本文主要是介绍MySQL技术内幕InnoDB存储引擎 学习笔记 第一章 MySQL体系结构和存储引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL几乎能在所有操作系统上运行,尽管各种系统在底层(如线程)实现方面各有不同,但MySQL几乎能保证在各平台上体系结构的一致性。
术语:
1.数据库:操作系统文件或其他形式文件类型的集合。MySQL数据库文件可以是以frm、myd、myi、ibd结尾的文件。使用NDB时,数据库的文件可能不是操作系统上的文件,而是存放于内存中的文件。
2.数据库实例:由数据库后台进程/线程以及共享内存区组成,共享内存区可被运行的后台进程/线程共享。数据库实例是真正用来操作数据库文件的。
MySQL中实例和数据库通常是一一对应,但集群情况下一个数据库可被多个实例使用。
MySQL是单进程多线程架构的数据库,与SQLserver类似,与oracle多进程的架构不同(但oracle的Windows版本也是单进程多线程架构)。
查看MySQL进程是否启动:
ps -ef | grep mysqld
启动实例时,MySQL会读取配置文件,根据参数启动数据库实例,这与oracle的参数文件(spfile)类似,但oracle没有参数文件时,会提示找不到该参数文件而启动失败,在MySQL中可以没有配置文件,此时会按编译时的默认参数设置启动实例。
查看MySQL在何处读取配置文件,:
mysql --help | grep my.cnf
运行它:

MySQL以以上配置文件列出顺序读取配置文件,从头读到尾,如果多个配置文件中有相同参数,以该参数最后一次出现为准。
Linux下配置文件一般放在/etc/my.cnf;Windows下,配置文件的后缀名可以是.cnf,也可以是.ini,Windows下运行mysql -help也可以找到配置文件读取位置。
配置文件中有一个datadir参数,指定了数据库所在路径,Linux下此参数默认为/usr/local/mysql/data,查看当前datadir路径:
SHOW VARIABLES LIKE 'datadir'\G
运行它:

\G作用为垂直显示每行结果。
必须保证datadir目录的属主(所有者为mysql)和权限,只有mysql用户和组可以访问。
对于MySQL,数据库是依照某种数据模型组织起来并存放于二级存储器(如硬盘、光盘)中的数据集合;数据库实例是应用程序,用户对于数据库数据的任何操作都是通过数据库实例完成的。
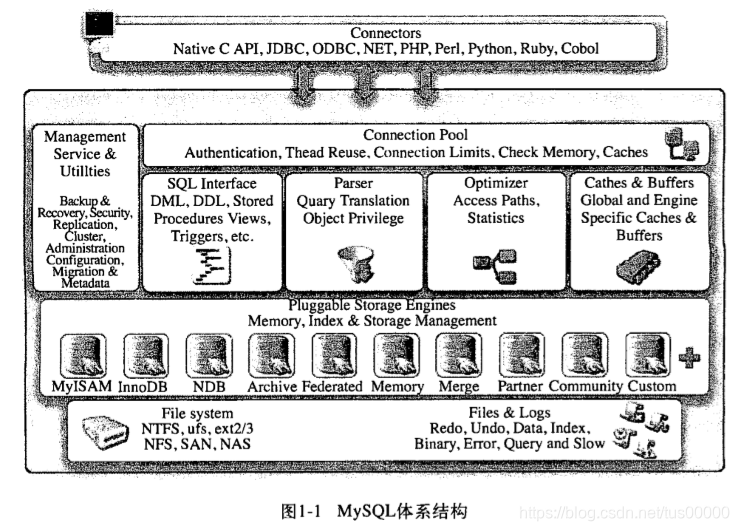
由上图,MySQL由以下部分组成:
1.连接池组件。
