本文主要是介绍项目九:学会python爬虫数据保存(小白圆满级),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
前篇我们能够学会爬虫的请求和解析的简单应用,也能看懂爬虫的简单代码和运用,这一次我们学一下爬虫页面请求解析的数据通过什么样的方法来保存。
目录
前言
存储方法
1.文本文件
2.CSV文件
3.Excel文件
4.HTML文件
5.JSON文件
6.XML文件
7.数据库文件
实战案例
保存数据到TXT文件
保存数据到CSV文件
存储方法
1.文本文件
简单的数据可以直接存储在文本文件中,适用于小型项目或临时存储。
使用python内置的open函数将数据保存为文本文件。
代码案例
data = "这是一些文本数据"
with open('data.txt', 'w', encoding='utf-8') as file:file.write(data)输出结果

代码解释
1.字符串赋值:
data = "这是一些文本数据"这行代码创建了一个名为data的变量,并将其赋值为一个字符串,这个字符串包含了一些文本数据。
2.使用with语句打开文件:
with open('data.txt', 'w', encoding='utf-8') as file:这里使用了Python的with语句,它用于打开一个文件,并确保文件在操作完成后会被正确关闭,即使在写入过程中发生异常也是如此。
'open'函数用于打开文件。'data.txt'是要打开的文件的名称。'w'指定了文件打开的模式,这里是写入模式(write mode),如果文件存在,内容会被清空,然后写入新内容;如果文件不存在,将会创建一个新文件。encoding='utf-8'设置了文件的编码方式为UTF-8,这确保了文件可以正确地保存和读取包含非ASCII字符(如中文、表情等)的文本数据。
3.写入数据:
file.write(data)在with语句的代码块内部,使用write()方法将变量data中的字符串写入到文件中。write()方法不接受任何额外的参数,它将整个字符串写入文件。
整个代码块的作用是将字符串“这是一些文本数据”保存到当前目录下的data.txt文件中。如果data.txt文件已经存在,它的内容将被新的内容替换;如果文件不存在,将会创建一个新文件。
这种使用with语句和write()方法的写入方式是Python中处理文件的推荐做法,因为它简洁、安全,并且可以自动处理文件的打开和关闭。
2.CSV文件
逗号分隔值文件,适合表格数据的存储和使用Excel等工具打开。
使用csv模块将数据保存为CSV格式。
代码案例
import csv
data = [{"name": "John", "age": 30, "city": "New York"},{"name": "Anna", "age": 22, "city": "Los Angeles"}
]
with open('data.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.DictWriter(csvfile, fieldnames=['name', 'age', 'city'])writer.writeheader()for item in data:writer.writerow(item)输出结果

代码解释
1.导入csv模块:
import csv这行代码从Python标准库中导入了csv模块,该模块用于读写CSV文件。
2.准备数据:
data = [ {"name": "John", "age": 30, "city": "New York"}, {"name": "Anna", "age": 22, "city": "Los Angeles"}
]这里定义了一个名为data的列表,其中包含了两个字典。每个字典代表一个人的信息,包括姓名(name)、年龄(age)和城市(city)。
3.打开文件:
with open('data.csv', 'w', newline='', encoding='utf-8') as csvfile:使用with语句打开一个名为data.csv的文件,用于写入操作:
'data.csv'是文件的名称。'w'表示写入模式,如果文件已存在,它会被覆盖;如果不存在,将会创建一个新文件。newline=''参数用于防止在写入时产生额外的空行。encoding='utf-8'确保文件以UTF-8编码保存,这对于包含非ASCII字符的数据很重要。
4.创建DictWriter对象:
writer = csv.DictWriter(csvfile, fieldnames=['name', 'age', 'city'])csv.DictWriter是一个用于写入字典到CSV文件的类。它需要两个参数:文件对象和字段名称列表(即字典的键)。
5.写入表头:
writer.writeheader()writeheader()方法写入CSV文件的表头,即字段名称列表中的名称。
6.写入数据行:
for item in data: writer.writerow(item)这个循环遍历data列表中的每个字典,并使用writerow()方法将每个字典作为一行数据写入CSV文件。DictWriter会根据提供的字段名称列表自动将字典的相应值写入文件。
整个代码块的作用是将包含个人信息的列表转换为CSV格式,并保存到
data.csv文件中。CSV文件可以用Excel或其他电子表格软件打开,也可以被许多编程语言读取和处理。
3.Excel文件
使用xlwt或openpyxl库将数据保存为Excel格式,方便数据分析。
使用openpyxl库将数据保存为Excel格式。
代码案例
from openpyxl import Workbook
# 创建数据列表
data = [{'name': 'Alice', 'age': 25, 'city': 'New York'},{'name': 'Bob', 'age': 30, 'city': 'San Francisco'},# 其他数据行
]
#创建工作簿
wb = Workbook()
ws = wb.active
# 写入标题
ws['A1'] = 'Name'
ws['B1'] = 'Age'
ws['C1'] = 'City'
# 写入数据
for row_idx, row in enumerate(data, start=2):ws.cell(row=row_idx, column=1, value=row['name'])ws.cell(row=row_idx, column=2, value=row['age'])ws.cell(row=row_idx, column=3, value=row['city'])
# 保存文件
wb.save('data.xlsx')输出结果

