本文主要是介绍迭代加深搜索(图的路径查找),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概念
优点
缺点
如何剪枝(八数码)
剪枝策略:
深度优先搜索(DFS)和广度优先搜索(BFS)
深度优先搜索(DFS)
广度优先搜索(BFS)
比较
应用场景
经典案例(图的路径查找)
代码分析
概念
迭代加深搜索(Iterative Deepening DFS,IDDFS)是一种结合了深度优先搜索(DFS)和广度优先搜索(BFS)思想的搜索方法。它通过逐步增加搜索深度来寻找解决方案,每次限制搜索深度的DFS。如果在当前深度下找到了解决方案,那么就返回该解决方案;否则,增加搜索深度并重新开始搜索。
迭代加深搜索(Iterative Deepening Search, IDS)是一种结合了深度优先搜索(DFS)和广度优先搜索(BFS)特性的搜索算法。IDS的基本思想是从深度为1开始逐渐增加搜索的深度限制,直到找到目标或确定目标不存在为止。在每次迭代中,它使用深度优先搜索来遍历图,直到达到当前的深度限制。
优点
它可以在时间和空间上更有效地利用资源。它可以在搜索空间较小的情况下快速找到解决方案,而在搜索空间较大的情况下,则可以通过逐步增加搜索深度来避免过多的搜索。同时,由于它在层数上采用BFS思想来逐步扩大DFS的搜索深度,因此能够解决DFS可能陷入递归无法返回的问题,并避免BFS可能导致的队列空间爆炸问题。
缺点
它可能会导致重复搜索相同的状态,因为在每次增加搜索深度时,搜索树的一部分可能被重新搜索。此外,如果没有一个合适的方法来剪枝,迭代加深搜索也可能会很容易超时。
在实际应用中,迭代加深搜索通常用于解决搜索树非常深但答案可能在浅层节点的问题。通过结合DFS和BFS的思想,以及可能使用的剪枝技术,如IDA*估价函数,迭代加深搜索可以在一定程度上提高搜索效率。
如何剪枝(八数码)
八数码网上案例很多,这里我就不一一介绍了,想了解的同学,问下度娘即可
在八数码(Eight Puzzle)问题中,剪枝(pruning)是一种优化回溯搜索过程的策略,通过避免搜索那些明显不会得到解决方案的部分来减少搜索空间。对于八数码问题,剪枝通常基于评估函数(heuristic function)来实现,该函数能够估计从当前状态到达目标状态所需的最小步数。
剪枝策略:
-
使用评估函数:评估函数可以根据当前棋盘的排列情况来预测到达目标状态所需的最小步数。一个简单的评估函数可以计算每个数字与其在目标状态中的位置之间的距离之和。例如,如果数字1在初始棋盘上的位置为
(x, y),在目标棋盘上的位置为(goalX, goalY),那么该数字对评估函数的贡献可以是abs(x - goalX) + abs(y - goalY)。将所有数字的贡献相加,得到当前棋盘的评估值。 -
在搜索过程中,可以设置一个最大步数限制。如果某个状态的评估值加上已经走过的步数大于或等于这个限制,则可以认为该状态不可能到达目标状态,因此可以剪枝。
-
对称剪枝:
由于八数码问题中的数字排列是对称的(例如,旋转或镜像),因此可以利用这些对称性来剪枝。如果在搜索过程中遇到了一个已经通过旋转或镜像处理过的状态,那么可以跳过该状态的进一步搜索。 -
逆序剪枝:
如果在搜索过程中遇到了一个之前已经搜索过的状态(即该状态已经在搜索树中出现过),那么可以剪枝,因为继续搜索该状态只会得到之前已经找到的结果。 -
深度优先搜索与广度优先搜索的选择:
深度优先搜索(DFS)和广度优先搜索(BFS)都可以用于解决八数码问题。由于我们希望找到的是最短解决方案,因此BFS通常更适合,因为它会首先探索较浅层的节点。然而,BFS需要存储所有已经访问过的状态,这可能会消耗大量的内存。DFS不需要存储所有状态,但可能需要更复杂的剪枝策略来确保找到最短路径。
