本文主要是介绍【弱监督语义分割】DuPL:双学生鲁棒性弱监督语义分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DuPL: Dual Student with Trustworthy Progressive Learning for Robust Weakly Supervised Semantic Segmentation
CVPR 2024
摘要:
与繁琐的多阶段相比,带有图像级标签的单阶段弱监督语义分割(WSSS)因其简化性而受到越来越多的关注。受限于类激活图(CAM)固有的模糊性,我们发现单阶段方法经常会遇到由不正确的 CAM 伪标签引起的确认偏差,从而影响其最终的分割性能。虽然最近的研究抛弃了许多不可靠的伪标签,隐性地缓解了这一问题,但它们未能对其模型进行充分的监督。为此,我们提出了具有可信渐进学习(DuPL)的双学生框架。具体来说,我们提出了一个双学生网络,通过差异损失为每个子网络生成不同的 CAM。两个子网相互监督,减轻了因学习各自错误的伪标签而产生的确认偏差。在此过程中,我们通过动态阈值调整和自适应噪声过滤策略,逐步引入更可信的伪标签参与监督。此外,我们认为每个像素,即使因其不可靠而被从监督中剔除,对于 WSSS 都是重要的。因此,我们对这些被放弃的区域进行了一致性正则化处理,从而对每个像素都进行了监督。

介绍:
目前流行的工作通常遵循多阶段管道[18],即伪标签生成、细化和分割训练。通过分类从类激活图(CAM)中提取像素级伪标签[46]。由于类激活图倾向于识别具有区分性的语义区域,而无法区分共现对象,因此伪标签往往会受到类激活图模糊性的影响。因此,需要通过训练细化网络来细化伪标签[1, 2]。最后,细化后的伪标签将用于以完全监督的方式训练分割模型。最近,为了简化多阶段过程,许多研究提出了同时生成伪标签和学习分割头的单阶段解决方案 [3,39,40]。尽管这些方案提高了训练效率,但其性能仍然落后于多阶段方案。
其中一个被忽视的重要原因是 CAM 的确认偏差,这种偏差源于同时进行的 CAM 伪标签生成和细分监督过程。对于单阶段,分割训练强制主干特征与 CAM 伪标签保持一致。由于分割头和 CAM 生成共享骨干特征,这些不准确的 CAM 伪标签不仅阻碍了分割的学习过程,更关键的是,它们强化了 CAM 的错误判断。如图 2 所示,这一问题在整个训练阶段持续恶化,并最终降低了分割性能。最近的单阶段方法 [39, 40, 44] 通常会设置一个固定的高阈值来过滤不可靠的伪标签,从而优先考虑高质量的监督以隐性地缓解这一问题。然而,这种策略无法为其模型提供足够的监督。采用固定的高阈值不可避免地会丢弃许多实际上具有正确 CAM 伪标签的像素。此外,这些从监督中丢弃的不可靠区域往往存在于语义模糊的区域中。直接将其排除在监督范围之外会使模型很少学习这些区域的分割,从而导致训练不足。从这个角度来看,我们认为每个像素对于分割都很重要,都应该得到合理利用。

针对上述局限性,本研究提出了一种具有可信渐进学习功能的双学生框架,称为 DuPL。受共同训练范例[35]的启发,我们让两个学生子网络相互学习。他们从不同的视角推断不同的 CAM,并将从一个视角学到的知识转移到另一个视角。为避免学生同质化,我们对两个子网络施加了表征级差异约束?。这种架构能有效减轻学生因自身错误的伪标签而产生的确认偏差,从而生成高保真的 CAM。在双学生框架的基础上,我们提出了值得信赖的渐进式学习,以实现充分的分割监督。我们建立了动态阈值调整策略,让更多像素参与到分割监督中。为了克服 CAM 伪标签中的噪声,我们提出了基于高斯混合模型的自适应噪声过滤策略。最后,对于因伪标签不可靠而将其排除在监督之外的区域,我们对每个子网采用了额外的强扰动分支,并对这些区域进行了一致性正则化。
相关工作:
One-stage Weakly Supervised Semantic Segmentation.