已有代码注释
4.HTML文件
将数据保存为HTML格式,可以直接在浏览器中查看。
使用字符串拼接将数据保存为HTML格式。
代码案例
# 创建数据列表
data = [{'name': 'Alice', 'age': 25, 'city': 'New York'},{'name': 'Bob', 'age': 30, 'city': 'San Francisco'},# 其他数据行
]# 构建 HTML 内容
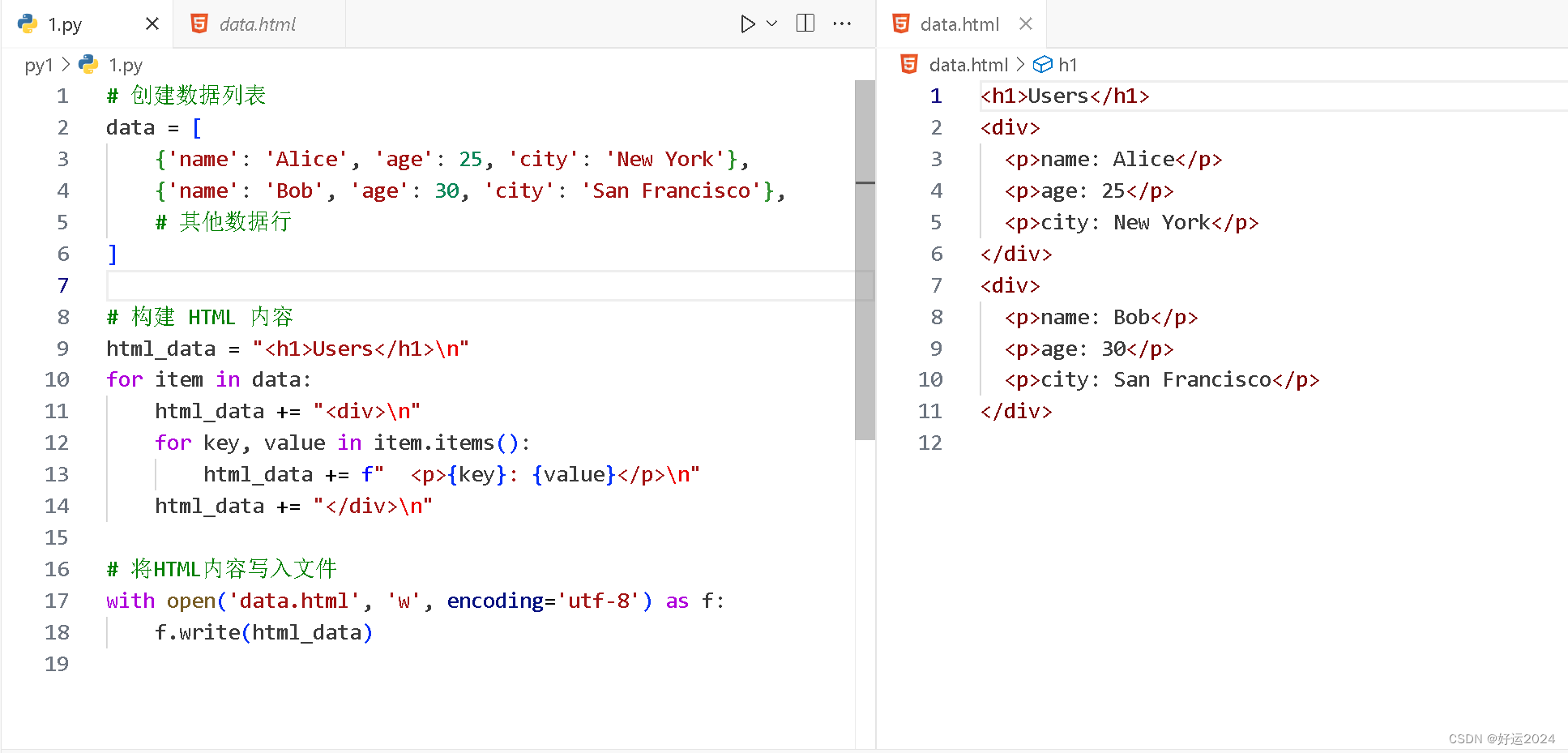
html_data = "<h1>Users</h1>\n"
for item in data:html_data += "<div>\n"for key, value in item.items():html_data += f" <p>{key}: {value}</p>\n"html_data += "</div>\n"# 将HTML内容写入文件
with open('data.html', 'w', encoding='utf-8') as f:f.write(html_data)
输出结果
代码解释(解释较难的代码)
构建内容
初始化一个名为 html_data 的字符串,它将用来存储最终的HTML内容。首先添加一个 <h1> 标签,表示一级标题,标题文本为 "Users"。
html_data = "<h1>Users</h1>\n"开始一个 for 循环,遍历 data 列表中的每个字典(即每个用户的信息)。
