)+1) % 发生突变后,剩余部分可能无法形成字符结构
if ((SL>=ST)&&(SR>=ST))Str='C';
else if ((SV>=2*(SL+SR))&&((max(SL,SR)<3)||(min(SL,SR)<2)))Str='V';else if ((SL>SR)&&((SL>=0.5*SV)&&((SR<=2)||(SL>=(SR+SV)))))Str='L';else if ((SR>SL)&&((SR>=0.5*SV)&&((SL<=2)||(SL>=(SR+SV)))))Str='R';else if (max(SL,SR)>=3)&&(min(SL,SR)>=2) Str='C';end endendendend
Stroke=[Stroke Str];
function [Numeral]=Recognition(StrokeTop,StrokeLeft,StrokeRight,StrokeBottom,Comp)
% 采用四边的轮廓结构特征和笔划统计(仅针对 0 和 8)识别残缺数字
% Comp 是用于识别 0和8 的底部补充信息
StrT='T';
StrL='T';
StrR='T';
StrB='T';
RStr='T'; % 用于保存识别出的数字
[temp XT]=size(StrokeTop);
[temp XL]=size(StrokeLeft);
[temp XR]=size(StrokeRight);
%[temp XB]=size(StrokeBottom);
for Ti=2:XTif (StrokeTop(Ti)=='C')if ((XL==2)&&(XR==2))if ((Comp>=3)||((StrokeBottom(2)~='C')&&(StrokeLeft(2)=='C')&&(StrokeRight(2)=='C')))RStr='8';elseRStr='0';end else if ((StrokeLeft(XL)=='L')&&(StrokeLeft(XL-1)=='P')&&(StrokeLeft(2)~='C'))RStr='2';else if ((StrokeLeft(2)=='C')&&(XL>=3)&&(StrokeLeft(3)=='P'))RStr='9';else if (XL>2)for Li=2:XLif (StrokeLeft(Li)=='P')RStr='3';endendelse if (XL==2)for Ri=2:XR-1if (StrokeRight(Ri)=='P')RStr='6';endendend end end endend else if (StrokeTop(Ti)=='V') % Topif ((XR==2)&&(StrokeRight(2)=='C')) % 数字 3 右端只有一个结构RStr='3'; else if ((XR==2)&&((StrokeLeft(2)=='P')||(StrokeLeft(3)=='P')||(StrokeLeft(XL)=='V')))RStr='7';else if (XR>2)for Ri=2:XRif (StrokeRight(Ri)=='P')RStr='5';endendendend
I0=imread('8.jpg');% 必须为二值图像
I=im2bw(I0,0.4);
[y0 x0]=size(I);
Range=sum((~I)');
Hy=0;
for j=1:y0if (Range(j)>=1)Hy=Hy+1;end
end
RangeX=sum((~I));
Wx=0;
for i=1:x0if (RangeX(i)>=1)Wx=Wx+1;end
end