2.管理服务和工具组件。
3.SQL接口组件。
4.查询分析器组件。
5.优化器组件。
6.缓冲(Cache)组件。
7.插件式存储引擎。
8.物理文件。
存储引擎基于表而非数据库。
每个存储引擎都有其特点,应根据具体的应用建立不同的存储引擎表。对开发人员,存储引擎是透明的,但了解不同存储引擎的区别对开发人员也是有好处的。
MySQL是开源的,可根据MySQL预定义的存储引擎接口编写自己的存储引擎或对某种不满意的存储引擎修改源码。
存储引擎分官方存储引擎和第三方存储引擎,InnoDB开始时是第三方存储引擎,现已被Oracle收购,现在是OLTP(在线事务处理)应用中使用最广泛的存储引擎。
InnoDB支持事务,主要面向OLTP方面的应用,特点是行锁设计,支持外键,支持类似于Oracle的非锁定读。
InnoDB将数据放在一个逻辑的表空间中,由InnoDB进行管理,从MySQL 4.1开始它可以将每个InnoDB存储引擎的表单独放到一个独立的ibd文件中。与Oracle类似,InnoDB可以使用裸设备建立其表空间。
InnoDB使用多版本并发控制(MVCC)获得高并发性,实现了SQL标准的四种隔离级别,默认为可重复读(REPEATABLE READ),与标准SQL不同的是,InnoDB在REPEATABLE READ事务隔离级别下,使用Next-Key Lock锁算法,一定程度上避免了幻读的产生。InnoDB还提供了插入缓冲、二次写、自适应哈希索引、预读等高性能功能。
InnoDB表中的数据存储使用了聚集方式,类似于Oracle的索引聚集表(index organized table,IOT),每张表的存储都按主键的顺序存放,如果没有显式地在表定义时指定主键,InnoDB会为每行生成一个六字节的ROWID,以此作为主键。
MyISAM是MySQL官方提供的存储引擎,不支持事务,支持表锁和全文索引,对OLAP(Online Analytical Processing,在线分析处理)操作速度快。
MyISAM表由MYD和MYI组成,MYD存放数据文件,MYI存放索引,可通过myisampack工具进一步压缩数据文件,此工具使用赫夫曼编码压缩数据,因此压缩后的表是只读的,也可使用此工具解压数据文件。
MySQL 5.0之前,MyISAM默认最大支持4G大小的表,需要支持大于4G的MyISAM表时,需指定MAX_ROWS和AVG_ROW_LENGTH属性。从MySQL 5.0开始,MyISAM默认支持最大256T的单表数据。
对于MyISAM表,MySQL只缓存其索引文件,数据文件缓存交给操作系统本身完成,这与使用LRU(Least Recently Used,最近最少使用)算法缓存数据的大部分数据库不同。MySQL 5.1.23之前,无论在32位还是64位系统上,缓存索引的缓冲区最大只能设为4G,此后版本中,64位系统可以支持大于4G的索引缓冲区。
