本文主要是介绍对多目标粒子群算法MOPSO的理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多目标粒子群(MOPSO)算法是由CarlosA. Coello Coello等在2004年提出来的,详细参考1。目的是将原来只能用在单目标上的粒子群算法(PSO)应用于多目标上。我们知道原来的单目标PSO流程很简单:
-->初始化粒子位置(一般都是随机生成均匀分布)
-->计算适应度值(一般是目标函数值-优化的对象)
-->初始化历史最优pbest为其本身和找出全局最优gbest
-->根据位置和速度公式进行位置和速度的更新
-->重新计算适应度
-->根据适应度更新历史最优pbest和全局最优gbest
-->收敛或者达到最大迭代次数则退出算法
速度的更新公式如下:
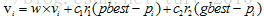
等式右边有三部分组成。第一部分是惯性量,是延续粒子上一次运动的矢量;第二部分是个体认知量,是向个体历史最优位置运动的量;第三部分是社会认知量,是粒子向全局最优位置运动的量。
有了速度,则位置更新自然出来了:
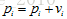
以上是对于多目标PSO算法的介绍。运用到多目标上去的话,出现的问题有以下几点:
- 如何选择pbest。我们知道对于单目标优化来说选择pbest,只需要对比一下就可以选择出哪个较优。但是对于多目标来说两个粒子的对比,并不能对比出哪个好一些。如果粒子的每个目标都要好的话,则该粒子更优。若有些更好,有些更差的话,就无法严格的说哪个好些,哪个差一些。
- 如何选择gbest。我们知道对于单目标在种群中只有一个最优的个体。而对于多目标来说,最优的个体有很多个。而对PSO来说,每个粒子只能选择一个作为最优的个体(领带者)。该如何选择呢?
MOPSO对于第一个问题的做法是在不能严格对比出哪个好一些时随机选择一个其中一个作为历史最优。对于第二个问题,MOPSO则在最优集里面(存档中)根据拥挤程度选择一个领导者。尽量选择不那么密集位置的粒子(在这里用到了网格法)。
MOPSO在选择领导者和对存档(也可以说是pareto临时最优断面)进行更新的时候应用了自适应网格法,详细参考2。如何选择领带者呢?
MOPSO在存档中选择一个粒子跟随。如何选择呢?根据网格划分,假设每个网格中粒子数个,i代表第几个网格。该网格中的粒子被选择的概率为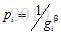 ,即粒子越拥挤,则选择的概率越低。这是为了保证能够对未知的区域进行探索。
,即粒子越拥挤,则选择的概率越低。这是为了保证能够对未知的区域进行探索。
如何进行存档呢?
在种群更新完成之后,是如何进行存档的呢?MOPSO进行了三轮筛选。
首先,根据支配关系进行第一轮筛选,将劣解去除,剩下的加入到存档中。
其次,在存档中根据支配关系进行第二轮筛选,将劣解去除,并计算存档粒子在网格中的位置。
最后,若存档数量超过了存档阀值,则根据自适应网格进行筛选,直到阀值限额为止。重新进行网格划分。refer:
- Handling multiple objectives with particle swarm optimization
- Approximating the non dominated front using the Pareto archivedevolution strategy
这篇关于对多目标粒子群算法MOPSO的理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









