本文主要是介绍MySQL技术内幕InnoDB存储引擎 学习笔记 第二章 InnoDB存储引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
InnoDB由Innobase Oy公司开发,是第一个支持ACID事务的MySQL存储引擎(BDB是第一个支持事务的MySQL存储引擎,现已停止开发),具有行锁设计,支持MVCC,提供Oracle风格的一致性非锁定读,支持外键,被设计用来最有效地利用内存和CPU。
Oracle是多进程架构(Windows下除外),核心后台进程有多个,分别负责数据库写、日志写、检查点进程等,InnoDB是多线程架构,它的master thread几乎实现了所有Oracle核心进程的功能。
InnoDB默认有七个线程,四个IO thread,一个master thread,一个锁监控线程,一个错误监控线程,IO thread的数量由innodb_file_io_threads参数控制(只有Windows上能控制IO threads的数量),默认为4。查看InnoDB状态:
SHOW ENGINE INNODB STATUS\G
运行它:
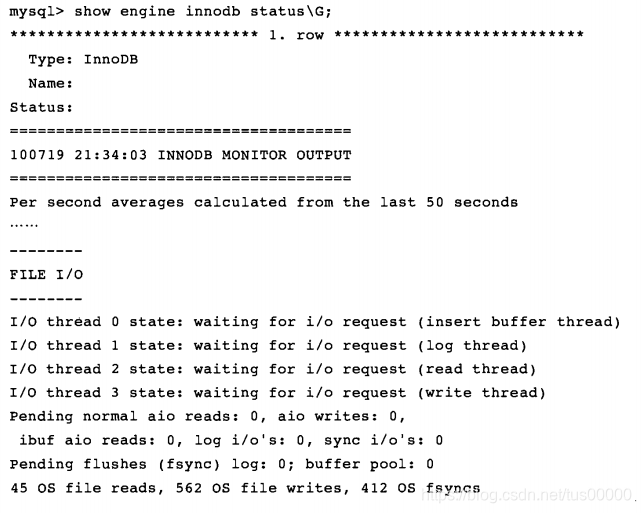
可见四个IO线程分别是insert buffer thread、log thread、read thread、write thread。Linux上IO thread的数量不能调整。
InnoDB Plugin版本开始增加默认IO thread的数量,默认的read thread和write thread分别增大到四个,且不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_threads和innodb_write_io_threads参数。
查看InnoDB版本:
SHOW VARIABLES LIKE 'innodb_version';
查看InnoDB读写线程个数:
SHOW VARIABLES LIKE 'innodb_%io_threads';
InnoDB内存由缓冲池(innodb_buffer_pool_size配置文件参数控制大小)、重做日志缓冲池(innodb_log_buffer_size配置文件参数控制大小)、额外缓冲池组成。
显示缓冲池的大小(字节数):
SHOW VARIABLES LIKE 'innodb_buffer_pool_size'; # 缓冲池大小
SHOW VARIABLES LIKE 'innodb_log_buffer_size'; # 重做日志缓冲池大小
SHOW VARIABLES LIKE 'innodb_additional_mem_pool_size'; # 额外内存池大小
运行它:
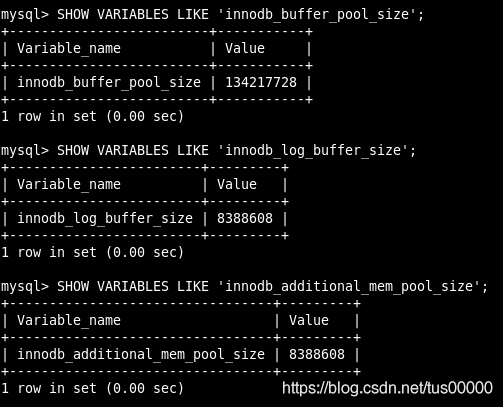
缓冲池是占内存最大的部分,存放各种数据的缓存。InnoDB总是将数据库文件按页(每页16k)读取到缓冲池,然后用最近最少使用(LRU)算法保留在缓冲池中的缓存数据,如果数据库文件需要修改,总是先修改在缓存池中的页(发生修改的页为脏页),然后再按一定频率将缓冲池的脏页刷新到文件。
查看缓冲池使用情况:
SHOW ENGINE INNODB STATUS\G
运行后可在BUFFFER POOL AND MEMORY栏中看到以下内容:
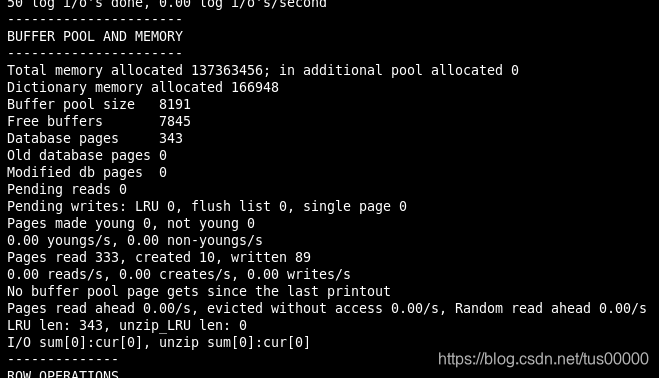
Buffer pool size指缓冲帧数量,每个buffer frame为16k。Free buffers指空闲的缓冲帧数量。Database pages表示已用的缓冲帧数量。Modifyed db pages表示脏页数量。
以上命令显示的不是当前状态,而是过去某个时间范围内InnoDB的状态,上例的运行结果中还有以下语句:

说明是过去7秒内的平均状态。
缓冲池中缓存的数据页类型有索引页、数据页、undo页、插入缓冲、自适应哈希索引、InnoDB存储的锁信息、数据字典信息。索引页和数据页占缓冲池很大一部分。
32位Windows下参数innodb_buffer_pool_awe_mem_mb可启用地址窗口扩展(AWE)功能,突破32位下对于内存使用的限制,但一旦开启AWE功能,将自动禁用自适应哈希索引功能。
 重做日志信息会先放入日志缓冲区,然后按一定频率将其刷新到重做日志文件,该值一般不需要很大,因为一般一秒就会将重做日志缓冲刷新到日志文件,只需保证每秒产生的事务量在这个缓冲大小内即可。额外的内存池经常被DBA忽略,但其值非常重要,InnoDB对内存的管理是通过一种称为内存堆的方式进行的,给一些数据结构分配内存时,需要从额外的内存池中申请,该区域内存不够时,会从缓冲池申请。缓冲池中的帧缓冲有对应的缓冲控制对象,这些对象记录了如LRU、锁等方面的信息,此对象需要从额外内存池中申请,因此,当申请了很大的缓冲池时,也应增大额外内存池大小。
重做日志信息会先放入日志缓冲区,然后按一定频率将其刷新到重做日志文件,该值一般不需要很大,因为一般一秒就会将重做日志缓冲刷新到日志文件,只需保证每秒产生的事务量在这个缓冲大小内即可。额外的内存池经常被DBA忽略,但其值非常重要,InnoDB对内存的管理是通过一种称为内存堆的方式进行的,给一些数据结构分配内存时,需要从额外的内存池中申请,该区域内存不够时,会从缓冲池申请。缓冲池中的帧缓冲有对应的缓冲控制对象,这些对象记录了如LRU、锁等方面的信息,此对象需要从额外内存池中申请,因此,当申请了很大的缓冲池时,也应增大额外内存池大小。
master thread的线程优先级别最高,其内部由几个循环组成:主循环(loop)、后台循环(background loop)、刷新循环(flush loop)、暂停循环(suspend loop),会根据数据库运行的状态在这几个循环中进行切换。
loop循环中有两大操作:每秒钟的操作和每十秒的操作。loop循环通过thread sleep实现,意味着每秒或每十秒一次的操作不精确,负载大时可能会有延迟。
loop循环的每秒一次的操作包括:
1.日志缓冲刷新到磁盘,即使这个事务还没有提交。这解释了为什么再大的事务commit的时间也是很快的。
2.可能合并插入缓冲。InnoDB会判断当前一秒内发生的IO次数是否小于五次,如果是,则认为当前IO压力很小,可以执行合并插入缓冲的操作。
3.最多刷新100个InnoDB的缓冲池中的脏页到磁盘。InnoDB判断当前缓冲池中脏页的比例(buf_get_modified_ratio_pct)是否超出了配置文件中innodb_max_dirty_pct参数(默认为90,表示百分之90),如果是,InnoDB认为需要做磁盘同步操作,将100个脏页写入磁盘。
4.如果当前没有用户活动,切换到background loop。