MySQL AB公司从Sony Ericsson公司收购了NDB集群引擎,即上图中的Cluster引擎,它类似于Oracle的RAC集群,但与Oracle RAC share everything不同,其结构是share nothing的集群架构,能提供更高级别的高可用性。NDB特点是数据全部放在内存(MySQL 5.1开始可以将非索引数据放在磁盘上),主键查找速度极快,通过添加NDB数据存储节点,可以线性地提高数据库性能。
NDB的JOIN操作是在MySQL数据库层完成的,而非在存储引擎层完成的,意味着复杂的连接操作需要巨大网络开销,查询速度很慢。
Memory存储引擎(之前称为HEAP存储引擎)将数据放在内存,如果数据库重启或崩溃,表中数据会消失,适合存储临时数据的临时表和数据仓库中的维度表(比如电影表中填写演员表中的演员id而非演员的所有信息,演员表就是维度表)。它默认使用哈希索引而非B+树索引。
Memory引擎速度非常快,但只支持表锁,并发性能差,且不支持TEXT和BLOB列类型,并且存储变长字段(varchar)时是按定长字段(char)的方式进行的,会浪费内存(但现在已有解决方案)。
MySQL使用Memory存储引擎作为临时表存放查询的中间结果集,如果中间结果集大于Memory表的容量设置或中间结果含TEXT或BLOB列类型字段,MySQL会将其转换成MyISAM表存放到磁盘。MyISAM表不缓存数据文件,因此作为临时表性能会低。
Archive存储引擎只支持INSERT和SELECT操作,从MySQL 5.1开始支持索引,它使用zlib算法将数据行压缩后存储,压缩比一般可达1:10,适合数据归档。Archive引擎使用行锁实现高并发的插入操作,但本身不是事务安全的存储引擎,其设计目标是提供高速插入和压缩功能。
Federated存储引擎不存放数据,而是指向一台远程MySQL数据库服务器上的表。类似SqlServer的链接服务器和Oracle的透明网关,但Federated引擎只支持MySQL数据库表,暂不支持异构数据库表。
Maria存储引擎是新开发出来设计目标主要是用来取代MyISAM存储引擎成为MySQL默认存储引擎。开发者是MySQL创始人之一,可看作是MyISAM的后续版本。特点是缓存数据和索引文件、行锁设计、提供MVCC功能、支持事务和非事务安全选项支持、更好的BLOB字符类型处理性能。
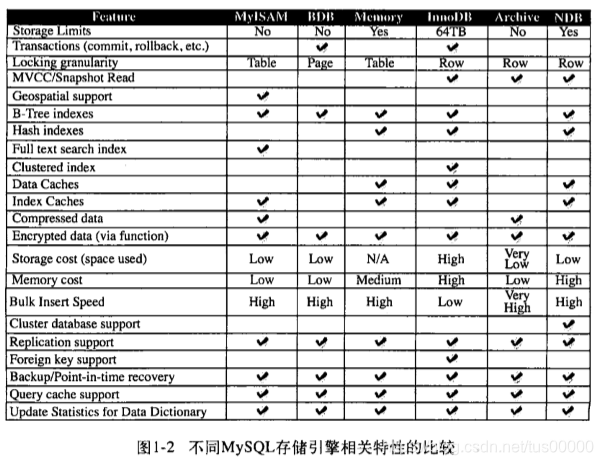
