本文主要是介绍动态渲染页面的爬取(理论知识),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:本文内容来自 张涛的《从零开始学Scrapy网络爬虫》
- 使用模拟浏览器运行的方式,它可以做到在浏览器中看到的是什么样,抓取的原代码就是什么样,即可见即可爬。这样,就无须关心页面是使用了JavaScrapy还是AJAX,也许关心接口的复杂度(其实连接口是什么样都不用管)。
- Python中提供了许多模拟浏览器运行的库,本章重点给大家介绍最流行的两个库Selenium和Splash。
Selenium实现动态页面爬取
- Selenium是一个用于测试Web应用程序的工具,它直接运行在浏览器,就像真正的用户操作一样。
- Selenium就像一个机器人,能模仿人使用浏览器对页面进行一系列操作,如打开浏览器、输入数据、按下按钮、下拉页面及前进后退等。支持的浏览器操作包括IE、Mozilla FireFox、Safari、Google Chrome和Opera等。
- 下面来看一下Selenium库和浏览器驱动程序的安装方法。
安装Python支持的Selenium库
- 使用pip命令安装Selenium。
pip install selenium
安装浏览器驱动程序
- 需要下载一个Selenium调用浏览器的驱动文件。我们以Chorme浏览器为例,看一下下载Chrome浏览器驱动文件的步骤。
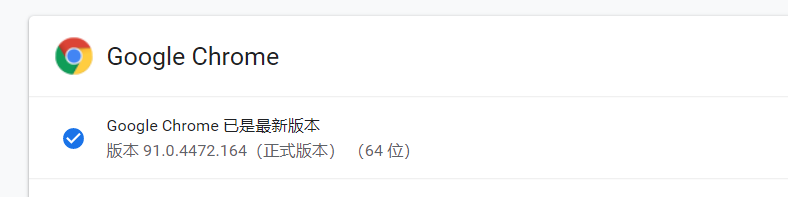
- (1)查看Chrome浏览器的版本。
- 首先要查看当前安装的Chrome浏览器的版本,以便下载与浏览器版本对应的驱动文件。
- 打开Chrome浏览器,单击菜单中的“帮助”–>“关于Google Chrome”,查看浏览器Chrome的版本号,如图所示
- (2)下载Chromedrive。
- Chromedrive的下载地址如下:

- (3)配置环境变量。
- 最后,需要将驱动文件配置到环境变量中。在Windows下,将下载的chromedriver.exe文件放到Anaconda3的Scripts目录下就可以了。
Selenium简单实现
- 下面来看一个简单的例子。使用Selenium实现在苏宁易购首页的搜索栏中输入关键字iphone,实现查询功能。苏宁易购首页地址为https://www.suning.com/。
- 实现代码如下:
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面
input = driver.find_element_by_id("searchKeywords") # 查找节点
input.clear() # 清除输入框中默认文字
input.send_keys("iphone") # 输入框中输入iphone
input.send_keys(Keys.RETURN) # 回车功能
wait = WebDriverWait(driver,10) # 设置显示等待时间为10秒
# 最多等待10秒,直到某个ID的标签被加载
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'root990')))# 获取原代码
print(driver.page_source)
- 代码运行后,Chrome浏览器被自动打开,并显示苏宁易购首页;然后在搜索栏中输入iphone,并跳转到搜索结果页面。整个过程都是自动完成,没有任何人为干预,如下图所示
- 通过控制台打印出的HTML代码可知,代码的内容正是浏览器中显示的内容。得到HTML代码,就可以从中提取出有用的信息了。
- 因此,我们可以使用Selenium来驱动浏览器加载网页,获取JavaScrapt渲染后的页面HTML代码,无须考虑网页的加载形式、接口是否加密等一系列复杂的问题。
- 下面结合爬虫的实际需求,一起来看一下Selenium的语法。
Selenium语法
- 1.声明浏览器对象
- Selenium支持很多浏览器,如Chrome、FireFox、IE、Opera和Safari等;也支持Android和BlackBerry等手机端的浏览器;还支持无界面浏览器Phantom JS。selenium.webdrive模块提供了所有浏览器的驱动(WebDriver),可以生成不同浏览器的对象。
- 以下是实现声明不同浏览器对象的代码:
from selenium import webdriver
driver = webdriver.Chrome() # 声明Chrome浏览器对象driver = webdriver.ie() # 声明IE浏览器对象driver = webdriver.firefox() # 声明FireFox浏览器对象driver = webdriver.phantomjs() # 声明Phantomjs浏览器对象driver = webdriver.safari() # 声明Safari浏览器对象
