本文主要是介绍MyBatisPlus详解(三)lambdaQuery、lambdaUpdate、批量新增、代码生成、Db静态工具、逻辑删除,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 2 核心功能
- 2.3 Service接口
- 2.3.3 Lambda
- 2.3.3.1 lambdaQuery
- 2.3.3.2 lambdaUpdate
- 2.3.4 批量新增
- 3 扩展功能
- 3.1 代码生成
- 3.2 静态工具
- 3.2.1 基本用法
- 3.2.2 代码实例
- 3.3 逻辑删除
前言
MyBatisPlus详解系列文章:
MyBatisPlus详解(一)项目搭建、@TableName、@TableId、@TableField注解与常见配置
MyBatisPlus详解(二)条件构造器Wrapper、自定义SQL、Service接口
2 核心功能
2.3 Service接口
2.3.3 Lambda
IService接口中还提供了Lambda功能来简化复杂查询及更新功能。
2.3.3.1 lambdaQuery
例如,要实现一个根据复杂条件查询用户信息的接口,接口文档如下:
| 接口 | 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|---|
| 根据条件查询用户列表 | GET | /user/list | UserQuery | List<User> |
查询条件UserQuery的字段如下:
- username:用户名关键字,可以为空
- status:用户状态,可以为空
- minBalance:最小余额,可以为空
- maxBalance:最大余额,可以为空
上述条件有可能为空,因此在查询时需要做判断。
首先定义一个查询实体类UserQuery:
// com.star.learning.pojo.UserQuery@Data
public class UserQuery {private String username;private Integer status;private Integer minBalance;private Integer maxBalance;
}
接着在UserController类中编写一个list()方法:
// com.star.learning.controller.UserController@GetMapping("/list")
public List<User> list(UserQuery userQuery) {// 1.组织条件String username = userQuery.getUsername();Integer status = userQuery.getStatus();Integer minBalance = userQuery.getMinBalance();Integer maxBalance = userQuery.getMaxBalance();System.out.println("根据条件查询用户列表 => " + userQuery);LambdaQueryWrapper<User> wrapper = new QueryWrapper<User>().lambda().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance);// 2.查询用户List<User> users = userService.list(wrapper);System.out.println("查询结果 => " + userQuery);return users;