loop循环的每十秒一次的操作:
1.可能刷新100个脏页到磁盘。InnoDB会先判断过去十秒内磁盘的IO操作是否小于200次,如果是,则认为有足够的磁盘IO能力,因此将100个脏页刷新到磁盘。
2.合并最多五个插入缓冲。
3.将日志缓冲刷新到磁盘。
4.删除无用的Undo页。对表执行update、delete这类操作时,原先的行被标记为已删除,但由于一致性读,需要保留这些行的这些版本的信息,但在full purge(删除无用Undo页)过程中,InnoDB会判断当前事务系统中已被删除的行是否可以删除(有时可能还有查询操作需要读取之前版本的Undo信息),每次最多删除20个Undo页。
5.刷新100个或10个脏页到磁盘。InnoDB会判断缓冲池中脏页比例,如果超过70%,则刷新100个脏页到磁盘,否则只刷新10个脏页到磁盘。
6.产生一个检查点。InnoDB的检查点也被称为模糊检查点,在checkpoint时不会将所有缓冲池中的脏页都写入磁盘,只将最老日志序列号的页写入磁盘。
background loop执行以下操作:
1.删除无用Undo页。
2.合并20个插入缓冲。
3.不断刷新100个页,直到符合条件,之后跳转到flush loop中完成。
4.跳回主循环。
如果flush loop中也没什么事情可做了,会切换到suspend_loop将master thread挂起,等待事件发生,若启用了InnoDB引擎,却没有使用InnoDB表,则master thread总是处于挂起状态。
master thread伪代码:
void master_thread() {goto loop;
loop:for (int i = 0; i < 10; ++i) {thread_sleep(1);do log buffer flush to diskif (last_one_second_ios < 5)do merge at most 5 insert bufferif (buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct)do buffer pool flush 100 dirty pageif (no user activity)goto background loop;}if (last_ten_second_ios < 200)do buffer pool flush 100 dirty pagedo merge at most 5 insert bufferdo log buffer flush to diskdo full purgeif (buf_get_modified_retio_pct > 70%)do buffer pool flush 100 dirty pageelsebuffer pool flush 10 dirty pagedo fuzzy checkpointgoto loop;background loop:do full purgedo merge 20 insert bufferif not idle:goto loop;else:goto flush loop;flush loop:do buffer pool flush 100 dirty pageif (buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct)goto flush loop;goto suspend loop;suspend loop:suspend_thread();waiting eventgoto loop;