- 定义了浏览器对象driver后,就可以使用drivier来执行浏览器的各种操作了。
- 2.访问页面
- 首先想到的就是使用driver在浏览器中打看一个链接,可以使用get()方法实现:
driver.get("https://www.suning.com/")
- 程序运行后,会自动打开对应的浏览器,显示苏宁亿易购首页。get()方法会一直等,直到所有页面全部加载完(包括同步,异步加载)。
- 3.获取页面代码
- 访问页面后,就可以使用driver的page_source属性获取页面的HMTL代码了:
HTML = driver.page_source
- 获取了HTML代码后,下面就可以从页面中提取数据了。
- 4.定位元素
- 当获取到HTML代码后,就需要定位到HTML的各个元素,以便提取数据或者对该元素执行诸如输入、单击等操作。WebDriver提供了大量的方法查询页面中的节点,这些方法形如:
find_element_by_* - 以下为Selenium查找单个节点的方法。
find_element_by_id:通过ID查找;find_element_by_name:通过NAME查找;find_element_by_xpath:通过XPath选择器查找;find_element_by_link_text:通过链接的文本查找(完全匹配);
find_element_by_tag_name:通过标签名查找
find_element_by_class_name:通过CLASS查找
find_element_by_css_selector:通过CSS选择器查找。
- 例如,要想获取苏宁易购页面中的搜索框,通过Chrome浏览器的“开发者工具"观察到器对应的HTML代码,如下图所示:
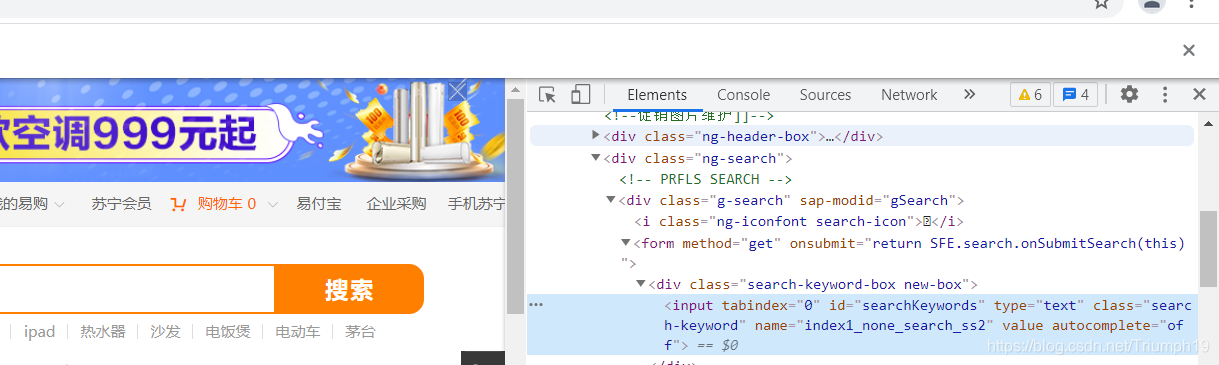
- 搜索框对应的HTML代码如下:
<input tabindex="0" id="searchKeywords" type="text" class="search-keyword" name="index1_none_search_ss2" value="" autocomplete="off">
- 这是一个input标签,包含id、class和name等属性。以下代码是实现了使用Selenium提供的5种不同方法获取input标签的功能:
from selenium import webdriver
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面# 通过id查找节点
input_id = driver.find_element_by_id("searchKeywords")# 通过name查找节点
input_name = driver.find_element_by_name("index1_none_search_ss2")# 通过class查找节点
input_class = driver.find_element_by_class_name("search-keyword")# 通过xpath查找节点
input_xpath = driver.find_element_by_xpath("//input[@id='searchKeywords']")# 通过css查找节点
input_css = driver.find_element_by_css_selector('#searchKeywords')print(input_id,input_name,input_class,input_xpath,input_css)
- 运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="fd5615078d5996a08d2b8ac5bc35391f", element="97fbbfc7-b5c2-460b-81d5-9cffa8aa8fee")>
<selenium.webdriver.remote.webelement.WebElement (session="fd5615078d5996a08d2b8ac5bc35391f", element="97fbbfc7-b5c2-460b-81d5-9cffa8aa8fee")>
<selenium.webdriver.remote.webelement.WebElement (session="fd5615078d5996a08d2b8ac5bc35391f", element="97fbbfc7-b5c2-460b-81d5-9cffa8aa8fee")>
<selenium.webdriver.remote.webelement.WebElement (session="fd5615078d5996a08d2b8ac5bc35391f", element="97fbbfc7-b5c2-460b-81d5-9cffa8aa8fee")>