}
在上述代码进行组织条件时,使用了username != null这样的判断语句,它的效果就和Mapper文件的<if>标签一样,只有当条件成立时才会添加这个查询条件,从而实现动态查询。
调用/user/list?username=o&minBalance=500,控制台打印信息如下:
根据条件查询用户列表 => UserQuery(username=o, status=null, minBalance=500, maxBalance=null)
==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM t_user WHERE (username LIKE ? AND balance >= ?)
==> Parameters: %o%(String), 500(Integer)
<== Total: 1
查询结果 => [User(id=3, username=Hope, password=123, phone=13900112222, info={"age": 25, "intro": "上进青年", "gender": "male"}, status=1, balance=19800, createTime=2024-04-21T10:13:35, updateTime=2024-04-21T18:48:28)]
可见,在上述SQL语句中只有username和minBalance是查询条件,其余两个字段均没有作为查询条件。
上述代码还可以继续简化,我们无需通过new的方式来创建Wrapper,而是直接调用lambdaQuery方法:
// com.star.learning.controller.UserController@GetMapping("/list")
public List<User> list(UserQuery userQuery) {// 1.组织条件String username = userQuery.getUsername();Integer status = userQuery.getStatus();Integer minBalance = userQuery.getMinBalance();Integer maxBalance = userQuery.getMaxBalance();System.out.println("根据条件查询用户列表 => " + userQuery);// 2.查询用户List<User> users = userService.lambdaQuery().like(username != null, User::getUsername, username).eq(status != null, User::getStatus, status).ge(minBalance != null, User::getBalance, minBalance).le(maxBalance != null, User::getBalance, maxBalance).list();System.out.println("查询结果 => " + users);return users;
}
可以发现,lambdaQuery方法中除了可以构建条件,还可以在链式编程的最后添加一个list(),告诉MP调用结果需要是一个List集合。
再次调用/user/list?username=o&minBalance=500接口,执行结果是一致的。
MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果,除了使用list()返回集合结果,还可以使用one()返回1个结果,使用count()返回计数结果。
