本文主要是介绍ABAP json解析使用引用代替预定义数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景:在解析JSON数据时,通常会事先为定义相应的ABAP数据结构。但是,当遇到一些结构纵深较为复杂的情况时,会比较麻烦。
处理:使用引用类型来定义结构中的纵深部分来达到“省事”的目的,缺点在于访问时需要使用指针动态访问。也可以参考json转换为abap数据对象并输出数据声明_json 在线转abap-CSDN博客根据已处理好的json(不压缩且包含所有数据)来生成定义部分的代码。
DATA json TYPE string.
DATA pretty_name TYPE /ui2/cl_json=>pretty_name_mode.
DATA name_mappings TYPE /ui2/cl_json=>name_mappings.DATA: BEGIN OF data,tab1 TYPE REF TO data,tab2 TYPE REF TO data,END OF data.json = `{`
&& ` "TAB1": [{ `
&& ` "A": "A", `
&& ` "B": "B", `
&& ` "C": "C", `
&& ` "d": "d" `
&& ` }, { `
&& ` "D": "D", `
&& ` "E": "E", `
&& ` "F": "F" `
&& ` } `
&& ` ], `
&& ` "TAB2": [{ `
&& ` "KEY": "01", `
&& ` "VALUE": "第一行" `
&& ` }`
&& ` ] `
&& `} `
./ui2/cl_json=>deserialize(EXPORTINGjson = jsonpretty_name = /ui2/cl_json=>pretty_mode-noneassoc_arrays = ''assoc_arrays_opt = ''name_mappings = name_mappingsCHANGINGdata = data).
解析后的数据结构:
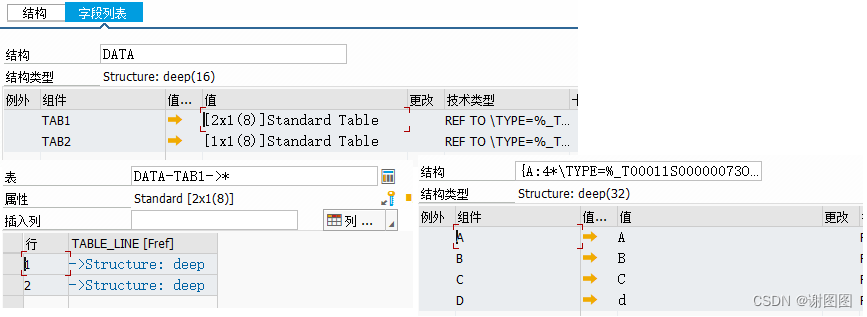
这篇关于ABAP json解析使用引用代替预定义数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






