本文主要是介绍数据包转发原理与iptables的使用方法简介与实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述:
对于连接到网络上的 Linux 系统来说,防火墙是必不可少的防御机制, 它只允许合法的网络流量进出系统,而禁止其它任何网络流量。为了确定网络流量是否合法, 防火墙依靠它所包含的由网络或系统管理员预定义的一组 规则。 这些规则告诉防火墙某个流量是否合法以及对于来自某个源、至某个目的地或具有某种协议类型的网络流量要做些什么。 术语“配置防火墙”是指添加、修改和除去这些规则。稍后,我将详细讨论这些 规则。
网络流量由 IP 信息包(或,简称 信息包)— 以流的形式从源系统传输到目的地系统的一些小块数据 — 组成。 这些信息包有 头,即在每个包前面所附带的一些数据位,它们包含有关信息包的源、目的地和协议类型的信息。 防火墙根据一组规则检查这些头,以确定接受哪个信息包以及拒绝哪个信息包。我们将该过程称为 信息包过滤。
1.数据包的三种流向
当数据包到达防火墙时,如果MAC地址符合,就会由内核里相应的驱动程序接收,然后会经过一系列操 作,从而决定是发送给本地的程序,还是转发给其他机子,还是其他的什么。
1)发往本地的数据包处理流程
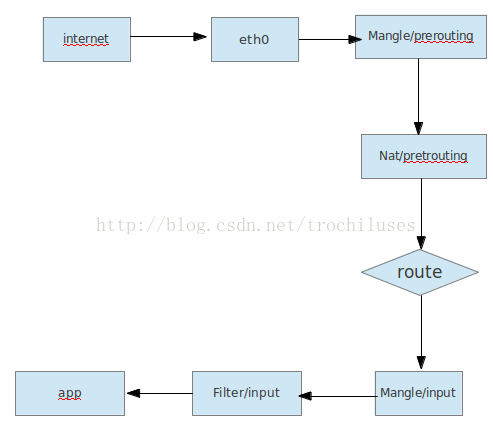
2)从本地转发的数据包处理流程
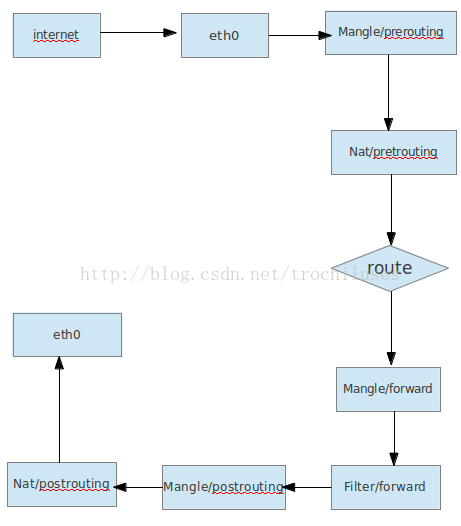
3)从本地发出的数据包处理流程
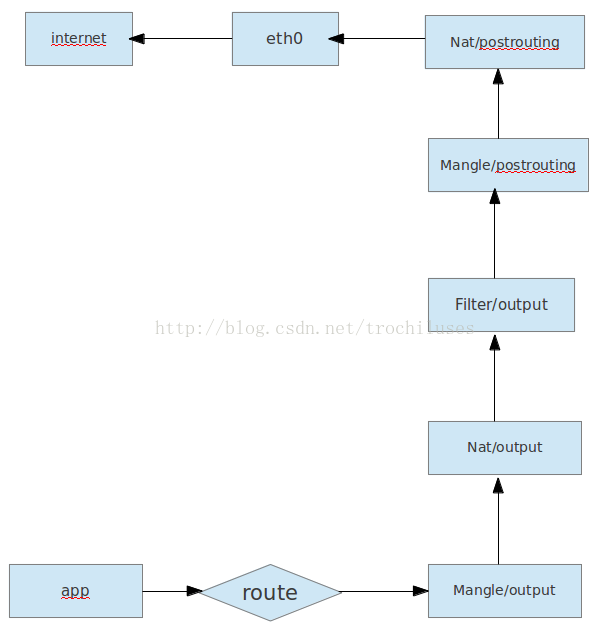
2.iptables使用详解
Iptalbes 是用来设置、维护和检查Linux内核的IP包过滤规则的。 可以定义不同的表,每个表都包含几个内部的链,也能包含用户定义的链。每个链都是一个规则列表,对对应的包进行匹配:每条规则指定应当如何处理与之相匹配的包。这被称作'target'(目标),也可以跳向同一个表内的用户定义的链。
TARGETS
防火墙的规则指定所检查包的特征,和目标。如果包不匹配,将送往该链中下一条规则检查;如果匹配,那么下一条规则由目标值确定.该目标值可以是
用户定义的链名,或是某个专用值,如ACCEPT[通过], DROP[删除],QUEUE[排队],或者 RETURN[返回]。
建立规则和链
通过向防火墙提供有关对来自某个源、到某个目的地或具有特定协议类型的信息包要做些什么的指令,规则控制信息包的过滤。 通过使用 netfilter/iptables 系统提供的特殊命令 iptables ,建立这些规则,并将其添加到内核空间的特定信息包过滤表内的链中。关于添加/除去/编辑规则的命令的一般语法如下:
$ iptables [-t table] command [match] [target]
表(table)
[-t table] 选项允许使用标准表之外的任何表。表是包含仅处理特定类型信息包的规则和链的信息包过滤表。 有三种可用的表选项: filter 、 nat 和 mangle 。该选项不是必需的,如果未指定, 则 filter 用作缺省表。
filter 表用于一般的信息包过滤,它包含 INPUT 、 OUTPUT 和 FORWARD 链。nat 表用于要转发的信息包,它包 PREROUTING 、OUTPUT 和 POSTROUTING 链。 如果信息包及其头内进行了任何更改,则使用 mangle 表。 该表包含一些规则来标记用于高级路由的信息包,该表包含 PREROUTING 和 OUTPUT 链。
注: PREROUTING 链由指定信息包一到达防火墙就改变它们的规则所组成,而 POSTROUTING 链由指定正当信息包打算离开防火墙时改变它们的规则所组成。
命令
上面这条命令中具有强制性的 command 部分是 iptables 命令的最重要部分。 它告诉 iptables 命令要做什么,例如,插入规则、将规则添加到链的末尾或删除规则。 以下是最常用的一些命令:
-A或--append: 该命令将一条规则附加到链的末尾。
示例:
该示例命令将一条规则附加到$ iptables -A INPUT -s 205.168.0.1 -j ACCEPTINPUT链的末尾,确定来自源地址 205.168.0.1 的信息包可以ACCEPT。-D或--delete: 通过用-D指定要匹配的规则或者指定规则在链中的位置编号,该命令从链中删除该规则。 下面的示例显示了这两种方法。
示例:
第一条命令从$ iptables -D INPUT --dport 80 -j DROP
$ iptables -D OUTPUT 3INPUT链删除规则,它指定DROP前往端口 80 的信息包。第二条命令只是从OUTPUT链删除编号为 3 的规则。-P或--policy: 该命令设置链的缺省目标,即策略。 所有与链中任何规则都不匹配的信息包都将被强制使用此链的策略。
示例:
该命令将$ iptables -P INPUT DROPINPUT链的缺省目标指定为DROP。这意味着,将丢弃所有与INPUT链中任何规则都不匹配的信息包。-N或--new-chain: 用命令中所指定的名称创建一个新链。
示例:$ iptables -N allowed-chain-F或--flush: 如果指定链名,该命令删除链中的所有规则, 如果未指定链名,该命令删除所有链中的所有规则。此参数用于快速清除。
示例:$ iptables -F FORWARD
$ iptables -F-L或--list: 列出指定链中的所有规则。
示例:$iptables -L allowed-chain
匹配
iptables 命令的可选 match 部分指定信息包与规则匹配所应具有的特征(如源和目的地地址、协议等)。 匹配分为两大类: 通用匹配和 特定于协议的匹配。这里,我将研究可用于采用任何协议的信息包的通用匹配。 下面是一些重要的且常用的通用匹配及其示例和说明:
-p或--protocol: 该通用协议匹配用于检查某些特定协议。 协议示例有TCP、UDP、ICMP、用逗号分隔的任何这三种协议的组合列表以及ALL(用于所有协议)。ALL是缺省匹配。可以使用!符号,它表示不与该项匹配。
示例:
在上述示例中,这两条命令都执行同一任务 — 它们指定所有$ iptables -A INPUT -p TCP, UDP
$ iptables -A INPUT -p ! ICMPTCP和UDP信息包都将与该规则匹配。 通过指定! ICMP,我们打算允许所有其它协议(在这种情况下是TCP和UDP), 而将ICMP排除在外。-s或--source: 该源匹配用于根据信息包的源 IP 地址来与它们匹配。该匹配还允许对某一范围内的 IP 地址进行匹配,可以使用!符号,表示不与该项匹配。缺省源匹配与所有 IP 地址匹配。
示例:
第二条命令指定该规则与所有来自 192.168.0.0 到 192.168.0.24 的 IP 地址范围的信息包匹配。第三条命令指定该规则将与 除来自源地址 203.16.1.89 外的任何信息包匹配。$ iptables -A OUTPUT -s 192.168.1.1
$ iptables -A OUTPUT -s 192.168.0.0/24
$ iptables -A OUTPUT -s ! 203.16.1.89-d或--destination: 该目的地匹配用于根据信息包的目的地 IP 地址来与它们匹配。 该匹配还允许对某一范围内 IP 地址进行匹配,可以使用!符号,表示不与该项匹配。
示例:$ iptables -A INPUT -d 192.168.1.1
$ iptables -A INPUT -d 192.168.0.0/24
$ iptables -A OUTPUT -d ! 203.16.1.89
目标
我们已经知道,目标是由规则指定的操作,对与那些规则匹配的信息包执行这些操作。 除了允许用户定义的目标之外,还有许多可用的目标选项。下面是常用的一些目标及其示例和说明:
ACCEPT: 当信息包与具有ACCEPT目标的规则完全匹配时,会被接受(允许它前往目的地),并且它将停止遍历链(虽然该信息包可能遍历另一个表中的其它链,并且有可能在那里被丢弃)。 该目标被指定为-j ACCEPT。DROP: 当信息包与具有DROP目标的规则完全匹配时,会阻塞该信息包,并且不对它做进一步处理。 该目标被指定为-j DROP。REJECT: 该目标的工作方式与DROP目标相同,但它比DROP好。和DROP不同,REJECT不会在服务器和客户机上留下死套接字。 另外,REJECT将错误消息发回给信息包的发送方。该目标被指定为-j REJECT。