Amp=24/Hy; % 将文字图像归一化到24像素点的高度。
I=imresize(I,Amp);
[y x]=size(I);
%I=bwmorph(~I,'skel',Inf);
%I=~I;
tic
%====== 基本结构 =======%
% 第一类:竖(V);左斜(L);右斜(R);突变(P)
% 第二类:左半圆弧(C);右半圆弧(Q)
% 的三类:结构待定(T);
%=====================================%
Left=zeros(1,y); % 左端轮廓检测
for j=1:yi=1;while ((i<=x)&&(I(j,i)==1))i=i+1;endif (i<=x) Left(j)=i;end
end
for j=1:y-1LeftD(j)=Left(j+1)-Left(j);
end
%========== 结构特征提取 =============%
j=1;
while ((Left(j)<1)&&(j<y))j=j+1;
end
Y1=j;
j=y;
while ((Left(j)<1)&&(j>1))j=j-1;
end
Y2=j-1; % 去掉急剧变化的两端
%============== 右边 ==================%
Right=zeros(1,y); % 左端轮廓检测
for j=1:yi=x;while ((i>=1)&&(I(j,i)==1))i=i-1;endif (i>=1) Right(j)=i;end
end
for j=1:y-1RightD(j)=Right(j+1)-Right(j);
end
%=====================================%
Top=zeros(1,x); % 顶端轮廓检测
for i=1:xj=1;while ((j<=y)&&(I(j,i)==1))j=j+1;endif (j<=y) Top(i)=j;end
end
for i=1:x-1TopD(i)=Top(i+1)-Top(i);
end
%==============================%
i=1;
while ((Top(i)<1)&&(i<x))i=i+1;
end
X1=i;
i=x;
while ((Top(i)<1)&&(i>1))i=i-1;
end
X2=i-1; % 去掉急剧变化的两端%===================================%
Bottom=zeros(1,x); % 底部轮廓检测
for i=1:x-1BottomD(i)=Bottom(i+1)-Bottom(i);
end
%========== 数字 1 的宽度特征 =========%
Width=zeros(1,y);
for j=1:yWidth(j)=Right(j)-Left(j);
end
W=m
五 实现仿真结果
5.1 文字识别算法仿真结果
识别原图如图9(a)所示,仿真结果如图9(b)所示。
图9(a)识别原图
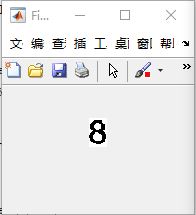
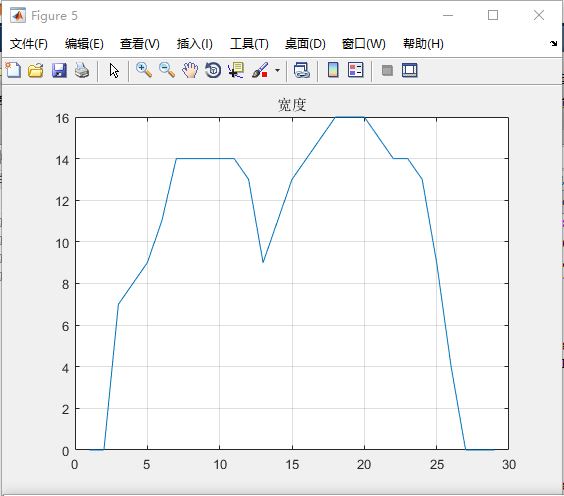
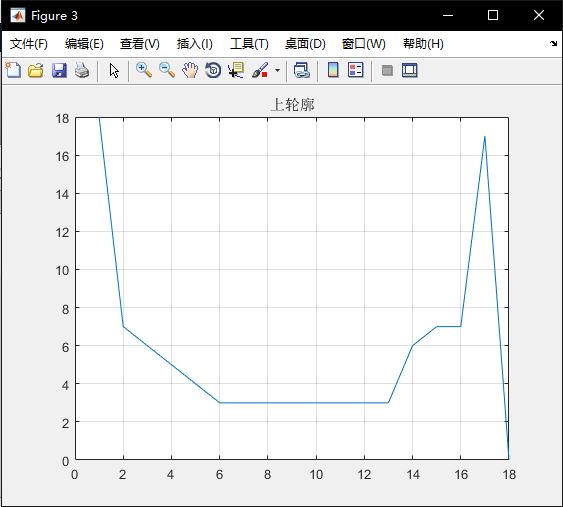
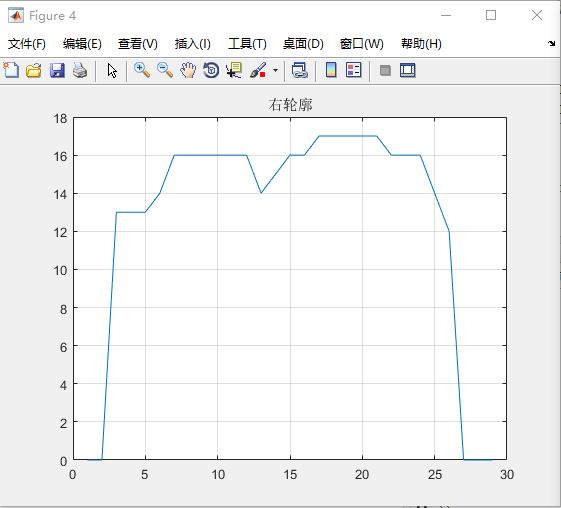
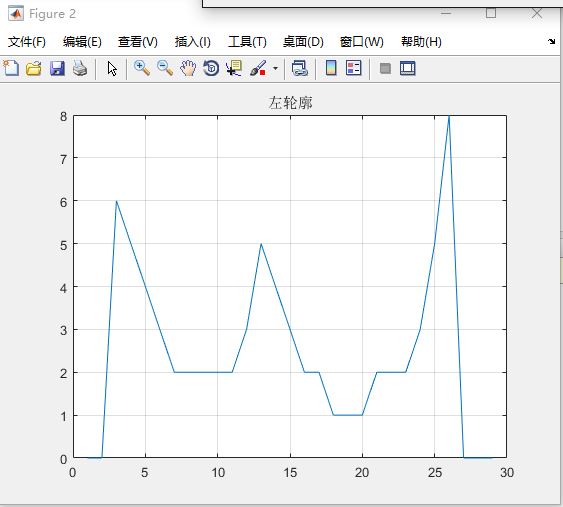
图9(b) 仿真结果
这篇关于基于matlab的文字识别算法-课程设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








