本文主要是介绍3D Gaussian Splatting介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、概述
- 二、基础介绍
- 1. 多维高斯分布
- 2. 将3D 高斯投影到2D像素平面
- 3. 球谐函数
- 4. Splatting and α \alpha α blending
- 三、整体流程
- 四、 伪代码
- 五、评价指标
- 六、实验结果
- 七、reference
一、概述
3D Gaussian Splatting和NeRF一样,主要用于新视图合成。
特点:
- 使用光栅化渲染方式,而不是NeRF的基于射线的体渲染(volumetric rendering along a ray)
- 使用多个3D高斯球显示的表达场景
- 训练推理速度快的同时保证质量高
- 本质上是一个优化问题,没有使用神经网络
二、基础介绍
1. 多维高斯分布
Gaussians are defined by a full 3D covariance matrix Σ defined in world space centered at point (mean) μ \mu μ

进行了一定简化,我们回顾一下原始形式,若随机变量服从 X ∼ N ( μ , σ 2 ) X\sim N(\mu ,\sigma^2) X∼N(μ,σ2),则有如下的概率密度函数

对应到多元,就是下面的形式,

高斯分布的协方差Σ 是正定矩阵,一定可以进行对角化,因此可以分解成如下形式

R通过四元数表示,4个参数,S为对角矩阵,3个参数,所以协方差一共7个参数
2. 将3D 高斯投影到2D像素平面
y = p c = W w c p w + t w c y=p_c = W^c_w p_w+t^c_w y=pc=Wwcpw+twc
线性变换,依然符合高斯分布
Σ p c = W Σ p w W T \Sigma_{p_c} = W\Sigma_{p_w}W^T Σpc=WΣpwWT
从相机坐标系变换到像素坐标系:
z = [ z x z y 1 ] = ( 1 / p c z ) [ f x 0 c x 0 f y c y 0 0 1 ] [ p c x p c y p c z ] z = \begin{bmatrix} z_x\\ z_y\\ 1 \end{bmatrix}=(1/p_c^z)\begin{bmatrix} fx& 0& cx& \\ 0& fy& cy& \\ 0& 0& 1& \end{bmatrix} \begin{bmatrix} p_c^x\\ p_c^y\\ p_c^z \end{bmatrix} z= zxzy1 =(1/pcz) fx000fy0cxcy1 pcxpcypcz
这个变换是非线性的,需要进行一阶泰勒展开, z = F ( p c ) ≈ F ( μ y ) + J ( y − μ y ) z=F(p_c)\approx F(\mu _y)+ J(y-\mu_y) z=F(pc)≈F(μy)+J(y−μy),进而得到协方差变换为:
Σ z = J Σ p c J T = J W Σ p w W T J T \Sigma _z=J\Sigma _{p_c}J^T=JW\Sigma _{p_w}W^TJ^T Σz=JΣpcJT=JWΣpwWTJT
均值如下:
μ z = F ( μ y ) = F ( W μ p w c + t ) \mu_z = F(\mu^y)=F(W\mu_{p_w^c}+t) μz=F(μy)=F(Wμpwc+t)
3. 球谐函数
- 球谐函数用于表达空间中某点的光照模型(NeRF通过MLP来建模光照模型,输入(x,y,z,theta,phi)-> MLP->颜色C)
- 光照函数 C ( θ , ϕ ) C(\theta, \phi) C(θ,ϕ)可以表示为球谐函数的加权线性组合,如下,某一个位置高斯球的函数,输入为角度,输出为这个角度的颜色

其中:

- m由J决定,如J=3, m=-3,-2,-1,0,1,2,3, J =2 m = -2,-1,0,1,2 , 对应7+5+3+1=16个球谐函数,所以有16个系数c,RGB分别对应一个球谐函数线性组合,所以光照模型一共16*3=48个参数,这些参数就是需要优化的变量。
- 输入 ( θ , ϕ ) (\theta, \phi) (θ,ϕ),确定J,那么球谐函数就是固定的,如下,带入 ( θ , ϕ ) (\theta, \phi) (θ,ϕ),那么球谐函数就是一个个实数

带入J,化简之后:

其他如下图所示

实际使用时,不用 ( θ , ϕ ) (\theta, \phi) (θ,ϕ),而是使用方向向量d = (x,y,z)(模长为1),转换如下图所示,这样就可以把上面球谐函数表示为关于x,y,z的函数。

NeRF通过MLP确定光照模型,这里是通过球谐函数确定光照模型,每个高斯球48个参数,估计出来就能知道这个高斯球的光照模型。
注:也可以理解为一种朝向编码方法,NeRF中姿态会进行编码,这种编码方式可以替换为球谐函数,更有物理意义。
4. Splatting and α \alpha α blending
Splatting是一种光栅化(Rasterize)3D对象的方法,即将3D对象投影到2D图形。如将3D高斯球(也可以是其他图形)往像素平面扔雪球,在像素平面的能量从中心向外扩散并减弱。该过程可以方便的并行处理。一会可以看到,这对应后面的projection过程,即把3D高斯球投影到2D图像上的过程。
α \alpha α blending介绍
光栅化之后怎么混合这些像素平面的椭球呢?使用 α \alpha α blending,主要解决图层融合的问题。
以两幅图像为例,图像 I 1 I_1 I1透明度为KaTeX parse error: Undefined control sequence: \lapha at position 1: \̲l̲a̲p̲h̲a̲_1,图像 I b k I_{bk} Ibk为背景,融合公式如下:
I r e s u l t = I 1 ∗ α 1 + I B K ∗ ( 1 − α 1 ) I_{result} = I_1 * \alpha_1 + I_{BK}*(1-\alpha_1) Iresult=I1∗α1+IBK∗(1−α1)

扩展到多张图,按照深度由近到远排序四张图,融合公式如下: I B K I_{BK} IBK先和 I 3 I_3 I3融合,再和 I 2 I_2 I2, I 1 I_1 I1

I B K I_{BK} IBK为0,则可以写成

这就是 α \alpha α blending 公式了。
接下来说一下 α \alpha α blending和NeRF体渲染的区别:
体渲染公式如下:


公式相同,虽然公式相同,但实现上区别比较大,应用方式也不一样。
三、整体流程

场景表达通过很多个高斯球来实现,如下图所示,每个高斯球对应59个参数。

其中决定一个高斯球需要59个系数来表达,这些也是优化问题要求解的状态:
- 中心位置:3dof
- 协方差矩阵:7dof
- 透明度:1dof
- 球谐系数:48 dof(J = 3,16 * 3)
整体流程
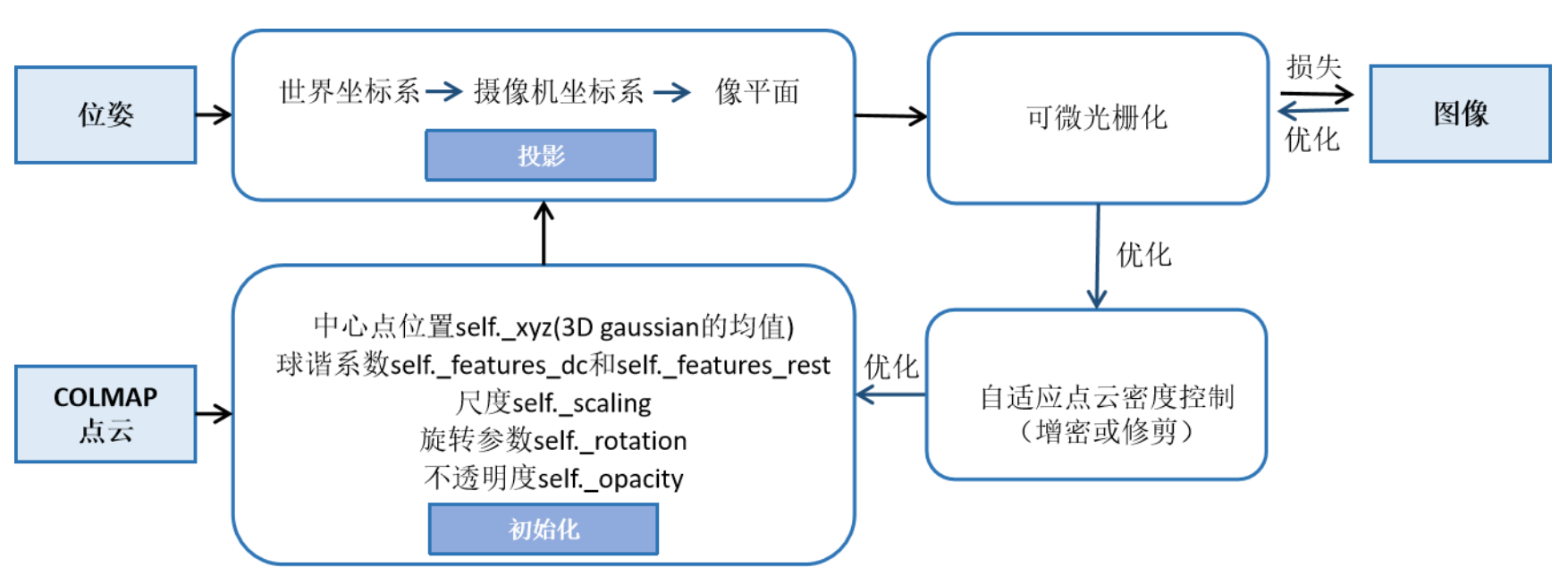
1)Initialization: 输入为3D点云,可以 通过colmap得到,(NeRF也会用到colmap,使用位姿), 基于这些点云初始化高斯球,每个点云位置放置一个高斯球,中心点位置设置为点云位置,其他随机初始化
2) Projection: 根据相机内外参数(图像位姿),把高斯球splatting到图像上–把能看到99%的所有高斯球投影到图像上(参考“将3D 高斯投影到2D像素平面”)使用下面3个公式