<selenium.webdriver.remote.webelement.WebElement (session="fd5615078d5996a08d2b8ac5bc35391f", element="97fbbfc7-b5c2-460b-81d5-9cffa8aa8fee")>- 有结果可知,通过5中不同方法返回的结果完全一致,返回的都是WebElement类型。
- Selenium还可以一次查找多个元素,返回一个list列表。方法名是在上面方法名的基础上,将element改为elements。由于查找节点的方法较多,难以记住,Selenium还提供了两个通用方法,通过参数指定查找方式。这两个方法为find_element()和find_elements(),分别用于查找单个节点和多个节点。
- 将上面获取苏宁易购搜索框的代码改写如下:
from selenium import webdriver
from selenium.webdriver.common.by import By # 导入By类
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面input_id = driver.find_element(By.ID,"searchKeywords")input_name = driver.find_element(By.NAME,"index1_none_search_ss2")input_class = driver.find_element(By.CLASS_NAME,"search-keyword")input_xpath = driver.find_element(By.XPATH,"//input[@id='searchKeywords']")input_css = driver.find_element(By.CSS_SELECTOR,'#searchKeywords')print(input_id,input_name,input_class,input_xpath,input_css)
页面交互
- Selenium可以模拟用户对页面执行一系列操作,如输入数据、清除数据和单击按钮等。再来回顾一下Selenium是如何实现自动访问苏宁易购,在搜索栏中输入文字,回车后显示搜索结果的。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 导入Keys类
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面input = driver.find_element_by_id("searchKeywords") #查询节点
input.clear() #清除输入框中的默认文字
input.send_keys("ipone") #输入框中输入iphone
input.send_keys(Keys.RETURN) # 回车功能
- 首先导入Keys类,Keys类提供键盘按键的支持,比如RETURN、F1和ALT等。代码中使用clear()方法实现输入框数据的清除;使用send_keys()方法实现文字的输入,Keys.RETURN为回车键,实现回车功能。如果想实现按钮单击功能,可以使用click()方法。
执行JavaScript
- Selenium并未提供所有的页面交互操作方法,例如爬虫中用得最多的下拉页面(用于加载更多内容)。不过Selenium提供了execute_script()方法,用于执行JS,这样我们就可以通过JS代码实现这些操作了。
- 以下代码实现了将苏宁易购的页面向下滚动到底部的功能:
from selenium import webdriver
import time
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面
time.sleep(5) #等待5秒钟# 将进度条下拉到页面底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
- 首先,导入time模块,调用time.sleep(5)方法等待5秒钟,等待AJAX请求数据加载完;然后,调用driver的execute_script()方法执行一段JS代码。JS代码的功能是向下滚动到页面底部。window.scrollTo()实现将页面滚动到任意位置,其两个参数分别设置页面在x轴和y轴坐标的位置,document.body.scrollHeight获取整个页面的高度。
- 运行程序后,Chrome浏览器被自动打开,显示苏宁易购页面。几秒钟后页面自动滚动到底部,这时页面就会加载更多的内容。
- 对爬虫来说,这种自动滚动,加载更多内容的功能具有重要意义。因为我们可以重复执行这个功能,这样就能爬取到更多信息了。