2.3.3.2 lambdaUpdate
与lambdaQuery()方法类似,IService中的lambdaUpdate()方法可以非常方便的实现复杂更新业务。
例如有这样一个需求:根据id修改用户余额时,如果扣减后余额为0,则将用户status修改为冻结状态(2)。
也就是说,在扣减用户余额时,需要对用户剩余余额做出判断,如果发现剩余余额为0,则应该将status修改为2,这就是说update语句的set部分是动态的。
修改UserServiceImpl实现类中的deductBalance()方法:
// com.star.learning.service.impl.UserServiceImpl@Override
public void deductBalance(Long userId, Integer money) {// 1.查询用户User user = getById(userId);System.out.println(user);// 2.判断用户状态if (user == null || user.getStatus() == 2) {throw new RuntimeException("用户状态异常");}// 3.判断用户余额if (user.getBalance() < money) {throw new RuntimeException("用户余额不足");}// 4.扣减余额int remainBalance = user.getBalance() - money;lambdaUpdate()// 更新余额.set(User::getBalance, remainBalance)// 动态判断是否更新status.set(remainBalance == 0, User::getStatus, 2)// 条件.eq(User::getId, userId)// 乐观锁.eq(User::getBalance, user.getBalance()).update();// UpdateWrapper<User> wrapper = new UpdateWrapper<User>()// .eq("id", userId);// userMapper.deductBalanceByIds(money, wrapper);
}
调用/user/4/deduction/400接口,控制台打印信息如下:
扣减id=4的用户的余额400
==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM t_user WHERE id=?
==> Parameters: 4(Long)
<== Total: 1
User(id=4, username=Thomas, password=123, phone=17701265258, info={"age": 29, "intro": "伏地魔", "gender": "male"}, status=1, balance=400, createTime=2024-04-21T10:13:35, updateTime=2024-04-21T16:10:20)
==> Preparing: UPDATE t_user SET balance=?,status=? WHERE (id = ? AND balance = ?)
==> Parameters: 0(Integer), 2(Integer), 4(Long), 400(Integer)
<== Updates: 1
可以看到,SQL语句中同时将status字段也更新了。
2.3.4 批量新增
现有以下单元测试,逐条向数据库插入10000条数据:
@Test