}
从InnoDB Plugin开始,可用SHOW ENGINE INNODB STATUS查看当前master状态信息:
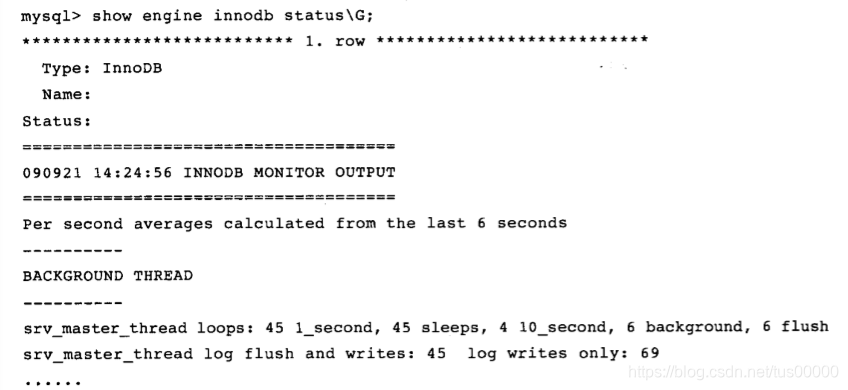
可见主循环运行了45次,每秒的sleep操作执行了45次(说明负载不是很大,负载大时,InnoDB优化使得sleep时间短于1秒),十秒一次的活动执行了四次,符合1:10,background loop执行了6次,flush loop执行了6次,这台服务器负载比较小,能在理论值运行,如果在一台压力很大的服务器上,可能是以下情景:
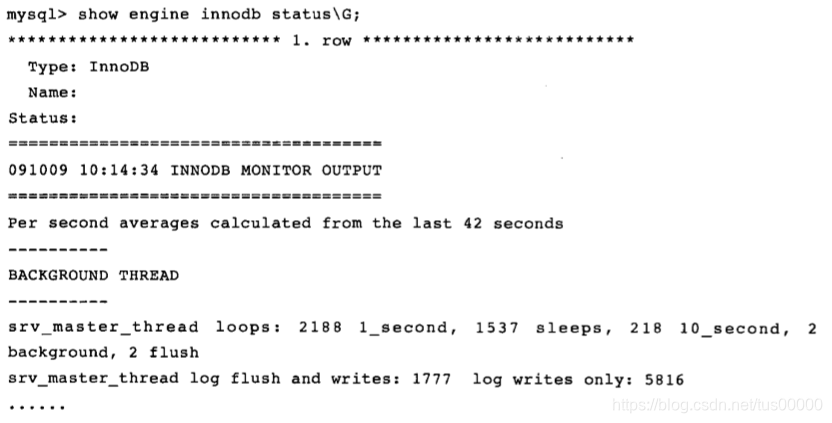
可见主循环运行了2188次,但每秒一次的sleep只运行了1537次。可通过主循环次数和每秒一次的sleep操作次数的差值反应数据库的负载。
InnoDB Plugin版本是MySQL 5.1版本及其之后的InnoDB引擎。
InnoDB对于IO是有限制的,在缓冲池向磁盘刷新时做了一定的硬性规定,在当前磁盘技术飞速发展,尤其是固态磁盘出现的情况下,这种规定限制了InnoDB的磁盘IO性能,尤其是写入性能。
InnoDB每秒最多只会刷新100个脏页到磁盘,合并最多20个插入缓冲,如果是密集写的应用,每秒可能产生大于100个脏页或大于20个插入缓冲,即使磁盘可以承受更多IO,但InnoDB的硬性规定也只能写入这么多,导致发生宕机后需要恢复时,由于很多数据还没刷新回磁盘,可能恢复地会慢,尤其对于insert buffer。
由于以上缺陷,InnoDB Plugin开始提供参数innodb_io_capacity,用来表示磁盘IO吞吐量,默认值为200,该参数含义如下:
1.在合并插入缓冲时,合并的数量为innodb_io_capacity数值的5%。
2.刷新脏页时,最大刷新脏页数量为innodb_io_capacity。
如果使用了SSD或使用几块磁盘做了RAID,完全可将innodb_io_capacity的值调高点。
在MySQL 5.1之前,innodb_max_dirty_pages_pct默认值为90,即脏页占缓冲池的90%,只有当每秒或flush loop判断脏页百分比大于该值时,才刷新100个脏页,因此当内存很大或数据库压力很大(无法进入flush loop)时,刷新脏页速度反而会降低。在数据库恢复阶段可能需要更多时间。有人将此值调到10或20时,发现性能会有所提高,但会增加磁盘压力,增加系统负担。从InnoDB Plugin开始,此值默认变为75,既可加快脏页刷新频率,也能保证磁盘IO负载。
InnoDB Plugin带来了innodb_adaptive_flushing(自适应刷新)参数,影响每秒刷新脏页的数量。之前如果脏页在缓冲池占比小于innodb_max_dirty_pages_pct,不刷新脏页,大于innodb_max_dirty_pages_pct时,刷新100个脏页。而参数innodb_adaptive_flushing的引入,InnoDB会通过名为buf_flush_get_desired_flush_rate的函数判断刷新脏页最合适的数量,此函数通过重做日志的产生速度判断最合适的脏页刷新数量,当脏页比例小于innodb_max_dirty_pages_pct时,也会刷新一定量的脏页。
