本文主要是介绍详细解读ControlNet作者最新力作:透明图层的生成模型LayerDiffusion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Diffusion models代码解读:入门与实战
前言:ControlNet的作者Lvmin Zhang的新作品LayerDiffusion,可以用于生成四通道带有透明图层的图片,这对于设计和落地是巨大的利好,因为业务场景下会有很多背景替换、人物替换的需求,从此告别抠图!这篇博客详细解读背后的原理,并解读代码和复现实验。
目录
贡献概述
方法详解
当前问题
整理流程
Loss约束
多透明图层生成
数据收集
效果复现
论文和代码
贡献概述
生成透明图像的方法,可以生成单个透明图像或多个透明层。理论上任何LDM都可以通过这种方法对其进行微调转换为透明图像生成器。
该方法学习了一个“潜在透明度”,将 alpha 通道透明度编码到预训练的潜在扩散模型的潜在流形中,通过调节添加的透明度作为潜在偏移量来保持生成质量,以避免破坏潜在分布,对预训练模型的原始潜在分布的变化最小。
方法详解
当前问题
1、透明图层的图像没有大规模数据集。
2、SD对潜在空间非常敏感,对潜在空间的数据分布稍微调整也会严重影响推理效果。所以直接微调让其生成透明图像会破坏原有的潜在空间分布。
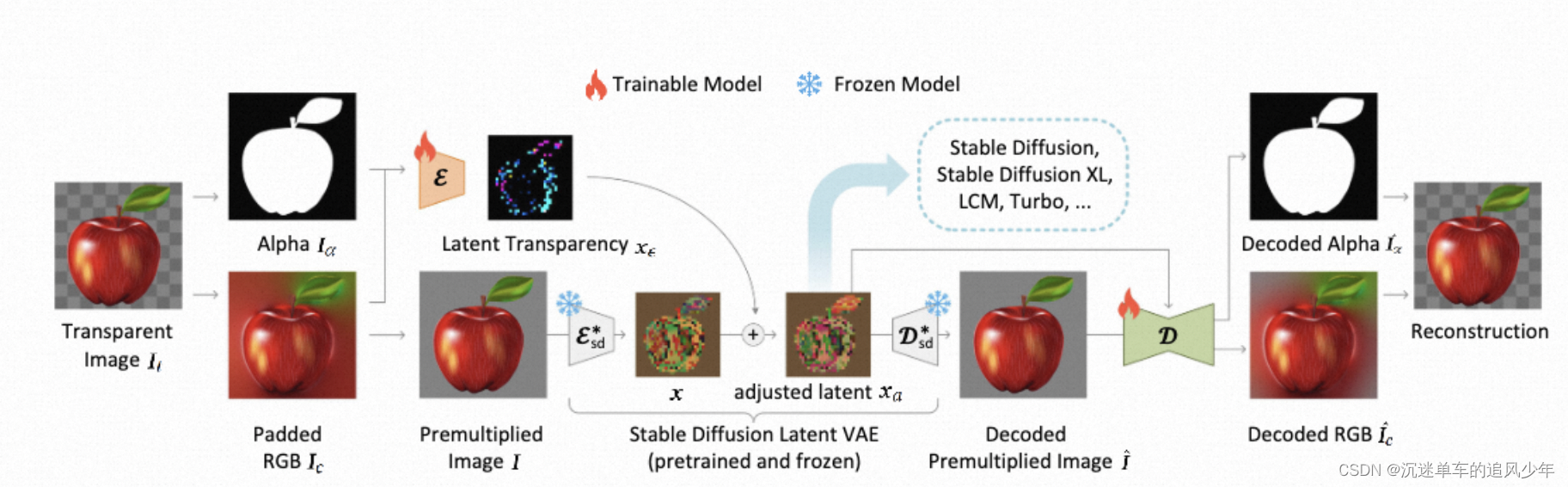
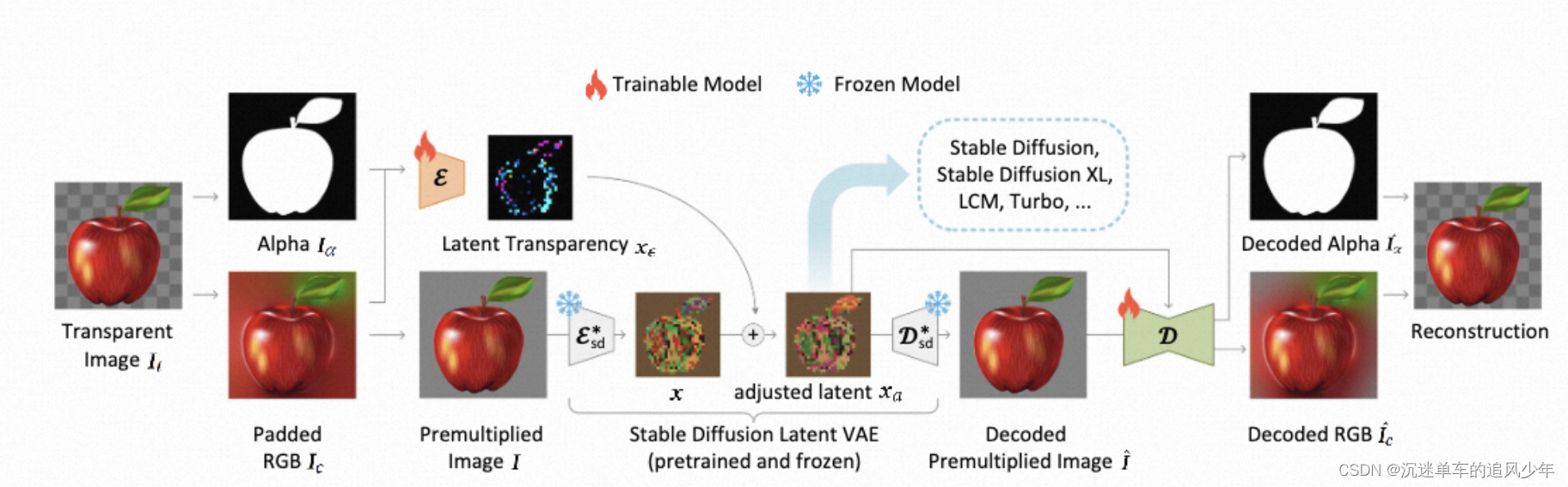
整理流程