深度优先搜索(DFS)和广度优先搜索(BFS)
深度优先搜索(DFS,Depth-First Search)和广度优先搜索(BFS,Breadth-First Search)是两种常用的图遍历算法,用于遍历或搜索树或图的节点。它们各自具有不同的特点和应用场景。
深度优先搜索(DFS)
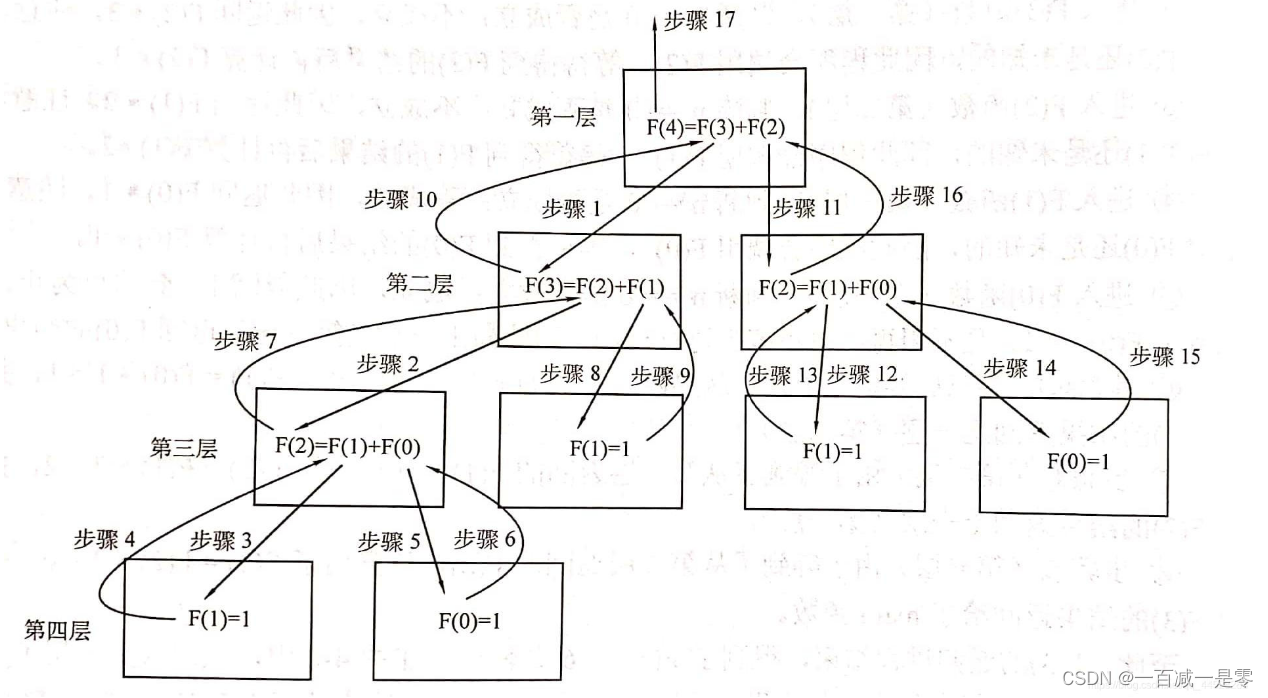
深度优先搜索是一种用于遍历或搜索树或图的算法。这个算法会尽可能深地搜索树的分支。当节点v的所在边都已被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
DFS通常使用栈(stack)数据结构来实现,因为它需要后进先出(LIFO)的特性来保存搜索路径。
广度优先搜索(BFS)
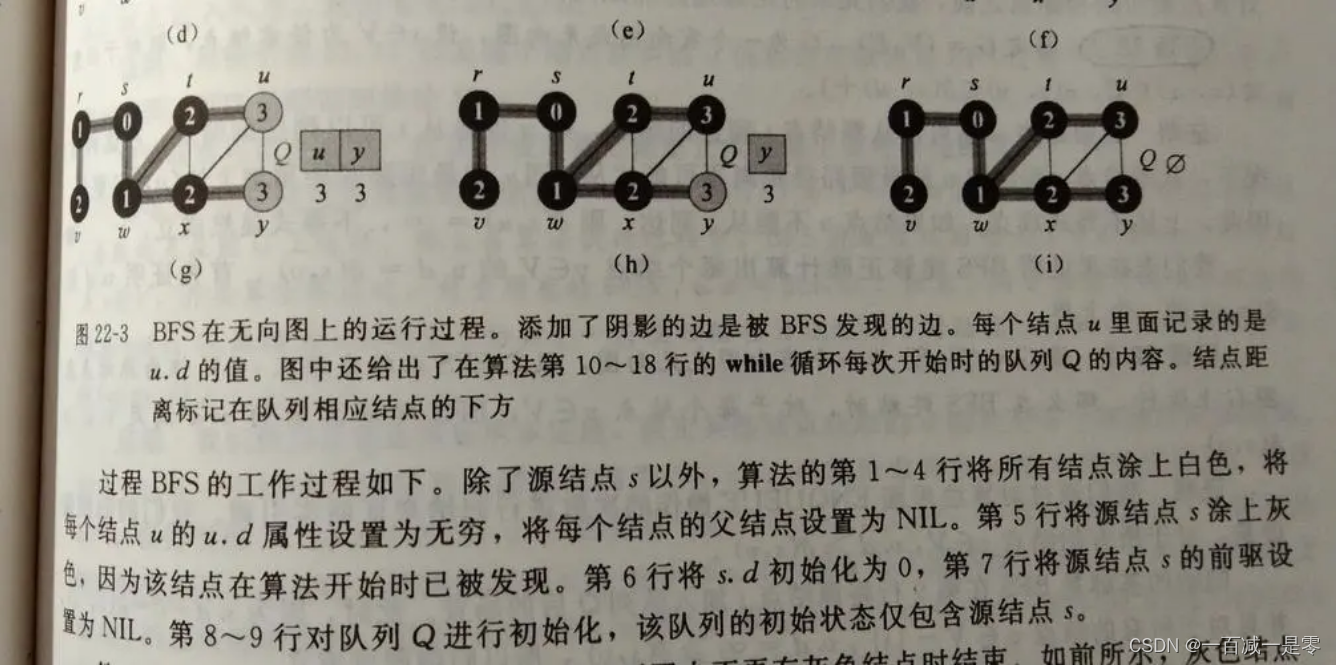
广度优先搜索是一种用于遍历或搜索树或图的算法。这个算法从根节点(或任意节点)开始,探索最近邻的节点,然后再进一步探索下一个层次的节点,依此类推。BFS使用队列(queue)数据结构来保存待探索的节点,这使得它能够按照节点被发现的顺序(即层次遍历顺序)来访问它们。
BFS通常用于查找最短路径,例如在无权图中找到从源节点到目标节点的最短路径。
比较
- 空间复杂度:DFS的空间复杂度通常较低,因为它只需要保存从源节点到当前节点的路径信息。然而,在最坏情况下,当图退化为链状时,DFS可能需要存储与图中节点数相同数量的信息。相比之下,BFS的空间复杂度可能更高,因为它需要存储所有已访问但尚未探索的节点。
- 时间复杂度:在平均情况下,DFS和BFS的时间复杂度都是O(V + E),其中V是节点数,E是边数。然而,在某些特定情况下,如搜索树或图的结构特殊时,两者的性能可能会有所不同。
- 应用:DFS常用于解决图论中的连通性问题、寻找桥或割点、拓扑排序等问题。BFS则常用于查找最短路径、解决迷宫问题、检测图中的环等问题。
应用场景
-
跨境电商物流路径优化:在跨境电商中,商品需要从仓库运送到客户手中,并可能经过多个转运中心。使用迭代加深搜索可以帮助找到最短或最经济的物流路径。通过将商品、供应商、客户和物流中心视为图中的节点,并利用迭代加深搜索来遍历这些节点及其关系,可以高效地找到最优路径。
-
人工智能游戏求解:在人工智能领域,迭代加深搜索常用于求解游戏的最优策略。例如,在棋类游戏中,玩家需要找到一系列的动作来赢得比赛。通过迭代加深搜索,AI可以逐步扩大搜索深度,从而找到能够赢得比赛的最优步骤序列。
-
图形设计和处理:在图形设计和处理中,迭代加深搜索可以用于寻找满足特定条件的图形结构。例如,在生成具有特定属性的图形或模式时,可以使用迭代加深搜索来探索可能的图形空间,并找到符合要求的解。
-
网络路由选择:在计算机网络中,路由器需要选择最佳的路径来传输数据包。迭代加深搜索可以帮助路由器在复杂的网络拓扑中找到最优的路由路径,确保数据包能够高效、准确地到达目的地。
-
知识图谱推理:在知识图谱中,节点代表实体,边代表实体之间的关系。迭代加深搜索可以用于在知识图谱中进行推理,找到满足特定条件的实体或关系路径。这对于智能问答、信息抽取等任务非常有用。

经典案例(图的路径查找)