for item in data:对于每个用户,html_data 字符串会追加一个新的 <div> 标签,用来包裹该用户的详细信息。
html_data += "<div>\n"在这个 <div> 内部,开始另一个 for 循环,遍历当前用户字典 item 中的每个键值对。
for key, value in item.items():对于每个键值对,html_data 字符串会追加一个带有格式化文本的 <p> 标签。这里使用了格式化字符串字面量(f-string),将键(key)和值(value)插入到 <p> 标签的文本中,并以冒号分隔。
html_data += f" <p>{key}: {value}</p>\n"在添加完当前用户的所有信息后,html_data 字符串会追加一个 </div> 标签来关闭 <div>。
html_data += "</div>\n"后面不多写
5.JSON文件
以JSON格式保存数据,易于阅读和跨语言交换数据。
使用json模块将数据保存为JSON格式。
代码案例
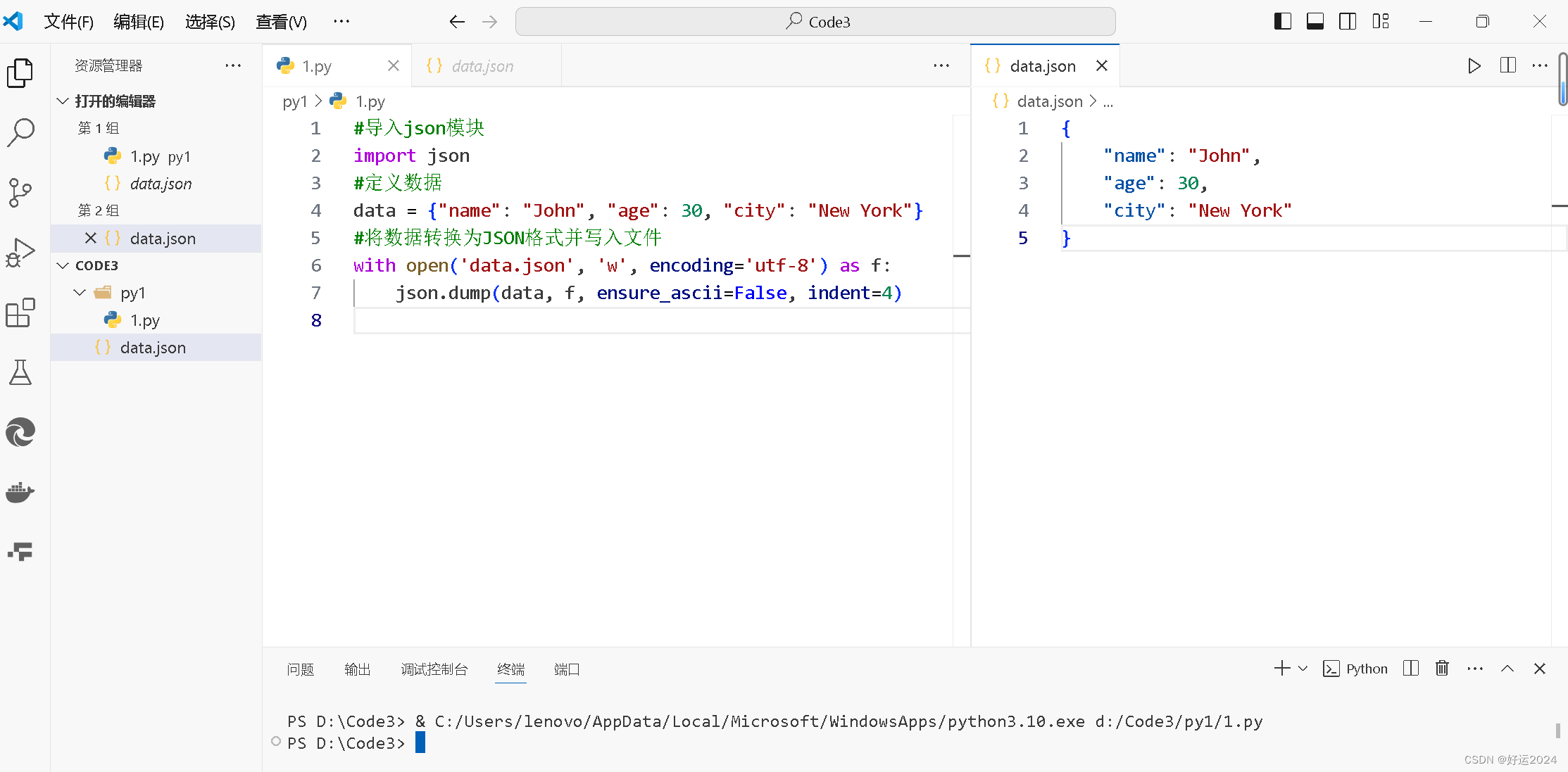
import json
data = {"name": "John", "age": 30, "city": "New York"}
with open('data.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)输出结果
代码解释
1.导入json模块:
import json这行代码从Python标准库中导入了json模块,该模块用于处理JSON数据。