插入缓冲和数据页一样,也是物理页的组成部分。
聚集索引按主键确定记录顺序,因此只能有一个聚集索引,但一个聚集索引中可以含多个列。
一张表上可能有多个非聚集索引(辅助索引),非聚集索引页是离散的,访问时性能较低,B+树的特性决定了非聚集索引插入的离散性。InnoDB开创性地设计了插入缓冲,对于非聚集索引的插入或更新操作,不是每次直接插入索引页中,而是先判断要插入或更新的非聚集索引页是否在缓冲池,如在,直接插入,否则,先将修改放入一个插入缓冲区,表面上这个非聚集索引已经插入到叶子节点,然后再以一定频率执行插入缓冲和非聚集索引页子节点的合并操作,这样通常能将多个插入合并到一个操作中(因为在一个索引页中),大大提高了非聚集索引插入和修改操作的性能。
插入缓冲使用条件(InnoDB自动使用):
1.索引是辅助索引。
2.索引不是唯一的。如果是唯一的,插入时需要查看是否重复,查找时又会出现离散读的情况,插入缓冲就失去了意义。
如果应用执行大量插入和更新操作,且都涉及到了不唯一的非聚集索引,如果此时数据库宕机,会有大量插入缓冲没有合并到实际的非聚集索引中,会恢复较长时间,极端情况甚至需要几个小时执行恢复操作。
查看插入缓冲信息:
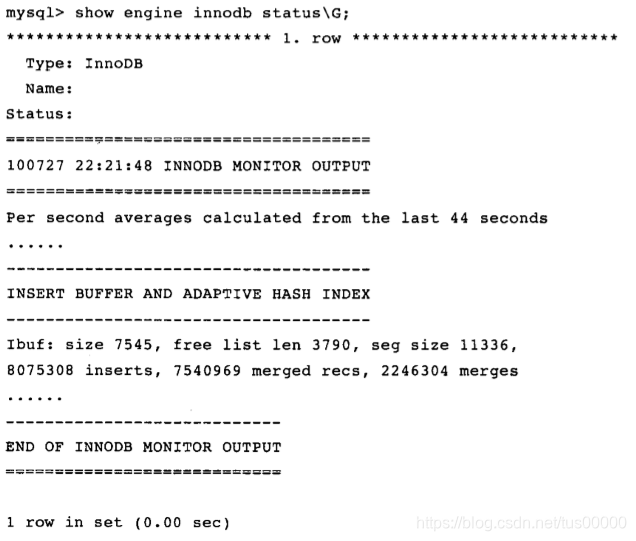
上图seg size显示当前插入缓冲大小为11336*16K,free list len代表空闲列表长度,size代表已经合并记录页的数量。下面一行中,inserts代表插入的记录数,merge recs代表合并的记录数量,merges代表合并插入缓冲的次数,merges是merged recs的大约三倍,代表插入缓冲对非聚集索引页的IO请求大约降低了三分之一。
插入缓冲的一个问题是在写密集情况下,插入缓冲会占用过多缓冲池内存,默认最大会占用50%缓冲池内存,这对其他操作可能带来影响。Percona发布了一些patch修正插入缓冲占用太多缓冲池内存的问题。
两次写机制给InnoDB带来数据可靠性。数据库宕机时,可能数据库在写一个页面,但只写了一部分,我们称之为部分写失效,InnoDB未使用double write前,出现过因为部分写失效导致数据丢失的情况。出现写失效时,可通过重做日志进行恢复,但重做日志中记录的是对页的物理操作,如果这个页已经损坏,再对其重做是无意义的,即我们在应用重做日志前,需要一个页的副本还原该页,再进行重做,这就是double write。
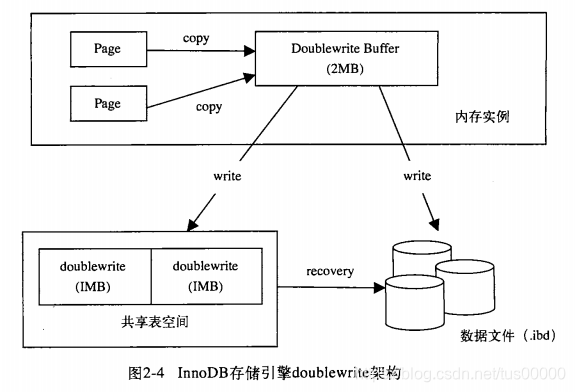
double write由两部分组成,一是内存中的double write buffer(2MB),二是物理磁盘上共享表空间中连续的128个页,即两个区,每个区1MB。
当缓冲池的脏页刷新时,并不直接写磁盘,而是通过memcpy函数将脏页先拷贝到内存中的double write buffer,之后将double write buffer分两次每次1MB写到共享表空间的物理磁盘上,然后马上调用fsync函数同步磁盘,此函数不是延迟写(延迟写将要写的内容存到输出缓冲就返回),而是等待数据真正写到磁盘上再返回。由于此过程中double write页是连续的,因此是顺序写,开销并不是很大。将double write页写入磁盘后,再将double write buffer中的页写入各个表空间文件中,此时的写入是离散的。