public void testSaveOneByOne() {long b = System.currentTimeMillis();for (int i = 1; i <= 10000; i++) {userService.save(buildUser(i));}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}private User buildUser(int i) {User user = new User();user.setUsername("user_" + i);user.setPassword("123");user.setPhone("" + (18688190000L + i));user.setBalance(2000);user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");return user;
}
执行单元测试,控制台打印信息如下:
耗时:28069
然后再测试一下使用MybatisPlus的批量新增saveBatch()方法:
@Test
public void testBatch() {List<User> userList = new ArrayList<>(1000);long b = System.currentTimeMillis();for (int i = 1; i <= 10000; i++) {userList.add(buildUser(i));// 每1000条插入一次数据if(i % 1000 == 0) {userService.saveBatch(userList);userList.clear();}}long e = System.currentTimeMillis();System.out.println("耗时:" + (e - b));
}
执行单元测试,控制台打印信息如下:
耗时:4675
可以看到,使用了MybatisPlus的批量新增saveBatch()方法后,比逐条新增所用的时间缩短了7倍左右,性能大大提升。
实际上,MybatisPlus的批处理是基于PrepareStatement的预编译模式,将批量insert语句准备好后批量进行提交,因此最终在数据库执行时还是会有执行多条insert语句。
而如果想要得到最佳性能,最好是将多条SQL合并为一条。在MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements,用于设置是否重写批处理的statement语句,默认值为false。
因此,想要将多条SQL合并为一条,只需要修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true。

修改完成后,再次测试插入10000条数据,控制台打印信息如下:
耗时:2263
可见,性能得到进一步地提升,且SQL语句被合并成了一条:
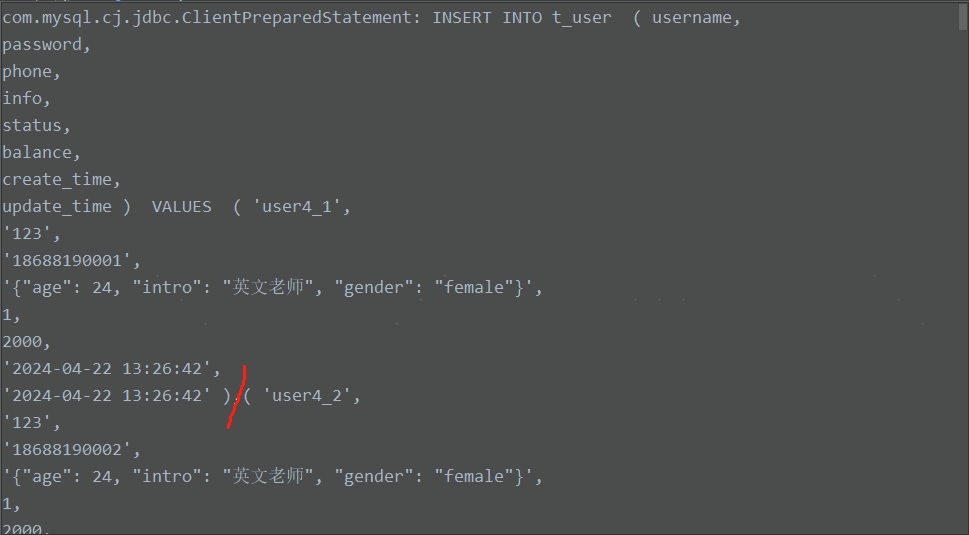
提示:测试项目中原本使用的MySQL驱动版本是5.1.48,无法实现合并SQL语句的功能;
而将其版本更新到8.0.16之后,就可以实现了。
3 扩展功能
3.1 代码生成
MybatisPlus官方提供了代码生成器根据数据库表结构生成POJO、Mapper、Service等相关代码。只不过代码生成器同样要编码使用,相对麻烦。
但在IDEA中,有一款MybatisPlus的插件,它可以基于图形化界面完成MybatisPlus的代码生成,非常简单。
下面就以数据库中的t_address表来演示代码自动生成。