2.创建字典数据:
data = {"name": "John", "age": 30, "city": "New York"}这里创建了一个名为data的字典,包含了键值对:"name"对应"John","age"对应30,"city"对应"New York"。
3.打开文件:
with open('data.json', 'w', encoding='utf-8') as f:使用with语句打开一个名为data.json的文件,用于写入操作:
'data.json'是文件的名称。'w'表示写入模式,如果文件已存在,它会被覆盖;如果不存在,将会创建一个新文件。encoding='utf-8'确保文件以UTF-8编码保存,这对于包含非ASCII字符的数据很重要。
4.使用json.dump()写入JSON数据:
json.dump(data, f, ensure_ascii=False, indent=4)json.dump()函数用于将Python对象转换为JSON格式的字符串,并写入到指定的文件中:
data是要转换为JSON格式的字典对象。f是文件对象,即上面打开的data.json文件。ensure_ascii=False指示json.dump()允许输出非ASCII字符,而不是将它们转义为\uXXXX形式。indent=4指定了输出的缩进级别,使得JSON文件具有可读性,每个层级缩进4个空格。
整个代码块的作用是创建一个包含个人信息的字典,并将其以格式化的JSON格式保存到文本文件中。这种格式的文件易于阅读和处理,常用于数据交换和配置文件。
6.XML文件