查看double write运行情况:
SHOW GLOBAL STATUS LIKE 'innodb_dblwr%';
运行它:

可见double write一共写了6325194个页,实际写入次数为100399次。
如果操作系统将页写入磁盘的过程中崩溃了,在恢复时,InnoDB从共享表空间中的double write中找到该页的一个副本,将其拷贝到表空间文件,再应用重做日志。
参数skip_innodb_doublewtite可禁止使用两次写功能,这可能会发生写失效,但如果有多台从服务器,可启用该参数提高性能。在需要提高数据可靠性的主服务器上,要开启两次写功能。
有些文件系统提供了部分写失效的防范机制,如ZFS(动态文件系统),此时就不用启用两次写了。
哈希查找很快,常用于连接(join)操作,如SQL server和Oracle中的哈希连接,但这两个数据库不支持哈希索引。MySQL的Heap存储引擎默认索引为哈希索引,而InnoDB有另一种实现方法,称为自适应哈希索引。
InnoDB会监控对表上索引的查找,如果观察到建立哈希索引后可以带来速度提升,则建立哈希索引,因此称之为自适应的。
自适应哈希索引通过缓冲池的B+树构造,因此建立速度很快,且不需要整张表都建哈希索引,InnoDB会根据访问的频率和模式为某些页建立哈希索引,其设计思想是数据库自优化。
查看当前自适应哈希索引的使用状况:
SHOW ENGINE InnoDB STATUS;
运行它:
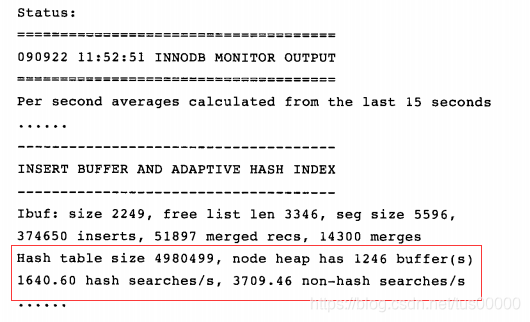
显示信息包括哈希索引大小、每秒使用自适应哈希索引搜索次数。
哈希索引只能用来搜索等值的查询,不能用于如范围查找等查找类型,上图中non-hash searches/s表示了这种情况。
由于InnoDB是MySQL的存储引擎之一,InnoDB引擎的启动和关闭更准确地是指在MySQL实例的启动过程中对InnoDB表的储存引擎的处理过程。
数据库关闭时,innodb_fast_shutdown参数影响InnoDB表的行为,该参数可取值有0、1、2,0表示MySQL关闭时要完成所有full purge和merge insert buffer,这需要一段时间,甚至需要几个小时完成;1是默认值,表示不需要完成full pruge和merge insert buffer操作,但缓冲池的脏页会刷新到磁盘;2表示不完成full purge和merge insert buffer,也不刷新缓冲池中的脏页到磁盘,只将日志都写入日志文件,这样不会丢失事务,但下次数据库启动时,会执行恢复操作。
当非正常关闭数据库,如用kill命令关闭数据库、在MySQL数据库运行时服务器重启了、关闭数据库时将参数innodb_fast_shutdown设为2,则数据库下次启动时会对InnoDB表执行恢复操作。
参数innodb_force_recovery值默认为0,表示恢复时执行所有的恢复操作,如不能恢复(如数据页发生了corruption),MySQL数据库可能会宕机,并把错误写入错误日志。
有时我们不需要执行完整恢复操作,因为我们知道如何进行恢复,如对一个表执行alter table操作时发生意外,数据库重启时会对InnoDB表执行回滚操作,对于一个大表这需要很长时间,甚至几个小时,我们可以自己恢复,如删除表,再从备份中将数据导入表中,速度可能远远快于回滚操作。