在IDEA顶部菜单栏中,找到Tools菜单,选择Config Database:

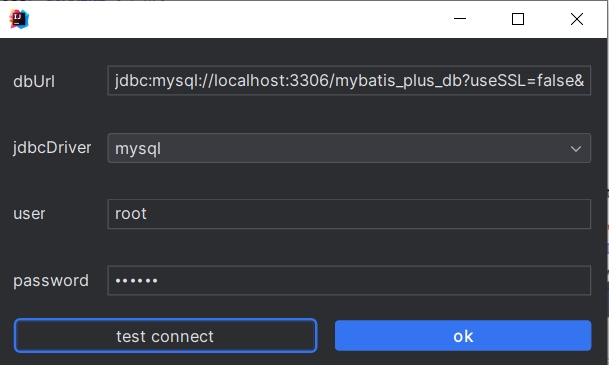
在弹出的窗口中填写数据库连接的基本信息,并保存:
然后再次在IDEA顶部菜单栏中,找到Tools菜单,选择Code Generator:

在弹出的窗口中填写要生成的代码的基本信息:
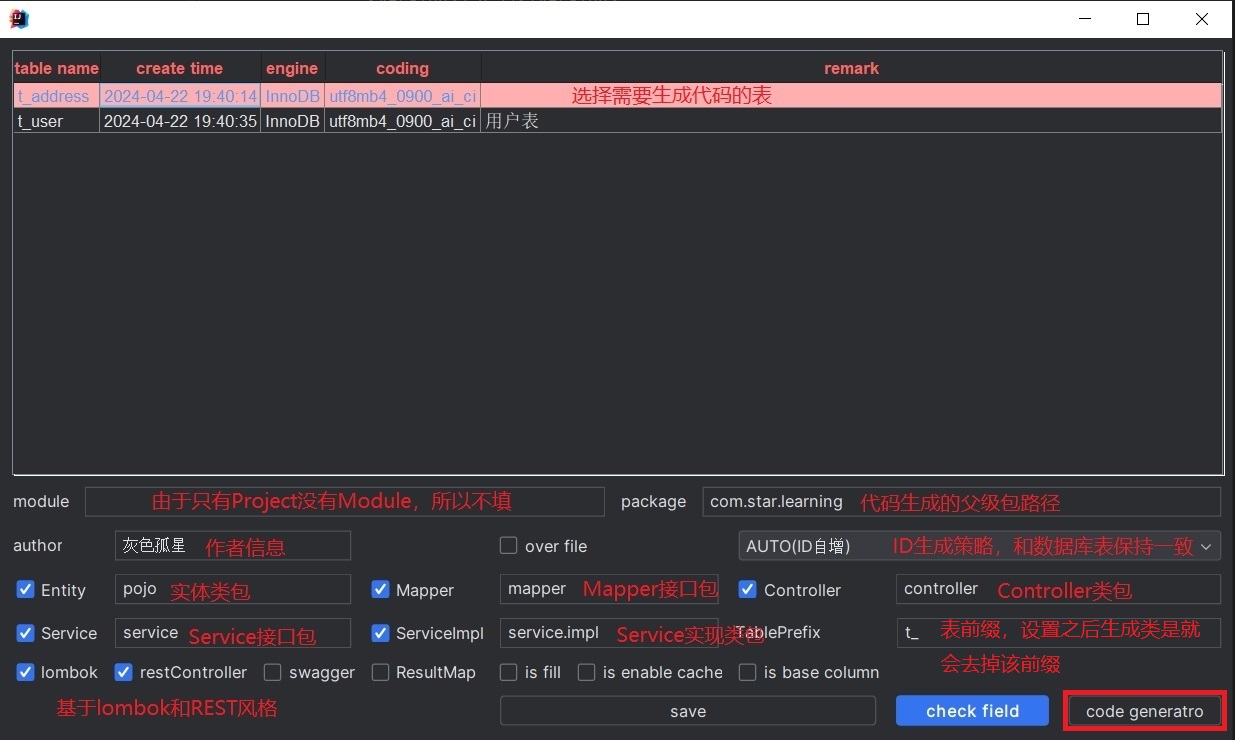
点击code generatro,即可在指定包下生成对应的类:
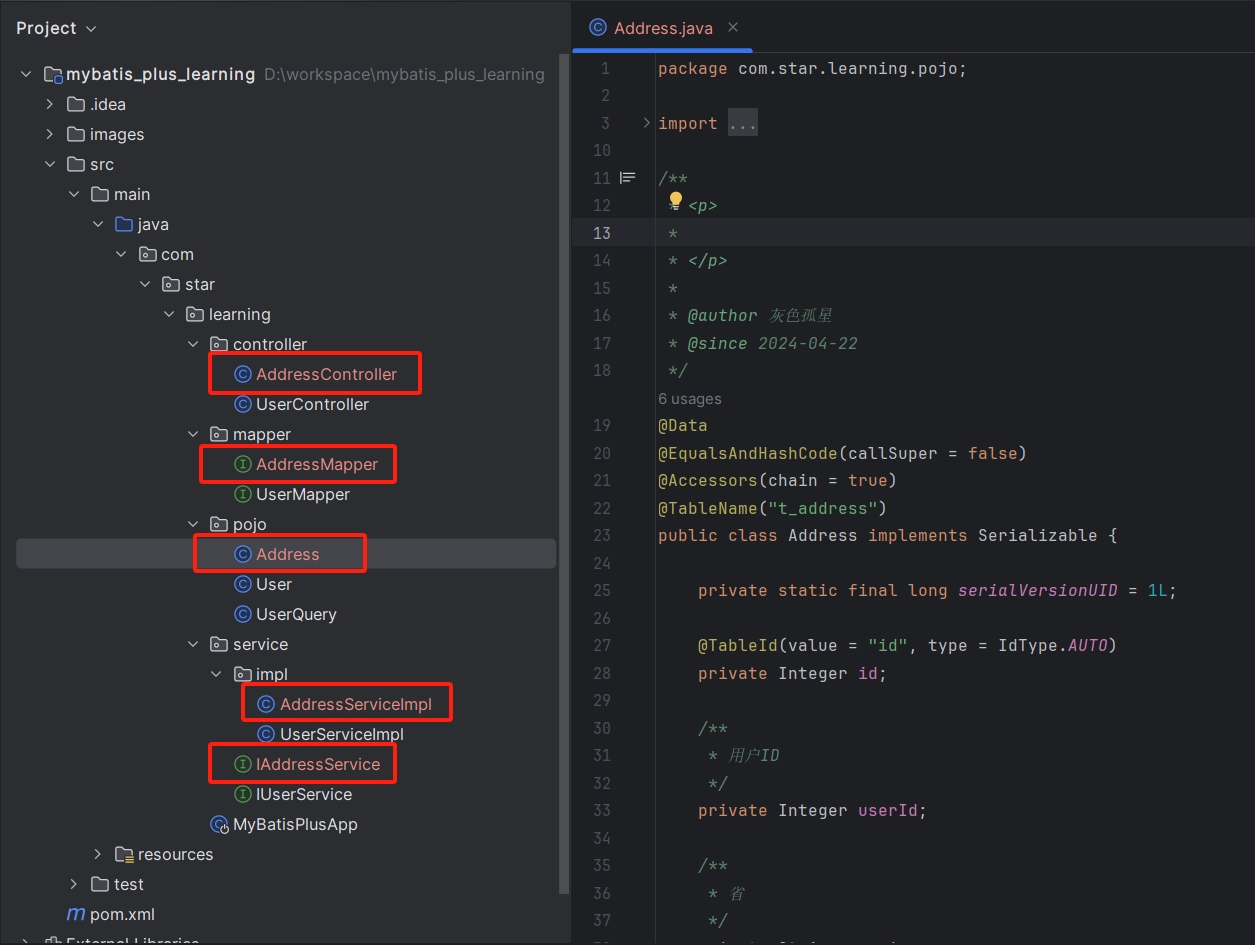
当然生成的代码并一定完全符合要求,这时只需要根据要求做简单地修改即可,比全部手写省事多了。
3.2 静态工具
3.2.1 基本用法
有的时候Service之间也会相互调用,但很有可能会出现循环依赖问题。
为了避免这个问题,MybatisPlus提供一个静态工具类:Db类,它其中的一些静态方法与IService中的方法基本一致,也可以实现CRUD功能:
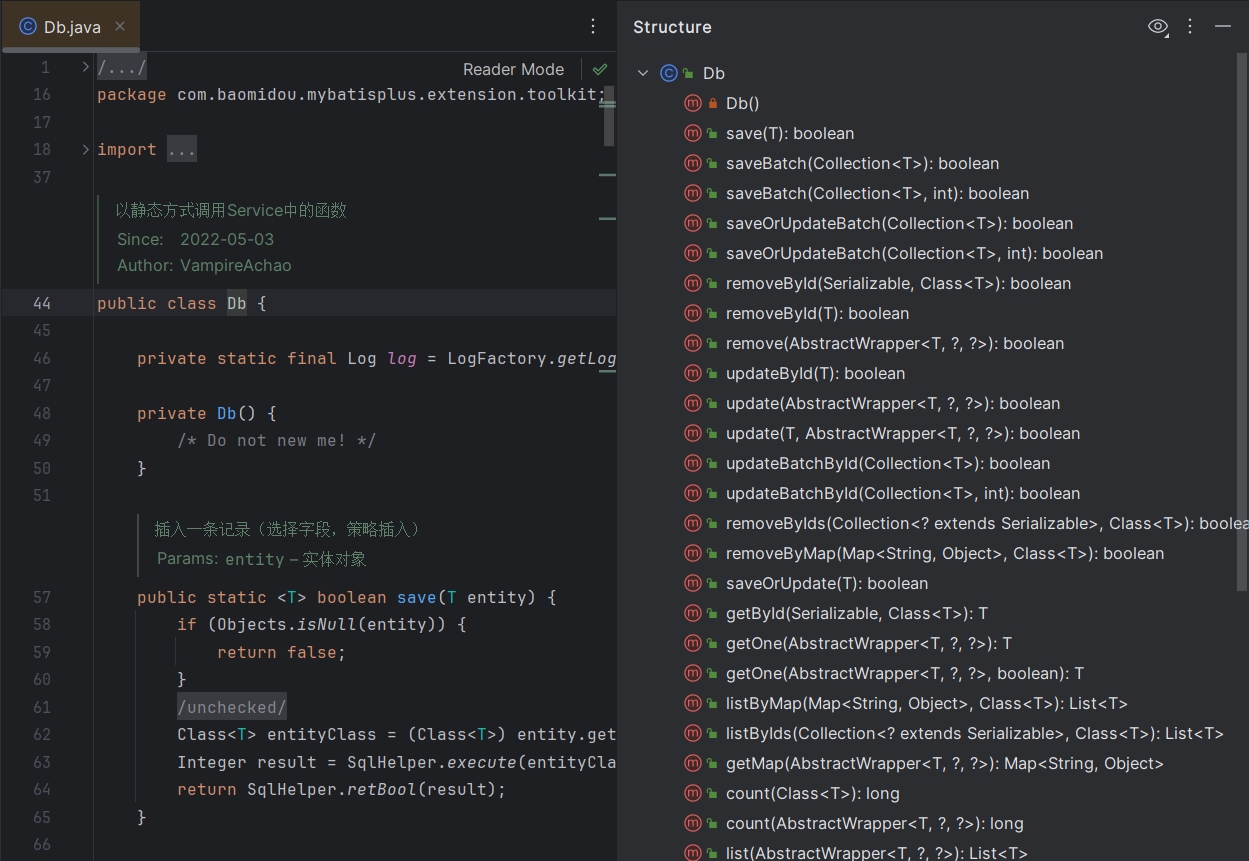
其基本使用方法如下:
@Test
public void testDb() {// 利用Db实现根据ID查询User user = Db.getById(1L, User.class);System.out.println(user);System.out.println("==========");// 利用Db实现复杂条件查询List<User> userList = Db.lambdaQuery(User.class).like(User::getUsername, "o").ge(User::getBalance, 1000).list();userList.forEach(System.out::println);System.out.println("==========");// 利用Db实现条件更新Db.lambdaUpdate(User.class).set(User::getBalance, 2000).eq(User::getUsername, "Rose").update();}
执行以上单元测试,控制台打印信息如下:
==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM t_user WHERE id=?
==> Parameters: 1(Long)
<== Total: 1
User(id=1, username=Jack, password=123, phone=13900112224, info={"age": 20, "intro": "佛系青年", "gender": "male"}, status=1, balance=1600, createTime=2024-04-22T19:40:36, updateTime=2024-04-22T19:40:36)
==========
==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM t_user WHERE (username LIKE ? AND balance >= ?)
==> Parameters: %o%(String), 1000(Integer)
<== Total: 1
User(id=3, username=Hope, password=123, phone=13900112222, info={"age": 25, "intro": "上进青年", "gender": "male"}, status=1, balance=100000, createTime=2024-04-22T19:40:36, updateTime=2024-04-22T19:40:36)