示例:$ iptables -A FORWARD -p TCP --dport 22 -j REJECTRETURN: 在规则中设置的RETURN目标让与该规则匹配的信息包停止遍历包含该规则的链。 如果链是如INPUT之类的主链,则使用该链的缺省策略处理信息包。 它被指定为-jump RETURN。示例:$ iptables -A FORWARD -d 203.16.1.89 -jump RETURN
还有许多用于建立高级规则的其它目标,如 LOG 、 REDIRECT 、 MARK 、 MIRROR 和 MASQUERADE 等。
保存规则
现在,您已经学习了如何建立基本的规则和链以及如何从信息包过滤表中添加或删除它们。 但是,您应该记住:用上述方法所建立的规则会被保存到内核中,当重新引导系统时,会丢失这些规则。 所以,如果您将没有错误的且有效的规则集添加到信息包过滤表,同时希望在重新引导之后再次使用这些规则, 那么必须将该规则集保存在文件中。可以使用 iptables-save命令来做到这一点:
$ iptables-save > iptables-script
现在,信息包过滤表中的所有规则都被保存在文件 iptables-script 中。无论何时再次引导系统, 都可以使用 iptables-restore命令将规则集从该脚本文件恢复到信息包过滤表,如下所示:
$ iptables-restore iptables-script
如果您愿意在每次引导系统时自动恢复该规则集,则可以将上面指定的这条命令放到任何一个初始化 shell 脚本中。
3.使用实例
1)让指定协议的ip包通过相应端口:iptables -I INPUT 1 -p tcp --dport 5901 -j ACCEPT
2)屏蔽所有入站连接,但是允许主机通过ping和wget访问外网:
- # iptables -P INPUT DROP
- # iptables -P FORWARD DROP
- # iptables -P OUTPUT ACCEPT
- # iptables -A INPUT -m state --state NEW,ESTABLISHED -j ACCEPT
- # iptables -L -v -n
- #ping和wget可以正常工作
- # ping cyberciti.biz
- # wget http://www.kernel.org/pub/linux/kernel/v3.0/testing/linux-3.2-rc5.tar.bz2
state此模块,当与连接跟踪结合使用时,允许访问包的连接跟踪状态。--state state这里state是一个逗号分割的匹配连接状态列表。可能的状态是:INVALID表示包是未知连接,ESTABLISHED表示是双向传送的连接,NEW表示包为新的连接,否则是非双向传送的,而RELATED表示包由新连接开始,但是和一个已存在的连接在一起,如FTP数据传送,或者一个ICMP错误。
这里,我们需要了解一下状态机制才能很好的理解这个地方。
3)在公共网络接口屏蔽私有网络地址
我们可以从公网网络接口上删除私有IPv4网段,以防止IP欺骗。运行下面的命令,没有源路由地址的数据包会被丢弃:
注意: 192.168.0.0/24表示一个网段;2)-A表示插入这个规则到该链的末端,这样如果前面有规则匹配这个包,这条规则是没法起作用的;所以如果想让你的规则起作用,需要用-I包这个规则插入前面才行。
本文来源:谁不小心的CSDN博客 数据包转发原理与iptables的使用方法简介
外部参考:http://man.chinaunix.net/network/iptables-tutorial-cn-1.1.19.html
http://www.ibm.com/developerworks/cn/linux/network/s-netip/
这篇关于数据包转发原理与iptables的使用方法简介与实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




