本文主要是介绍TensorFlow进阶二(张量的填充与复制、张量的数据限幅、张量的高阶操作),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计5077字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
TensorFlow进阶二(张量的填充与复制、张量的数据限幅、张量的高阶操作)
- TensorFlow进阶二(张量的填充与复制、张量的数据限幅、张量的高阶操作)
- 一、任务需求
- 二、任务目标
- 1、掌握张量的填充与复制
- 2、掌握张量的数据限幅
- 3、掌握张量的高阶操作
- 三、任务环境
- 1、jupyter开发环境
- 2、python3.6
- 3、tensorflow2.4
- 四、任务实施过程
- (一)、数据填充
- (二)、数据复制
- (三)、数据限幅
- (四)、高阶操作
TensorFlow进阶二(张量的填充与复制、张量的数据限幅、张量的高阶操作)
一、任务需求
对于图片数据的高和宽、序列信号的长度,维度长度可能各不相同。为了方便网络的并行计算,需要将不同长度的数据扩张为相同长度,之前我们介绍了通过复制的方式可以增加数据的长度,但是重复复制数据会破坏原有的数据结构,并不适合于此处。通常的做法是,在需要补充长度的数据开始或结束处填充足够数量的特定数值,这些特定数值一般代表了无效意义,例如 0,使得填充后的长度满足系统要求。那么这种操作就叫作填充(Padding)。本节将要完成张量的填充与复制,数据限幅以及tf.gather、tf.gather_nd、tf.boolean_mark、tf.where、scatter_nd、meshgrid等函数的操作。
二、任务目标
1、掌握张量的填充与复制
2、掌握张量的数据限幅
3、掌握张量的高阶操作
三、任务环境
1、jupyter开发环境
2、python3.6
3、tensorflow2.4
四、任务实施过程
(一)、数据填充
1、考虑 2 个句子张量,每个单词使用数字编码方式表示,如 1 代表 I,2 代表 like 等。第
一个句子为:“I like the weather today.”我们假设句子数字编码为:[1,2,3,4,5,6],第二个句子为:“So do I.”它的编码为:[7,8,1,6]。为了能够保存在同一个张量中,我们需要将这两个句子的长度保持一致,也就是说,需要将第二个句子的长度扩充为 6。常见的填充方案是在句子末尾填充若干数量的 0,变成:[7,8,1,6,0,0]
import tensorflow as tf
a = tf.constant([1,2,3,4,5,6]) # 第一个句子
b = tf.constant([7,8,1,6]) # 第二个句子
b = tf.pad(b, [[0,2]]) # 句子末尾填充 2 个 0
b # 填充后的结果
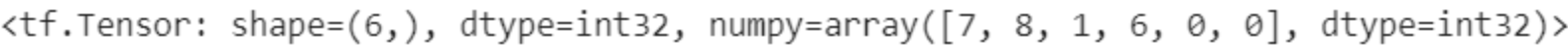
2、填充后句子张量形状一致,再将这 2 句子 Stack 在一起
tf.stack([a,b],axis=0) # 堆叠合并,创建句子数维度
<tf.Tensor: shape=(2, 6), dtype=int32, numpy=
array([[1, 2, 3, 4, 5, 6],[7, 8, 1, 6, 0, 0]], dtype=int32)>
3、我们来介绍同时在多个维度进行填充的例子。考虑对图片的高宽维度进行填充。以28 × 28大小的图片数据为例,如果网络层所接受的数据高宽为32 × 32,则必须将28 × 28
大小填充到32 × 32,可以选择在图片矩阵的上、下、左、右方向各填充 2 个单元
x = tf.random.normal([4,28,28,1])
# 图片上下、左右各填充 2 个单元
tf.pad(x,[[0,0],[2,2],[2,2],[0,0]])


通过填充操作后,图片的大小变为32 × 32,满足神经网络的输入要求
(二)、数据复制
4、通过 tf.tile 函数可以在任意维度将数据重复复制多份,如 shape 为[4,32,32,3]的数据,复制方案为 multiples=[2,3,3,1],即通道数据不复制,高和宽方向分别复制 2 份,图片数再复制 1 份
x = tf.random.normal([4,32,32,3])
tf.tile(x,[2,3,3,1]) # 数据复制