Confirmation Bias:这种现象通常发生在半监督学习(SSL)的自我训练范式中[21],即模型过度贴合分配了错误伪标签的未标记图像。在上述过程中,这些不正确的信息不断被强化,导致训练过程不稳定[4]。Co-training可有效解决这一问题 [35]。它使用两个不同的子网来提供相互监督,以确保更多的稳定而准确的预测,同时减少确认偏差 [8, 33]。受此启发,我们提出了一种具有表征级差异损失的双学生架构,以生成多样化的 CAM。两个子网通过对方的伪标签相互学习,从而抵消了 CAM 的确认偏差,实现了更好的对象激活。据我们所知,DuPL 是第一项探索单级 WSSS 中 CAM 确认偏差的研究。
Noise Label Learning in WSSS:除了更好地生成 CAM 伪标签外,最近的几项研究还致力于利用现有的伪标签学习稳健的分割模型[10, 27, 31]。URN [27] 通过不同视图之间的像素方差引入了不确定性估计,以过滤噪声标签。基于早期学习和记忆现象[30],ADELE[31]在早期学习阶段根据先前的输出自适应地校准噪声标签。与其他方法依赖已有的 CAM 伪标签不同,单阶段方法中的伪标签在训练过程中会不断更新。为了减轻渐进学习中的噪声伪标签问题,我们设计了一种基于分割头损失反馈的在线自适应噪声过滤策略。
模型方法:
我们首先简要回顾一下如何生成 CAM [46] 及其伪标签。给定一幅图像,其特征图 F∈R~D×H×W 由骨干网络提取,其中 D 和 H × W 分别为通道维度和空间维度。然后,将 F 送入全局平均池和分类层,输出最终的分类得分。在上述过程中,我们可以获取每个类 W∈R~C×D 的分类权重,并利用它对特征图进行加权和求和,生成 CAM:
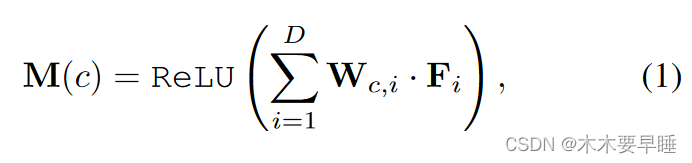
其中 c 是第 c 个类别,ReLU 用于消除负激活。最后,我们采用最大最小归一化法将 M∈R~C×H×W 重定标为 [0,1]。为了生成 CAM 伪标签,单级 WSSS 方法通常使用两个背景阈值 τl 和 τh 来分离背景(M ≤ τl)、不确定区域(τl < M < τh)和前景(M ≥ τh)[39,40]。不确定部分被视为具有噪声的不可靠区域,不会参与分割头的监督。
Dual Student Framework:
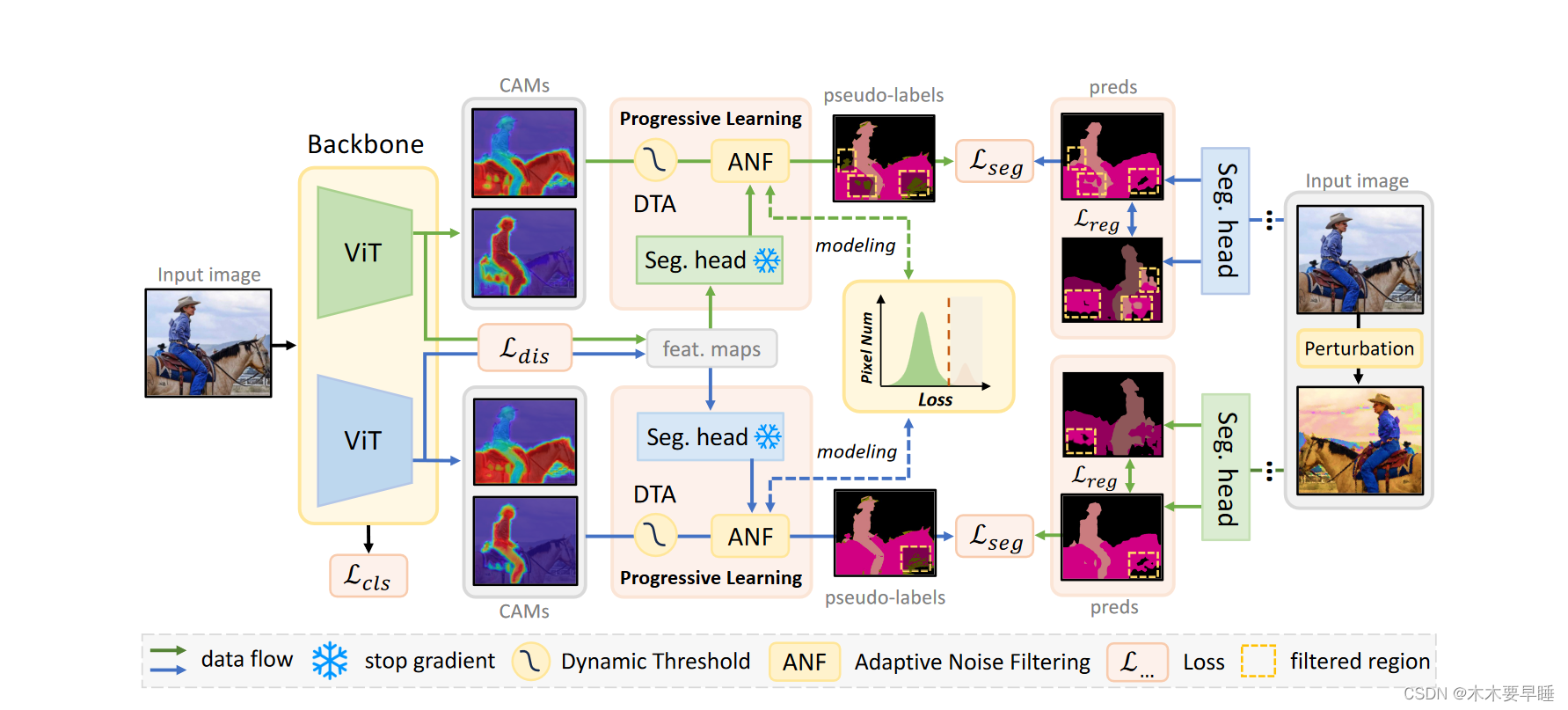 为了克服 CAM 的确认偏差,我们提出了一种基于共同训练的双学生网络,其中两个子网络(即ψ1 和ψ2)具有相同的网络结构,它们的参数独立更新且不共享。如图 3 所示,对于第 i 个子网络,它包括一个主干网络 ψf i、一个分类器 ψc i 和一个分段头 ψs i。为了确保两个子网在 CAM 中激活更多不同的区域,我们对它们从 ψf i 中提取的表示强制执行足够的多样性,防止两个子网同质化,从而使一个子网可以从另一个子网学习知识,以减轻 CAM 的确认偏差。因此,我们设置了一个差异约束,以最小化两个子网的特征图之间的余弦相似度。形式上,将输入图像表示为 X,来自子网的特征表示为 f 1 = ψf 1 (X) 和 f2 = ψf 2 (X),我们通过以下方式最小化它们的相似度:
为了克服 CAM 的确认偏差,我们提出了一种基于共同训练的双学生网络,其中两个子网络(即ψ1 和ψ2)具有相同的网络结构,它们的参数独立更新且不共享。如图 3 所示,对于第 i 个子网络,它包括一个主干网络 ψf i、一个分类器 ψc i 和一个分段头 ψs i。为了确保两个子网在 CAM 中激活更多不同的区域,我们对它们从 ψf i 中提取的表示强制执行足够的多样性,防止两个子网同质化,从而使一个子网可以从另一个子网学习知识,以减轻 CAM 的确认偏差。因此,我们设置了一个差异约束,以最小化两个子网的特征图之间的余弦相似度。形式上,将输入图像表示为 X,来自子网的特征表示为 f 1 = ψf 1 (X) 和 f2 = ψf 2 (X),我们通过以下方式最小化它们的相似度:
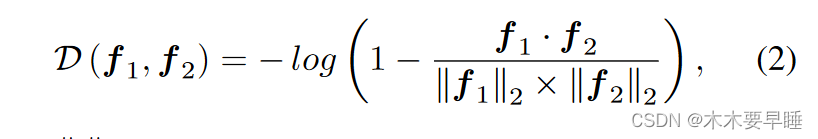
其中 ∥-∥2 为 l2 归一化。根据[7, 14],我们将对称差异损失定义为:

其中 ∆ 是停止梯度操作,以避免模型崩溃。这一损失是针对每幅图像计算的,总损失是所有图像的平均值。
双学生的分段监督是双向的。一个是从 M1 到 ψ2,另一个是从 M2 到 ψ1,其中 M1、M2 分别是来自子网 ψ1、ψ2 的 CAM。来自 M1 的 CAM 伪标签 Y1 用于监督来自另一个子网分割头 ψs 2 的预测图 P2,反之亦然。我们框架的分割损失计算公式为:
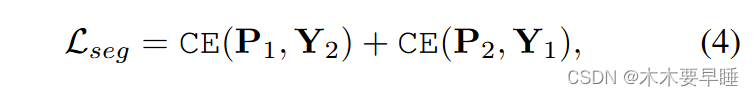
Trustworthy Progressive Learning