==========
==> Preparing: UPDATE t_user SET balance=? WHERE (username = ?)
==> Parameters: 2000(Integer), Rose(String)
<== Updates: 1
3.2.2 代码实例
下面实现一个需求:改造根据id查询用户信息的接口,在查询用户的同时返回用户收货地址列表。
- 1)修改User对象,添加收货地址列表属性:
// com.star.learning.pojo.User@Data
@TableName("t_user")
public class User {// .../*** 收货地址列表*/@TableField(exist = false)private List<Address> addressList;}
- 2)修改UserController中根据id查询用户信息的
getById()方法:
// com.star.learning.controller.UserController@GetMapping("/{id}")
public User getById(@PathVariable("id") Long userId) {// User user = userService.getById(userId);// System.out.println("根据id查询用户 => " + user);// 基于自定义Service方法查询User user = userService.queryUserAndAddressById(userId);System.out.println("根据id查询用户及其收货地址信息 => " + user);return user;
}
- 3)在IService接口中定义
queryUserAndAddressById()方法,并在UserServiceImpl类中具体实现:
// com.star.learning.service.IUserServiceUser queryUserAndAddressById(Long userId);
// com.star.learning.service.impl.UserServiceImpl@Override
public User queryUserAndAddressById(Long userId) {// 1.查询用户User user = getById(userId);if (user == null) {return null;}// 2.使用Db来查询收货地址List<Address> addressList = Db.lambdaQuery(Address.class).eq(Address::getUserId, userId).list();// 3.处理返回user.setAddressList(addressList);return user;
}
- 4)调用
/user/1接口,控制台打印信息如下:
==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM t_user WHERE id=?
==> Parameters: 1(Long)
<== Total: 1
==> Preparing: SELECT id,user_id,province,city,town,mobile,street,contact,is_default,notes,deleted FROM t_address WHERE (user_id = ?)