(三)、数据限幅
5、在 TensorFlow 中,可以通过 tf.maximum(x, a)实现数据的下限幅,即𝑥 ∈ [𝑎, +∞);可以通过 tf.minimum(x, a)实现数据的上限幅
x = tf.range(9)
tf.maximum(x,2) # 下限幅到 2

tf.minimum(x,7) # 上限幅到 7
<tf.Tensor: shape=(9,), dtype=int32, numpy=array([0, 1, 2, 3, 4, 5, 6, 7, 7], dtype=int32)>
6、通过组合 tf.maximum(x, a)和 tf.minimum(x, b)可以实现同时对数据的上下边界限幅
x = tf.range(9)
tf.minimum(tf.maximum(x,2),7) # 限幅为 2~7

7、我们可以使用 tf.clip_by_value 函数实现上下限幅
x = tf.range(9)
tf.clip_by_value(x,2,7) # 限幅为 2~7

(四)、高阶操作
8、tf.gather 可以实现根据索引号收集数据的目的。考虑班级成绩册的例子,假设共有 4个班级,每个班级 35 个学生,8 门科目,保存成绩册的张量 shape 为[4,35,8]。
x = tf.random.uniform([4,35,8],maxval=100,dtype=tf.int32) # 成绩册张量
9、现在需要收集第 1~2 个班级的成绩册,可以给定需要收集班级的索引号:[0,1],并指定班级的维度 axis=0,通过 tf.gather 函数收集数据
tf.gather(x,[0,1],axis=0) # 在班级维度收集第 1~2 号班级成绩册


10、收集第 1,4,9,12,13,27 号同学成绩
tf.gather(x,[0,3,8,11,12,26],axis=1)
<tf.Tensor: shape=(4, 6, 8), dtype=int32, numpy=
array([[[54, 9, 29, 15, 81, 69, 62, 19],[18, 88, 82, 99, 76, 88, 64, 51],[68, 17, 71, 86, 35, 47, 99, 60],[27, 24, 40, 94, 0, 96, 37, 44],[34, 8, 18, 53, 43, 73, 71, 31],[60, 66, 11, 58, 83, 58, 73, 47]],[[74, 6, 60, 63, 20, 13, 17, 66],[49, 47, 21, 56, 96, 34, 61, 6],[ 9, 90, 19, 31, 65, 76, 21, 24],[24, 89, 66, 85, 57, 50, 55, 47],[56, 1, 98, 78, 79, 36, 1, 27],[49, 5, 17, 43, 48, 71, 39, 22]],[[25, 48, 5, 17, 68, 18, 32, 3],[ 2, 13, 7, 73, 18, 28, 70, 90],[76, 1, 93, 98, 9, 84, 22, 23],[88, 36, 0, 42, 13, 34, 79, 80],[58, 44, 65, 42, 27, 39, 42, 4],[45, 49, 64, 29, 52, 94, 2, 63]],[[54, 27, 18, 63, 62, 84, 95, 4],[88, 89, 47, 68, 99, 99, 23, 76],[60, 40, 1, 30, 9, 99, 53, 46],[81, 48, 52, 4, 14, 37, 25, 80],[ 2, 33, 27, 96, 41, 72, 73, 9],[22, 44, 53, 17, 43, 73, 39, 96]]], dtype=int32)>
11、如果需要收集所有同学的第 3 和第 5 门科目的成绩,则可以指定科目维度 axis=2
tf.gather(x,[2,4],axis=2) # 第 3,5 科目的成绩
<tf.Tensor: shape=(4, 35, 2), dtype=int32, numpy=
array([[[29, 81],[65, 0],[39, 6],[82, 76],[38, 64],[45, 30],[43, 64],[34, 55],[71, 35],[51, 71],[85, 20],[40, 0],[18, 43],[37, 66],[46, 81],[34, 94],[56, 31],[44, 71],[75, 65],[32, 2],[51, 24],[ 2, 2],[96, 45],[36, 95],
...[92, 64],[76, 30],[91, 75],[23, 68],[49, 64]]], dtype=int32)>
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
12、tf.gather 非常适合索引号没有规则的场合,其中索引号可以乱序排列,此时收集的数据也是对应顺序
a=tf.range(8)
a=tf.reshape(a,[4,2]) # 生成张量 a
a