先将透明图像(四通道)分解成RGB图像(三通道)和alpha通道的图像(单通道),将RGB图像变成Premultiplied图片经过SD编码器与潜在透明图像相加,生成的Premultiplied图片(四通道),经过解码器得到alpha通道的图像和RGB图像(三通道)。
透明编码器和透明解码器:从头训练一个专门针对透明图像的编码器,这个编码器的输入不仅有alpha通道的图像,还有像素空间的图像。透明解码器的输入是调整后的潜在噪声和重建后的RGB图像。
Loss约束
身份损失:因为在原有的潜在分布上加上了alpha通道的噪声会破坏原有的噪声分布,所以用一个身份损失约束对潜在空间偏移量的修改。
重建损失:用重建后的alpha通道图像和重建后的RGB图像与输入图像计算损失:
![]()
鉴别损失:引入PatchGAN的鉴别器损失:

最终的损失由三个损失加权得到:
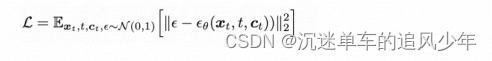
默认情况下使用λrecon = 1, λidentity = 1, λdisc = 0.01
微调损失:由于调整后的潜在空间特征分布,与原始预训练的潜在空间特征分布分布保持一致。因此可以直接在调整后的潜在空间上对Stable Diffusion进行微调。微调公式和大部分扩散模型微调的公式一致,唯一变化是输入参数不一致:
多透明图层生成
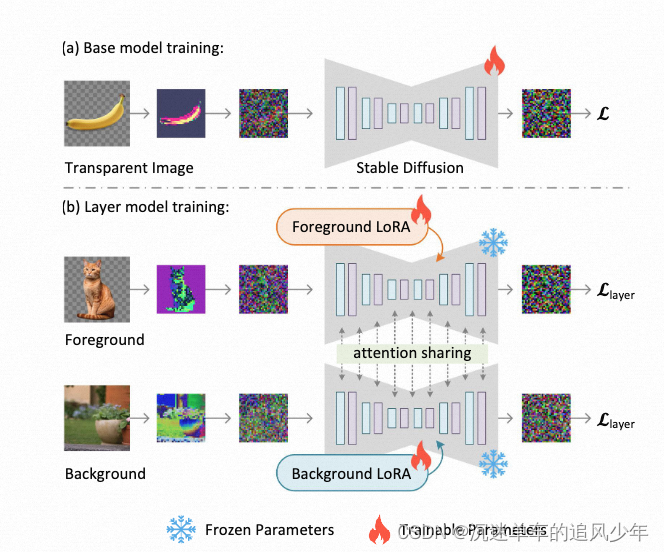
前景的噪声潜在图像被表示为xf,背景的噪声潜在图像被表示为xb。然后训练了两个LoRAs,一个用于前景(由θf参数化),另一个用于背景(由θb参数化),以去噪这两个编码后的图像。