innodb_force_recovery还可设置6个非0值,大的数字包含了前面所有小数字的作用:
1(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
2(SRV_FORCE_NO_BACKGROUND):阻止主线程(其中含purge操作)和purge threads的运行,这个值可在执行full purge操作将会导致crash时使用。
3(SRV_FORCE_NO_TRX_UNDO):不执行事务回滚操作(即不对数据库崩溃时还未提交的事务进行回滚)。
4(SRV_FORCE_NO_IBUF_MERGE):不执行插入缓冲合并操作。
5(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看undo log,InnoDB将未提交的事务视为已提交。
6(SRV_FORCE_NO_LOG_REDO):不执行重做日志前滚操作(即不将重做日志应用到数据文件,数据页会是过时的)。
将innodb_force_recovery设为大于0的值后,只能对表执行select、create、drop操作,增删改不被允许。
模拟innodb_force_recovery为0时故障的发生:
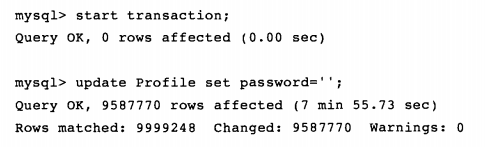
先开启事务,防止了自动提交的发生,同时update操作产生了大量重做日志,此时kill掉MySQL:
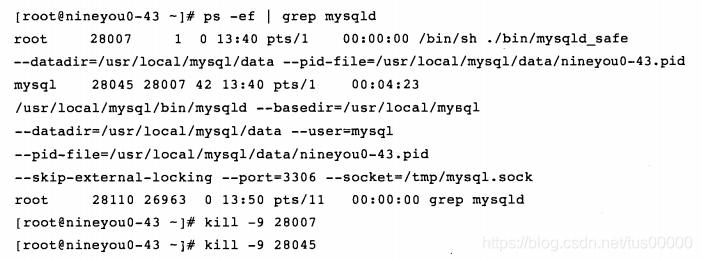
MySQL再次启动时,会对这个update事务执行回滚操作,这些信息记录在错误日志中,默认后缀名为err,查看错误日志可得到:

可见此次回滚了8867280行记录,总耗时从13:40:20到13:49:21,用了九分多钟。
再次模拟以上数据库宕机过程,但此次的innodb_force_recovery设为3,之后错误日志可看到:

数据库发出了三个叹号的警告,提示用户不会进行undo的回滚了。数据库会很快启动,但用户需要查看数据库状态,确认是否不需要回滚。
MySQL 5.1开始采用了插件式的架构,源码中每个存储引擎都是通过一个handler的C++基类实现(之前版本大多是通过函数指针实现)。这样设计的好处是所有的存储引擎都是真正的插件式了,以前如果发现InnoDB的一个bug,需要等待MySQL新版本发布,下载后还需重新编译MySQL,但现在可以下载新版本的InnoDB存储引擎,直接替代有Bug的旧引擎,不用等待MySQL的新版本,只要相应引擎的提供商发布新版本即可。
在MySQL 5.1.38前的版本中,安装InnoDB Plugin时需要下载Plugin的文件,解压后还要进行一系列安装,但MySQL 5.1.38版本中,MySQL包含了两个不同版本的InnoDB引擎,一个是旧版本引擎(称之为build-in innodb),另一个是1.0.4版本的InnoDB引擎,此版本中如果想使用新的InnoDB Plugin引擎,只需在配置文件中作如下配置:

MySQL 5.5.5开始InnoDB成为MySQL默认存储引擎。
这篇关于MySQL技术内幕InnoDB存储引擎 学习笔记 第二章 InnoDB存储引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