可扩展标记语言,适合存储结构化数据。
使用xml.etree.ElementTree模块将数据保存为XML格式。
代码案例
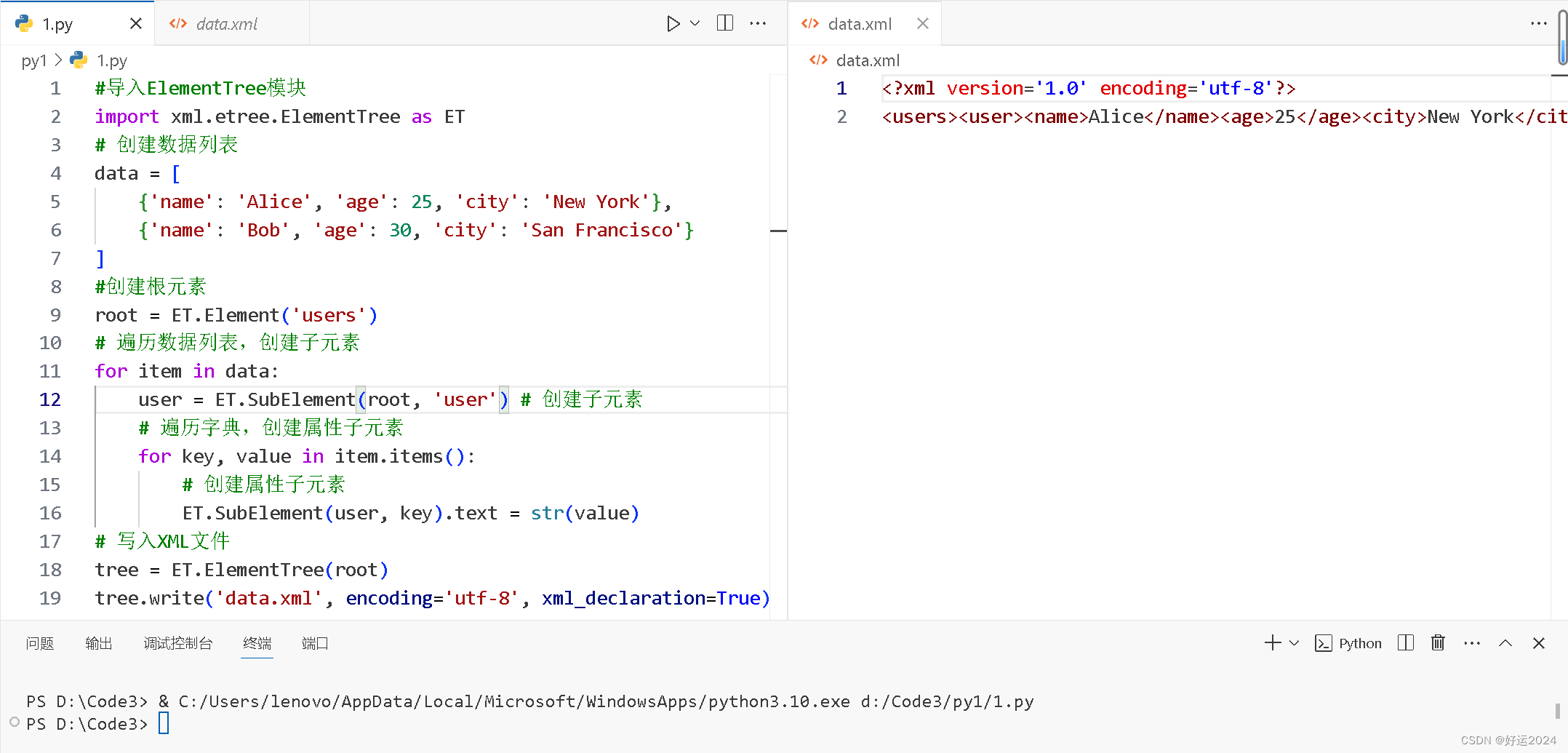
#导入ElementTree模块
import xml.etree.ElementTree as ET
# 创建数据列表
data = [{'name': 'Alice', 'age': 25, 'city': 'New York'},{'name': 'Bob', 'age': 30, 'city': 'San Francisco'}
]
#创建根元素
root = ET.Element('users')
# 遍历数据列表,创建子元素
for item in data:user = ET.SubElement(root, 'user') # 创建子元素# 遍历字典,创建属性子元素for key, value in item.items():# 创建属性子元素ET.SubElement(user, key).text = str(value)
# 写入XML文件
tree = ET.ElementTree(root)
tree.write('data.xml', encoding='utf-8', xml_declaration=True)
输出结果
已有代码注释
7.数据库文件
使用关系型数据库(如MySQL、PostgreSQL)或非关系型数据库(如MongoDB)存储结构化数据。
使用sqlite3模块将数据保存到SQLite数据库中。
代码案例