很多存储引擎不支持事务,数据库原理书中都会提到数据库与传统文件系统的最大区别是数据库支持事务,而MySQL却认为不是所有应用都需要事务,所以存在不支持事务的引擎。
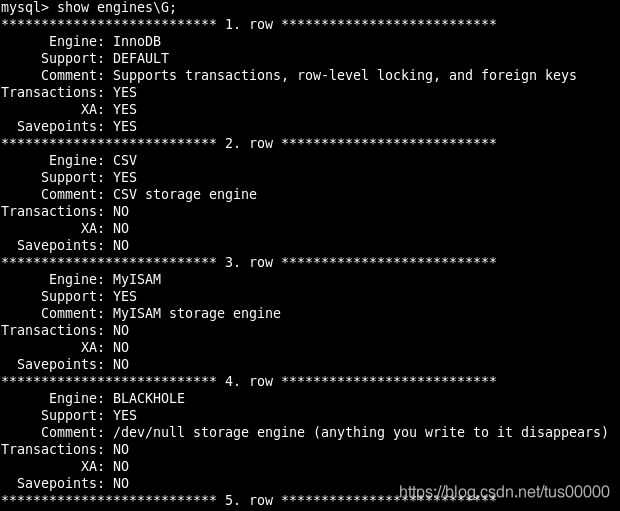
查看MySQL支持的存储引擎:
SHOW ENGINES;
运行它:
也可通过查找information_schema架构下的ENGINES表查看:
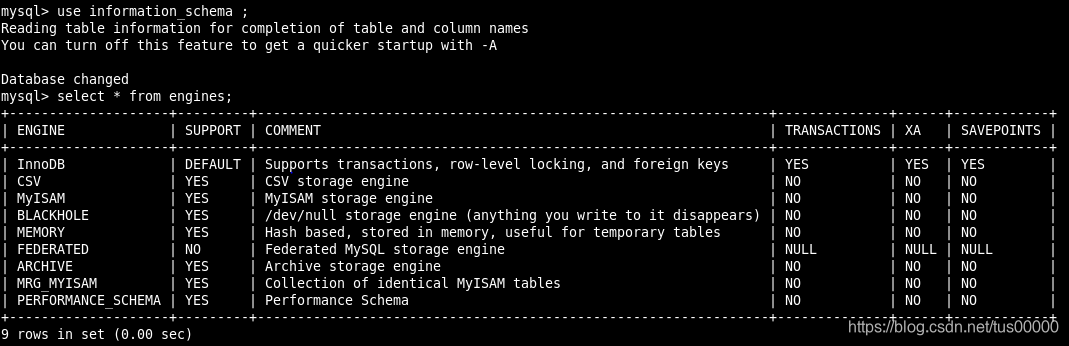
同样的数据量,表的大小:InnoDB > MyISAM > Archive。
MySQL连接是连接进程和数据库实例进行通信。
通过TCP/IP连接MySQL时,一般客户端和MySQL实例在不同服务器上:
mysql -h192.168.0.101 -u david -p
上例表示向Host IP为192.168.0.101的MySQL实例发起TCP/IP连接请求。
通过TCP/IP连接MySQL实例时,MySQL会先检查一张权限视图,判断发起请求的客户端IP是否允许连接到MySQL实例,该视图在mysql库下,表名为user:
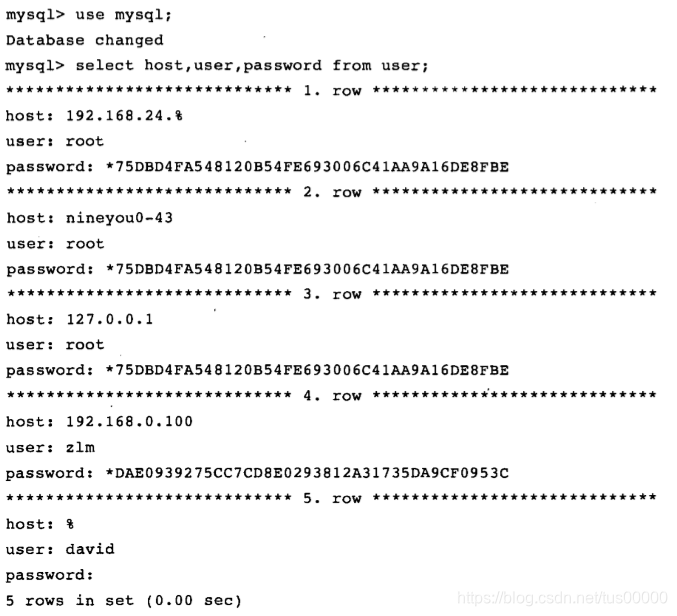
从上表可见,允许登录名david在任何IP段下连接该实例,且不需要密码,上表还给出了root用户在各个网段下的访问控制权限。
Windows上两个需要通信的进程如果在同一服务器上,可以使用命名管道。SQL server默认安装后的本地连接也使用命名管道。MySQL如使用命名管道需在配置文件中启用–enable-named-pipe选项。MySQL 4.1后,MySQL提供了共享内存的连接方式,需在配置文件中添加–shared-memory,在客户端连接时,还需使用-protocol=memory选项。
Linux和Unix下,可使用Unix域套接字进行客户端和服务器的通信,它不是一个网络协议,只能在MySQL客户端和数据库实例在同一台服务器上时使用,可在配置文件中指定套接字文件的路径,如-socket=/tmp/mysql.sock,启动数据库实例后,查看Unix域套接字文件位置:
SHOW VARIABLES LIKE 'socket';
运行它:
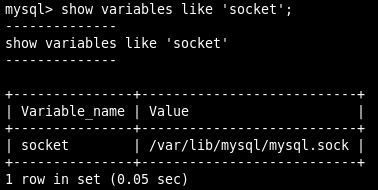
知道了域套接字文件的路径后,就能使用此方式连接了:
mysql -udavid -S .sock文件路径
这篇关于MySQL技术内幕InnoDB存储引擎 学习笔记 第一章 MySQL体系结构和存储引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