动态阈值调整:如第 3.1 节所述,单阶段方法 [39, 40, 44] 设置背景阈值 τl 和 τh 来生成伪标签,其中 τh 通常设置为非常高的值,以确保只有可靠的前景伪标签才能参与监督。相比之下,在双学生框架的训练过程中,CAM 会逐渐变得更加可靠。基于这一直觉,为了充分利用更多的前景伪标签进行充分的训练,我们在每次迭代中都采用余弦下降策略来调整背景阈值τh:
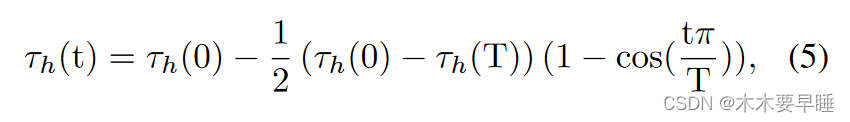
其中,t 是当前的迭代次数,T 是训练的总迭代次数。
自适应噪声滤波: 为了进一步减少生成的伪标签中影响分割的噪音,我们开发了一种自适应噪声过滤策略,以实现值得信赖的渐进式学习。以往的研究表明,深度网络倾向于更快地拟合干净的标签,而不是噪声标签[5, 15, 37]。这意味着,在模型过度拟合噪声标签之前,损失较小的样本更有可能被视为干净的样本。一个简单的方法是使用一个预定义的阈值,根据训练损失来划分干净和有噪声的伪标签。但是,这种方法没有考虑到模型的损失分布在不同样本中是不同的,即使是同一类别中的样本也是如此。
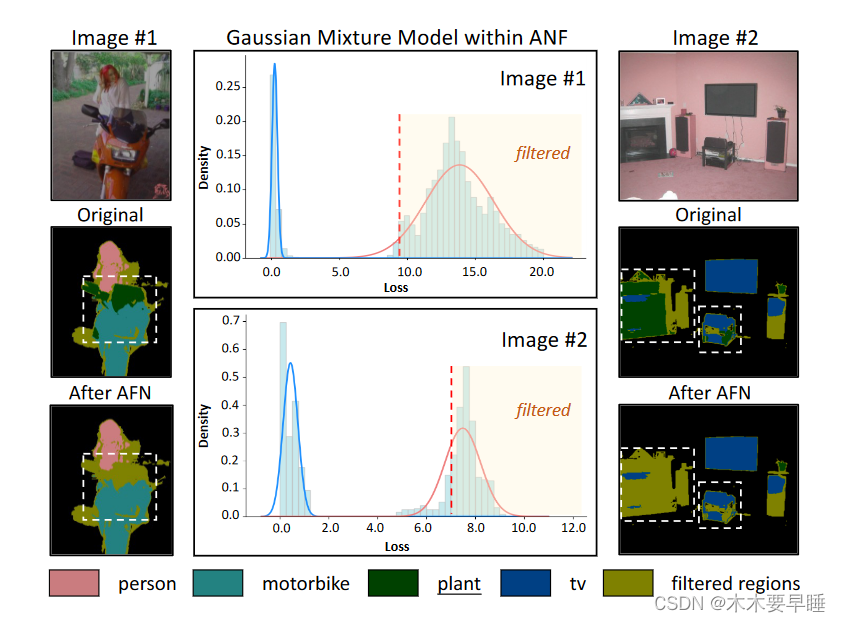
为此,我们开发了一种自适应噪声过滤策略,通过损失分布来区分噪声伪标签和干净伪标签,如图 4 所示。具体来说,对于带有分割图 P 和 CAM 伪标签 Y 的输入图像 X,我们假设每个像素 x∈X 的损失(定义为 lx = CE (P (x) , Y (x)))是从所有像素的高斯混合物模型(GMM)P(x) 中采样的,该模型有两个分量,即干净的 c 和嘈杂的 n:

其中 N (μ, σ2) 表示一个高斯分布,wn、μc、σc 和 wn、μn、σn 分别对应两个分量的权重、均值和方差。其中,损失值高的分量对应于噪声分量。通过期望最大化算法[25],我们可以推断出噪声概率ρn(lx),这相当于后验概率 P(noise | lx, μn, (σn)2) 。如果 ρn(lx)>γ,则相应像素将被归类为噪声。需要注意的是,并非所有的伪标签 Y 都是由噪声组成的,因此损失分布可能不具有两个清晰的高斯分布。因此,我们还要测量 μc 和 μn 之间的距离。如果 (μn - μc) ≤ η,则所有像素伪标签都将被视为干净标签。最后,噪声像素伪标签的集合确定为:
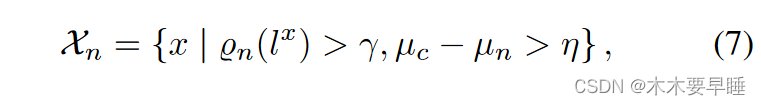