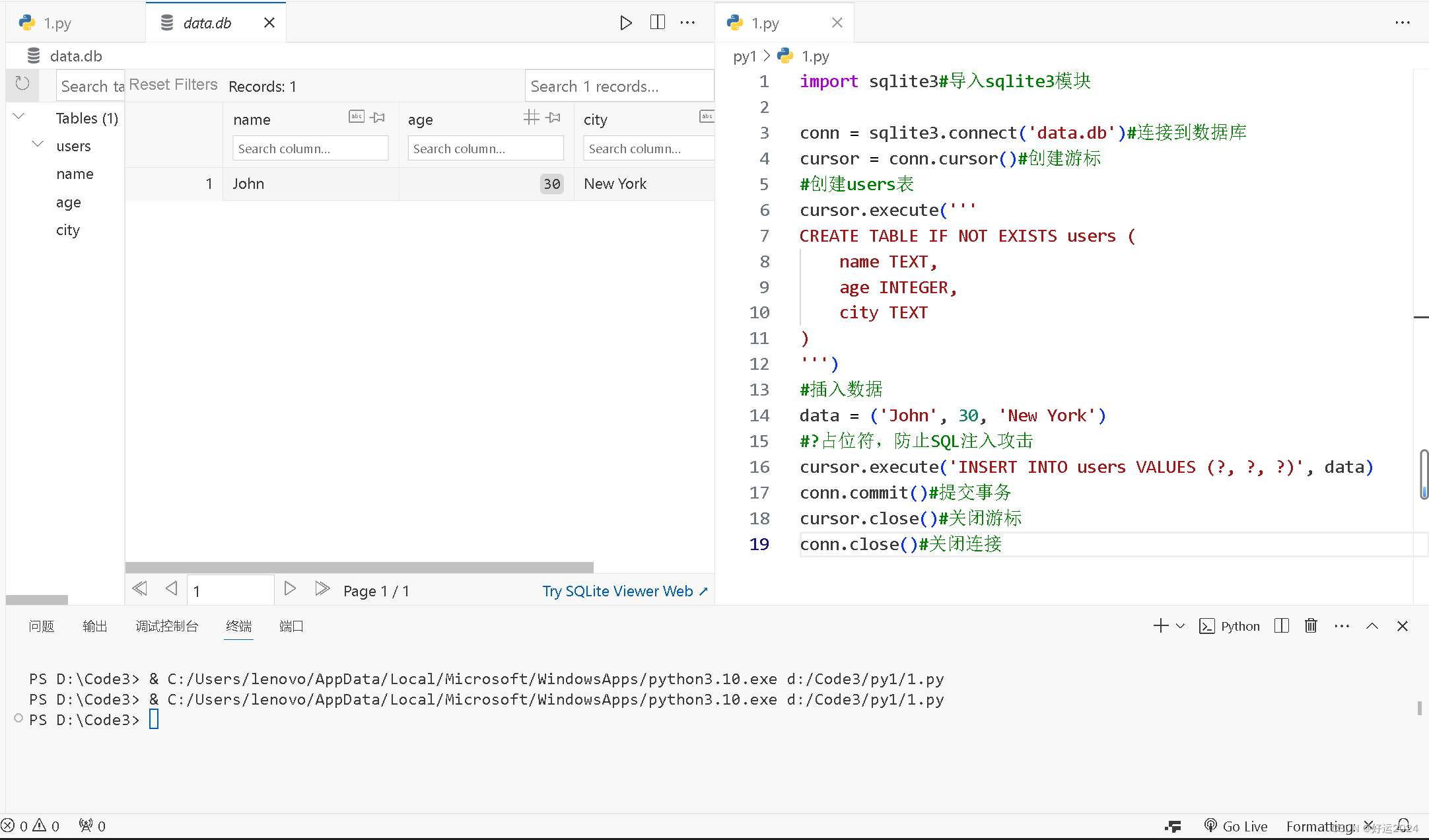
import sqlite3#导入sqlite3模块conn = sqlite3.connect('data.db')#连接到数据库
cursor = conn.cursor()#创建游标
#创建users表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (name TEXT,age INTEGER,city TEXT
)
''')
#插入数据
data = ('John', 30, 'New York')
#?占位符,防止SQL注入攻击
cursor.execute('INSERT INTO users VALUES (?, ?, ?)', data)
conn.commit()#提交事务
cursor.close()#关闭游标
conn.close()#关闭连接输出结果
已有代码注释
实战案例
知晓数据保存的方法后,就来两个小案例热身一下。
对于小说我们随意找个网站爬取目标数据,但是在爬取的过程中必须要遵守必要的规则,以免影响网站运行。当然如果熟悉《中国人民共和国网络安全法》也许最好不过。
保存数据到TXT文件
保存文本文件我们需要用到python内置函数open来进行文件操作
第一步:爬取目标小说列表。
打开开发者工具,选择网络(),刷新数据,找到本页面的网址链接,然后在标头的页面中观察一下相关数据,在请求标头中往下滑,找到user-agent这个数据,用来构建请求头。(一些数据不会展示,避免产生麻烦)如下