package routine.suibi;import java.util.*;public class IterativeDeepeningSearch {// 图的节点类 static class Node {int id; // 节点编号 List<Node> neighbors; // 相邻节点列表 Node(int id) {this.id = id;this.neighbors = new ArrayList<>();}// 添加相邻节点 void addNeighbor(Node node) {neighbors.add(node);}@Overridepublic String toString() {return "Node{" + "id=" + id + '}';}}// 路径类 static class Path {List<Node> nodes; // 路径上的节点列表 int depth; // 路径深度 Path(Node startNode) {this.nodes = new ArrayList<>();this.nodes.add(startNode);this.depth = 1;}// 添加节点到路径中 void addNode(Node node) {nodes.add(node);depth++;}// 获取路径上的最后一个节点 Node getLastNode() {return nodes.get(nodes.size() - 1);}@Overridepublic String toString() {return "Path{" + "nodes=" + nodes + ", depth=" + depth + '}';}}// 迭代加深搜索算法 public static Path iterativeDeepeningSearch(Node start, Node goal) {int maxDepth = 0; // 初始化最大深度为0 while (true) {Path result = dfs(start, goal, maxDepth);if (result != null) {return result; // 找到路径,返回结果 }maxDepth++; // 增加最大深度限制,继续搜索 if (maxDepth > getMaxDepth(start, goal)) {break; // 超过最大可能深度,退出循环 }}return null; // 没有找到路径 }// 深度优先搜索辅助方法 private static Path dfs(Node current, Node goal, int maxDepth) {if (current.equals(goal)) {return new Path(current); // 到达目标节点,返回路径 }if (maxDepth <= 0) {return null; // 达到最大深度限制,返回null }for (Node neighbor : current.neighbors) {Path result = dfs(neighbor, goal, maxDepth - 1); // 递归搜索相邻节点 if (result != null) {result.addNode(current); // 将当前节点添加到路径中 return result; // 返回找到的路径 }}return null; // 没有找到路径 }// 获取从起点到终点的最大可能深度(可选,用于提前退出循环) private static int getMaxDepth(Node start, Node goal) {Queue<Node> queue = new LinkedList<>();Set<Node> visited = new HashSet<>();queue.add(start);visited.add(start);int depth = 0;while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; i++) {Node current = queue.poll();if (current.equals(goal)) {return depth; // 找到目标节点,返回当前深度 }for (Node neighbor : current.neighbors) {if (!visited.contains(neighbor)) {queue.add(neighbor);visited.add(neighbor);}}}depth++;}return -1; // 没有找到目标节点,返回-1(理论上这种情况不会发生,因为图是连通的) }public static void main(String[] args) {// 创建图的节点和边 Node A = new Node(1);Node B = new Node(2);Node C = new Node(3);Node D = new Node(4);// 添加边A.addNeighbor(B);A.addNeighbor(C);B.addNeighbor(C);B.addNeighbor(D);C.addNeighbor(D);// 执行迭代加深搜索Path path = iterativeDeepeningSearch(A, D);// 输出结果if (path != null) {System.out.println("找到路径: " + path);} else {System.out.println("没有找到路径");}}
}代码分析
- 节点和路径类定义:
Node类表示图中的一个节点,包含一个编号id和一个邻居节点列表neighbors。Path类表示从起点到某个节点的路径,包含一个节点列表nodes和路径的深度depth。
- 迭代加深搜索方法
iterativeDeepeningSearch:- 该方法接受起点
start和目标节点goal作为参数,返回从起点到目标节点的路径。 - 使用一个循环来逐渐增加最大深度限制
maxDepth,并在每次迭代中调用深度优先搜索方法dfs。 - 如果
dfs方法返回非空路径,则返回该路径。 - 如果达到一个可能的最大深度(通过
getMaxDepth方法获得)而仍未找到路径,则退出循环。
- 该方法接受起点
- 深度优先搜索辅助方法
dfs:- 该方法递归地遍历图,从当前节点
current开始搜索目标节点goal。 - 如果当前节点就是目标节点,则创建一个新的
Path对象并返回。 - 如果当前深度
maxDepth为0或小于0,则返回null,表示已达到深度限制。 - 否则,遍历当前节点的所有邻居节点,并对每个邻居节点递归调用
dfs方法。 - 如果在邻居节点中找到路径,将该路径与当前节点合并(添加到路径的开头),并返回合并后的路径。
- 该方法递归地遍历图,从当前节点
- 获取最大深度的方法
getMaxDepth(可选):- 该方法使用广度优先搜索(BFS)来计算从起点到终点的最短路径长度(即最大深度)。
- 这可以帮助我们在迭代加深搜索中设置合理的深度限制,避免不必要的搜索。
- 在实践中,如果图很大或者结构复杂,这个计算可能会很耗时,因此可以省略这一步,而只是不断增加深度限制直到找到路径或确定路径不存在。
- 主方法
main:- 在
main方法中,我们创建了一个简单的图,并添加了边来连接节点。 - 然后,我们调用
iterativeDeepeningSearch方法来查找从节点A到节点D的路径。 - 最后,我们打印出找到的路径(如果存在)或未找到路径的消息
- 在
它能够在空间消耗较小的情况下找到较短的路径,并且避免了深度优先搜索可能陷入无限递归的问题(当存在环路时)。同时,通过逐渐增加深度限制,它能够在一定程度上模拟广度优先搜索的行为,最终找到从起点到终点的路径(如果存在的话)。
创作不易,感谢各位大佬的支持鼓励。
这篇关于迭代加深搜索(图的路径查找)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