在分割监督中,它们被排除在外。在 DuPL 中,每个子网的伪标签都独立执行自适应噪声过滤策略。
Every Pixel Matters(每个像素都很重要):在单级 WSSS 中,丢弃可能包含噪声的不可靠伪标签是一种常见的做法,以确保分割或其他辅助监督的质量[39, 40, 44]。虽然我们在分割训练中逐渐引入了更多像素,但由于 CAM 的语义模糊性,仍有许多不可靠的伪标签被丢弃。通常情况下,在整个训练阶段,不可靠区域往往存在于非区分区域、边界和背景区域。这种操作可能会导致分割头在这些区域缺乏足够的监督。
为了解决这一局限性,我们将伪标签不可靠的区域视为无标签样本。尽管没有明确的伪标签来监督这些区域的分割,但我们可以对分割头进行正则化,以便在输入同一图像的扰动版本时输出一致的预测结果。一致性正则化隐含地要求模型符合平滑性假设[6, 20],这为这些区域提供了额外的监督。具体来说,我们首先应用强增强 φ对输入图像φ(X) → e X 进行扰动,然后将其输入给子网,由ψs i 得到分割预测值 e Pi。利用在 φ 中进行与监督相同仿射变换的伪标签 φ′(Yi),第 i 个子网络的一致性正则化公式为:

其中 Mi 是掩码,表示第 i 个子网络的伪标签不可靠的过滤像素。过滤后的像素掩码为 1,否则为 0。我们的双学生框架的总正则化损失为 Lreg = Lreg 1 + Lreg 2。该损失是针对每幅图像计算的,总损失是所有图像的平均值。
实验:
略

总结:
本研究旨在解决 CAM 确认偏差问题,并充分利用 CAM 伪标签实现更好的 WSSS。具体来说,我们开发了一种双学生架构,其中两个子网相互为另一个子网提供伪标签,经验证明这种架构能很好地应对 CAM 确认偏差。在训练过程中,随着 CAM 激活情况的改善,我们逐渐将更多像素引入监督,以进行充分的分割训练。我们通过提出自适应噪声过滤策略,克服了上述操作带来的过多噪声伪标签。这种值得信赖的渐进式学习模式大大提高了 WSSS 的性能。受 "每个像素都很重要 "这一理念的启发,我们没有丢弃不可靠的标签,而是通过一致性正则化来充分利用它们。实验结果表明,DuPL 的性能明显优于其他单阶段竞争者,而且与多阶段解决方案相比,DuPL 的性能更具竞争力。
这篇关于【弱监督语义分割】DuPL:双学生鲁棒性弱监督语义分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