==> Parameters: 1(Long)
<== Total: 2
根据id查询用户及其收货地址信息 => User(id=1, username=Jack, password=123, phone=13900112224, info={"age": 20, "intro": "佛系青年", "gender": "male"}, status=1, balance=1600, createTime=2024-04-22T19:40:36, updateTime=2024-04-22T19:40:36, addressList=[Address(id=2, userId=1, province=北京, city=北京, town=朝阳区, mobile=13700221122, street=修正大厦, contact=Jack, isDefault=false, notes=null, deleted=false), Address(id=3, userId=1, province=上海, city=上海, town=浦东新区, mobile=13301212233, street=航头镇航头路, contact=Jack, isDefault=true, notes=null, deleted=false)])
可见,在查询地址时,采用了Db类的静态方法,避免了注入AddressService,从而减少了循环依赖的风险。
3.3 逻辑删除
对于一些比较重要的数据,往往会采用逻辑删除的方案,即在表中添加一个字段标记数据是否被删除,当删除数据时把标记置为true,当查询时过滤掉标记为true的数据。
但是一旦采用逻辑删除,查询和删除逻辑就会变得更加复杂。为此,MybatisPlus添加了对逻辑删除的支持。
但是要注意,只有MybatisPlus生成的SQL语句才支持自动的逻辑删除,自定义SQL需要自己手动处理逻辑删除。
例如,在t_address表及其对应的实体Address类中有一个逻辑删除字段deleted,默认值为0:
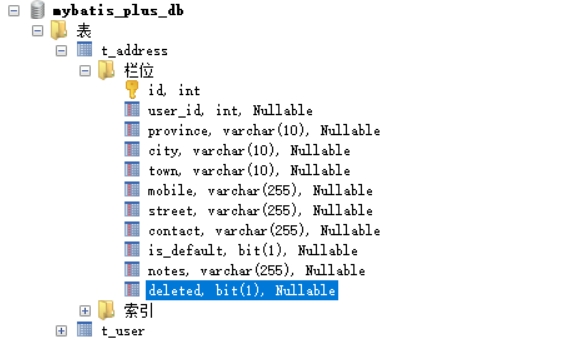
要开启MyBatisPlus的逻辑删除功能,需要在application.yml中配置逻辑删除字段:
# src/main/resources/application.yamlmybatis-plus:global-config:db-config:logic-delete-field: deleted # 全局逻辑删除的实体字段名logic-delete-value: 1 # 逻辑已删除值(默认为 1)logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
接下来编写测试代码:
@Test
public void testDeleteByLogic() {addressService.removeById(1);
}
执行以上单元测试,控制台打印信息如下:
==> Preparing: UPDATE t_address SET deleted=1 WHERE id=? AND deleted=0
==> Parameters: 1(Integer)
<== Updates: 1
可见,SQL语句并不是DELETE语句,而是UPDATE语句,将deleted字段设置为1。
再来测试以下查询操作:
@Test
void testQuery() {List<Address> list = addressService.list();list.forEach(System.out::println);
}
执行以上单元测试,控制台打印信息如下:
==> Preparing: SELECT id,user_id,province,city,town,mobile,street,contact,is_default,notes,deleted FROM t_address WHERE deleted=0
==> Parameters:
<== Total: 10
可见,SQL语句自动添加了一个条件:WHERE deleted=0。
总的来说,开启了逻辑删除功能以后,我们就可以像普通删除一样做CRUD,基本不用考虑代码逻辑问题。
同时,逻辑删除本身也是有问题的,比如:
- 会导致数据库表垃圾数据越来越多,从而影响查询效率;
- SQL中全都需要对逻辑删除字段做判断,影响查询效率。
…
本节完,更多内容请查阅分类专栏:MyBatisPlus详解
本文涉及代码下载地址:https://gitee.com/weidag/mybatis_plus_learning.git
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析(已完结)
- MyBatis3源码深度解析(已完结)
- Redis从入门到精通(已完结)
- 再探Java为面试赋能(持续更新中…)
这篇关于MyBatisPlus详解(三)lambdaQuery、lambdaUpdate、批量新增、代码生成、Db静态工具、逻辑删除的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