构建请求代码如下
url = '输入目标网址'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.4111 SLBChan/105'
}
第二步:定位小说列表元素
选择元素选项,看个人使用情况,定位相应的元素,然后复制xpath

第三步:发送响应,检查是否成功爬取信息列表

第四步:保存文本文件
构建文本文件代码如下
with open('comments.txt', 'w', encoding='utf-8') as f: #使用with open()新建对象f# 将列表中的数据循环写入到文本文件中for i in comments_list:f.write(i+"\n") #写入数据这个代码与前面介绍的过的代码异曲同工。但目的一样
完整代码如下
import requests
from lxml import etreeurl = 'https://www.biqusa.com/52_172463/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.4111 SLBChan/105'
}comments_list = [] # 初始化列表
response = requests.get(url, headers=headers) # 请求页面
html = etree.HTML(response.text)
# 以下是示例 XPath 表达式,根据网页结构获取相应元素的内容
comments = html.xpath('//*[@id="list"]/dl/dd[32]/a')
for comment in comments:comments_list.append(comment.text)
print(comments_list)with open('comments.txt', 'w', encoding='utf-8') as f: #使用with open()新建对象f# 将列表中的数据循环写入到文本文件中for i in comments_list:f.write(i+"\n") #写入数据输出结果

这个即可在vscode中查看或者其他方式查看你,全看个人使用情况
ok,通过这简单的数据保存案例,我们能够学会如何构建请求头和使用open方法的应用。
保存数据到CSV文件
保存数据文件需要使用python的内置模块csv。
不过在实战之前,还需要先练习csv是怎么使用了
第一、写入数据:创建writer对象,使用writerow()写入一行数据,使用writerows()方法写入多行数据。
import csvheaders = ['No','name','age']
values = [['01','Blue',18],['02','Lble',19],['03','Uble',20],
]
with open('test1.csv','w',newline='') as fp:# 获取对象writer = csv.writer(fp)# 写入数据writer.writerow(headers) #写入表头writer.writerows(values) # 写入数据输出结果

第二、读取数据:读取刚刚创立的csv文件,示例代码如下
import csvwith open('csv文件保存的路径', 'r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for row in reader:print(row)示例结果如下

就可以看到控制台输出列表信息了
知晓csv文件的使用,还是跟上次保存文本文件的操作方式一样,不过,代码不同
第一步:选中需要的目标元素,复制xpath,
代码如下
import requests
from lxml import etree
import csvurl = 'https://www.biqusa.com/52_172463/'
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}comments_list = [] #初始化用于保存列表response = requests.get(url=url,headers=headers) # 请求页面html = etree.HTML(response.text)lis = html.xpath('//*[@id="list"]/dl/dd/a') # 获取每一个列表for li in lis:result = li.xpath('./text()')comments_list.append(''.join(result)) # ''.join() 可以将列表转化为字符串new_list = [[x] for x in comments_list] # 列表生成器,将列表项转为子列表
with open("text2.csv", mode="w", newline="", encoding="utf-8") as f:csv_file = csv.writer(f) # 创建CSV文件写入对象for i in new_list:csv_file.writerow(i)
输出结果

就可以看到csv文件已生成在相应的文件目录下。
第二步(可有可无):在控制台输出csv列表。
需要添加代码如下
# 读取刚刚保存的csv文件
with open('/home/mw/project/comments.csv', 'r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for row in reader:print(row)输出结果

就可以读取csv文件
除了内置csv模块读取文件,还有 pandas 这个代码,可以利用 read_csv() 方法将数据从 CSV 中读取出来
pandas是由 Wes McKinney 开发的,它的名字来源于面板数据(panel data),这是一种多维数据集,常用于经济学研究。随着时间的发展,pandas已经成为 Python 数据分析领域不可或缺的工具之一。
示例代码如下:
import pandas as pddf = pd.read_csv('保存的文件路径')
print(df)#excle文件操作与这个csv文件类似示例输出结果

在这条蜿蜒的人生旅途中,我们每个人都是寻宝者,渴望着那一抹名为“好运”的宝藏。今天,我在这里留下了我的足迹,不仅是为了记录,更是为了分享。因为我相信,好运是一种传递,一种共鸣,一种我们共同追求的光。好了,我是好运,想要好运,今日记录到此一游,愿你我都能在这条旅途中,收获属于自己的那份幸运之光。

这篇关于项目九:学会python爬虫数据保存(小白圆满级)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