这两个模型之间的注意力部分的权重共享,训练目标相互独立:
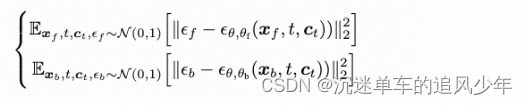
为了实现多个层的一致生成,研究者们在扩散模型的每个注意力层中,将“前景潜在空间向量”和“背景潜在空间向量”进行拼接,使得两个独立的扩散过程可以合并为一个共同优化的大型模型。合并后的噪声被表示为:
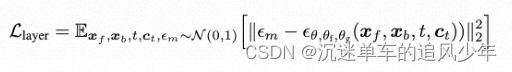
数据收集
使用human-in-the-loop(人类会全程参与数据的筛选和编辑)的方法,共收集了1M 透明图像,并将这些单层透明图层样本的数据扩展到多层样本。扩展的方法如下:
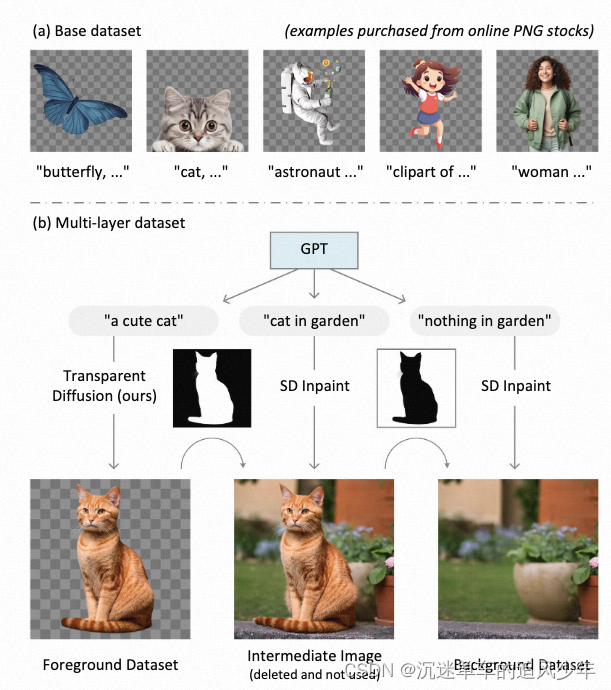
用GPT生成前景+背景的提示词,前景提示通过训练好的透明图像生成器处理,以获得透明图像。使用SDXL修复模型将所有Alpha值小于1的像素修复,以获得中间图像。反转Alpha掩模,进行腐蚀操作,然后再次使用背景提示进行修复,以获得背景层。重复这个过程1M次,以生成大约1M对层。
效果复现


论文和代码
https://github.com/KaustubhPatange/Diffuser-layerdiffuse
这篇关于详细解读ControlNet作者最新力作:透明图层的生成模型LayerDiffusion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