3)Differentiable Tile Rasterizer:在投影重叠区域进行光栅化渲染(Differentiable Tile Rasterizer),使用 α \alpha α blending,这是确定的函数,不需要学习。把这些高斯球进行混合,过程可微,公式就是:

4)与gt计算loss,更新每个高斯球的59维系数

损失函数为:

其中:
- L1 loss:基于逐像素比较差异,然后取绝对值

- SSIM loss(结构相似)损失函数:考虑了亮度 (luminance)、对比度 (contrast) 和结构 (structure)指标,这就考虑了人类视觉感知,一般而言,SSIM得到的结果会比L1,L2的结果更有细节,SSIM 的取值范围为 -1 到 1,1 表示两幅图像完全一样,-1 表示两幅图像差异最大。

def _ssim(img1, img2, window, window_size, channel, size_average=True):mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)mu1_sq = mu1.pow(2)mu2_sq = mu2.pow(2)mu1_mu2 = mu1 * mu2sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sqsigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sqsigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2C1 = 0.01 ** 2C2 = 0.03 ** 2ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))if size_average:return ssim_map.mean()else:return ssim_map.mean(1).mean(1).mean(1)
参考论文:Loss Functions for Image Restoration with Neural Networks(ref)
参考链接:wiki
5)梯度回传
- 更新每个高斯球的属性(59维系数)-这是个优化问题
- Adaptive Density Control:根据梯度实现3D高斯球的clone和split,具体而言
- 学习过程中,较大梯度(59维导数,模长大)的高斯球存在under-reconstruction和over-reconstruction问题
- under-reconstruction区域的高斯球方差小,进行clone
- over-reconstruction区域高斯球方差大,进行split

- 每经过固定次数的迭代进行一次剔除操作,剔除几乎透明(透明度接近0)的高斯球以及方差过大的高斯球
四、 伪代码

对应colmap输入点云,内部处理流程:
rasterization pipeline:

- cull some 3D gaussian, 99%必须投影到当前图像,才有效
2)都投影到图像
3)把图像分成很多tile,并行处理
4)建立索引和tile的对应关系,每个tile的深度值存在key里面
5)key排序
6)逐个tile渲染
注意:rasterzation时,每个高斯球投影到image时,透明度也需要从中心点开始递减,根据概率衰减
五、评价指标
PSNR (Peak Signal-to-Noise Ratio) 峰值信噪比是一种评估图像质量的常用指标,主要用于衡量原始图像和压缩或重构后的图像之间的质量差异。
- PSNR 是基于预测错误的均方值来定义的,公式为:

其中,MAX_I 是图像可能的最大像素值(对于8位图像来说,值为255),MSE 是均方误差,计算公式为:
- MSE = (1/mn) ΣΣ[(I(i,j)-K(i,j))^2] (i=1:m, j=1:n)
其中,I(i,j) 和 K(i,j) 分别是在位置 (i,j) 的原始图像和重构后的图像单元像素的亮度值,‘m’ 和 ‘n’ 分别是图像的行数和列数。
PSNR 的取值范围是 0到无穷大,单位是 dB(分贝)。PSNR 值越大,说明重构图像质量越高。但需要注意的是,PSNR 只是一个粗略的图像质量度量指标,有时候 PSNR 很高的两幅图像,人眼可能会觉得差异很大;反之,PSNR 很低的两幅图像,人眼可能觉得差异不大。
六、实验结果
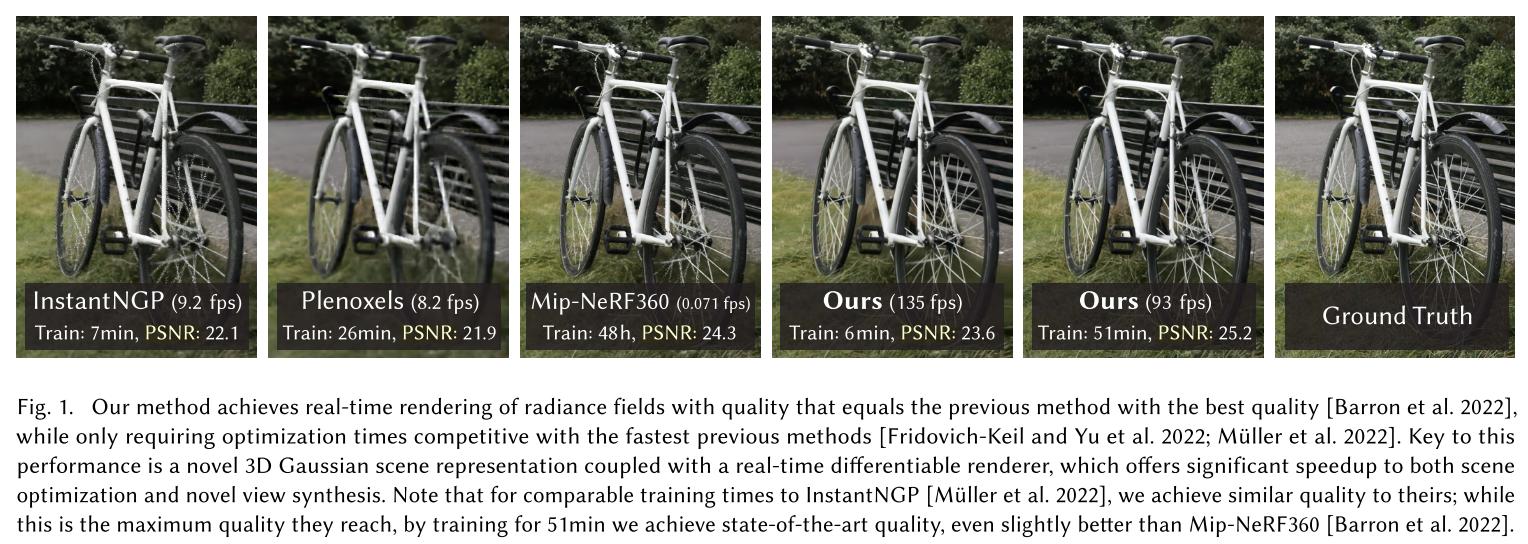
训练速度快,和instant NGP相当,效果更好。推理速度135fps,很快,训练时间增长51min,效果比Mip-NeRF360更好,因为有更多高斯球,所以推理速度慢一点,但也有93fps.
七、reference
多元高斯分布介绍
深蓝学院课程
这篇关于3D Gaussian Splatting介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