tf.gather(a,[3,1,0,2],axis=0) # 收集第 4,2,1,3 号元素
<tf.Tensor: shape=(4, 2), dtype=int32, numpy=
array([[6, 7],[2, 3],[0, 1],[4, 5]], dtype=int32)>
13、我们将问题变得稍微复杂一点。如果希望抽查第[2,3]班级的第[3,4,6,27]号同学的科目成绩,则可以通过组合多个 tf.gather 实现。首先抽出第[2,3]班级
students=tf.gather(x,[1,2],axis=0) # 收集第 2,3 号班级
students
<tf.Tensor: shape=(2, 35, 8), dtype=int32, numpy=
array([[[74, 6, 60, 63, 20, 13, 17, 66],[44, 83, 73, 38, 66, 9, 40, 61],[72, 71, 97, 92, 63, 0, 69, 52],[49, 47, 21, 56, 96, 34, 61, 6],[79, 88, 20, 79, 41, 95, 97, 7],[50, 15, 10, 24, 44, 73, 74, 39],[88, 31, 26, 77, 14, 16, 82, 65],[34, 68, 13, 13, 52, 73, 88, 89],[ 9, 90, 19, 31, 65, 76, 21, 24],[41, 22, 98, 64, 79, 7, 60, 46],[95, 55, 77, 82, 97, 19, 40, 62],[24, 89, 66, 85, 57, 50, 55, 47],[56, 1, 98, 78, 79, 36, 1, 27],[45, 64, 75, 61, 62, 90, 70, 45],[ 1, 61, 37, 91, 49, 81, 44, 88],[18, 13, 25, 29, 62, 73, 34, 37],[56, 18, 19, 3, 76, 23, 67, 47],[ 0, 97, 95, 95, 33, 90, 48, 4],[24, 75, 1, 87, 64, 62, 63, 16],[93, 81, 20, 0, 29, 86, 95, 50],[23, 21, 44, 49, 2, 75, 37, 23],[47, 33, 48, 16, 88, 50, 58, 26],[51, 81, 22, 81, 16, 7, 69, 26],[32, 44, 63, 43, 20, 86, 31, 74],
...[40, 7, 65, 55, 48, 22, 55, 30],[71, 39, 6, 5, 1, 66, 39, 8],[32, 87, 39, 81, 30, 73, 15, 86],[34, 32, 19, 10, 51, 84, 12, 37],[10, 71, 13, 61, 4, 15, 83, 2]]], dtype=int32)>
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
14、再从这 2 个班级的同学中提取对应学生成绩
# 基于 students 张量继续收集
tf.gather(students,[2,3,5,26],axis=1) # 收集第 3,4,6,27 号同学

此时得到这 2 个班级 4 个同学的成绩张量,shape为[2,4,8]
15、我们继续问题进一步复杂化。这次我们希望抽查第 2 个班级的第 2 个同学的所有科目,第 3 个班级的第 3 个同学的所有科目,第 4 个班级的第 4 个同学的所有科目。可以通过笨方式,一个一个的手动提取数据。首先提取第一个采样点的数据:𝑥[1,1],可得到 8 门科目的数据向量
x[1,1] # 收集第 2 个班级的第 2 个同学
<tf.Tensor: shape=(8,), dtype=int32, numpy=array([44, 83, 73, 38, 66, 9, 40, 61], dtype=int32)>
16、再串行提取第二个采样点的数据:𝑥[2,2],以及第三个采样点的数据𝑥[3,3],最后通过 stack方式合并采样结果
tf.stack([x[1,1],x[2,2],x[3,3]],axis=0)

这种方法也能正确地得到 shape 为[3,8]的结果,其中 3 表示采样点的个数,4 表示每个采样点的数据,看上去似乎也不错。但是它最大的问题在于手动串行方式地执行采样,计算效率极低
这篇关于TensorFlow进阶二(张量的填充与复制、张量的数据限幅、张量的高阶操作)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






