本文主要是介绍HQ-Edit、MaxFusion、Ctrl-Adapter、EdgeRelight360、Video2Game,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文首发于公众号:机器感知
HQ-Edit、MaxFusion、Ctrl-Adapter、EdgeRelight360、Video2Game

Taming Latent Diffusion Model for Neural Radiance Field Inpainting

Neural Radiance Field (NeRF) is a representation for 3D reconstruction from multi-view images. Despite some recent work showing preliminary success in editing a reconstructed NeRF with diffusion prior, they remain struggling to synthesize reasonable geometry in completely uncovered regions. One major reason is the high diversity of synthetic contents from the diffusion model, which hinders the radiance field from converging to a crisp and deterministic geometry. Moreover, applying latent diffusion models on real data often yields a textural shift incoherent to the image condition due to auto-encoding errors. These two problems are further reinforced with the use of pixel-distance losses. To address these issues, we propose tempering the diffusion model's stochasticity with per-scene customization and mitigating the textural shift with masked adversarial training. During the analyses, we also found the commonly used pixel and perceptual losses are harmful in the NeRF inpaintin......
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing

This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performan......
MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models

Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional ef......
Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model

ControlNets are widely used for adding spatial control in image generation with different conditions, such as depth maps, canny edges, and human poses. However, there are several challenges when leveraging the pretrained image ControlNets for controlled video generation. First, pretrained ControlNet cannot be directly plugged into new backbone models due to the mismatch of feature spaces, and the cost of training ControlNets for new backbones is a big burden. Second, ControlNet features for different frames might not effectively handle the temporal consistency. To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion models, by adapting pretrained ControlNets (and improving temporal alignment for videos). Ctrl-Adapter provides diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbones, a......
EdgeRelight360: Text-Conditioned 360-Degree HDR Image Generation for Real-Time On-Device Video Portrait Relighting
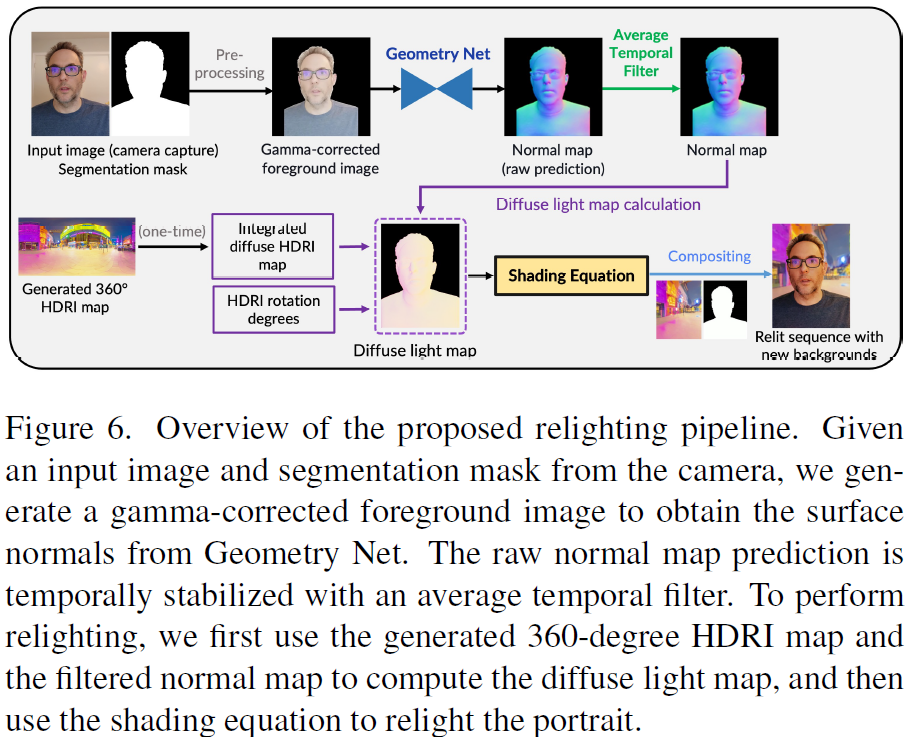
In this paper, we present EdgeRelight360, an approach for real-time video portrait relighting on mobile devices, utilizing text-conditioned generation of 360-degree high dynamic range image (HDRI) maps. Our method proposes a diffusion-based text-to-360-degree image generation in the HDR domain, taking advantage of the HDR10 standard. This technique facilitates the generation of high-quality, realistic lighting conditions from textual descriptions, offering flexibility and control in portrait video relighting task. Unlike the previous relighting frameworks, our proposed system performs video relighting directly on-device, enabling real-time inference with real 360-degree HDRI maps. This on-device processing ensures both privacy and guarantees low runtime, providing an immediate response to changes in lighting conditions or user inputs. Our approach paves the way for new possibilities in real-time video applications, including video conferencing, gaming, and augmented reality, ......
Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video

Creating high-quality and interactive virtual environments, such as games and simulators, often involves complex and costly manual modeling processes. In this paper, we present Video2Game, a novel approach that automatically converts videos of real-world scenes into realistic and interactive game environments. At the heart of our system are three core components:(i) a neural radiance fields (NeRF) module that effectively captures the geometry and visual appearance of the scene; (ii) a mesh module that distills the knowledge from NeRF for faster rendering; and (iii) a physics module that models the interactions and physical dynamics among the objects. By following the carefully designed pipeline, one can construct an interactable and actionable digital replica of the real world. We benchmark our system on both indoor and large-scale outdoor scenes. We show that we can not only produce highly-realistic renderings in real-time, but also build interactive games on top. ......
Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement

Image restoration, which aims to recover high-quality images from their corrupted counterparts, often faces the challenge of being an ill-posed problem that allows multiple solutions for a single input. However, most deep learning based works simply employ l1 loss to train their network in a deterministic way, resulting in over-smoothed predictions with inferior perceptual quality. In this work, we propose a novel method that shifts the focus from a deterministic pixel-by-pixel comparison to a statistical perspective, emphasizing the learning of distributions rather than individual pixel values. The core idea is to introduce spatial entropy into the loss function to measure the distribution difference between predictions and targets. To make this spatial entropy differentiable, we employ kernel density estimation (KDE) to approximate the probabilities for specific intensity values of each pixel with their neighbor areas. Specifically, we equip the entropy with diffusion model......
这篇关于HQ-Edit、MaxFusion、Ctrl-Adapter、EdgeRelight360、Video2Game的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!