等待页面加载完成
- 现在大多数的Web应用的是AJAX技术。当一个页面被加载到浏览器中时,该页面内的元素可以在不同的时间点被加载,这使得定位元素变得困难。在使用Selenium定位元素时,如果元素还未加载,则会抛出ElementNotVisibleException异常。这时候,就需要等待一段时间,直到元素加载完成。
- Selenium中超时和等待有关的方法主要有以下3个:
- (1)等待超时。
- 有些时候,由于网络环境或网络自身的原因,使用get()方法加载页面时非常耗时,这时程序就会一直等待,严重影响了程序执行效率。
- driver的set_page_load_timeout()方法用于设置页面完全加载的超时时间。如果加载时长超过这个时间,则会继续往下执行(一般会提示出错)。
from selenium import webdriver #导入浏览器驱动模块
from selenium.common.exceptions import TimeoutException #导入异常模块
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.set_page_load_timeout(5) # 设置页面加载的超时时间
try:driver.get("https://www.suning.com/") # 请求页面# 将进度条下拉到页面底部driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')print(driver.page_source)
except TimeoutException:print("time out")
driver.quit() #退出当前驱动并关闭所有关联窗口
- 首先,导入浏览器驱动模块和异常模块;然后,通过driver的set_page_load_timeout()方法设置超时时间为5秒后页面还未完全加载,使用try…except抛出Timeout Exception异常,打印time out信息;最后,调用driver的quit()方法退出当前驱动并关闭所有关联窗口。
- 除了设置超时,Selenium还提供了两种等待方法,分别为隐式等待和显式等待。
- (2)隐式等待
- 隐式等待的方法implicitly_wait(),用于设定一个数据加载的最长等待时间。
from selenium import webdriver #导入浏览器驱动模块
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.implicitly_wait(15)
driver.get("https://www.suning.com/") # 请求页面
print(driver.page_source)
- 代码中使用driver.implictly_wait(15)设定最长等待时间为15秒,如果在规定时间内网页全部加载完成(包括所有JavaScript和AJAX请求数据)就立即执行下一步。隐式等待在driver周期都起作用,所以只要设置一次即可。
- 这种方式虽好,但是效率还有待提升。因为页面想要的元素如果早就加载完,但因为个别JS之类的执行特别慢,仍然需要等到全部完成才能执行下一步。
- (3)显示等待。
- Selenium提供了的显示等待就解决了隐式等待的问题。显示等待也设定了一个最长等待时间,但它关心某个元素是否已经加载,如果加载则立即往下执行,如果超时则报错。显式等待使用Selenium的WebDriverWait类,配合该类的unit()方法,就能根据判断条件而进行灵活地等待了。
from selenium import webdriver #导入浏览器驱动模块
from selenium.webdriver.common.by import By #导入定位方式模块
from selenium.webdriver.support.ui import WebDriverWait #导入等待模块
from selenium.webdriver.support import expected_conditions as EC # 导入异常模块
driver = webdriver.Chrome() # 声明Chrome浏览器对象
driver.get("https://www.suning.com/") # 请求页面
try:# 生成WebDriverWait对象,指定最长时间input = WebDriverWait(driver,10).until(# 设定预期条件EC.presence_of_element_located((By.ID,"searchKeywords")))print(input)
except TimeoutException:# 因超时抛出异常print("time out!")
finally:driver.quit() # 退出
- 首先,导入了5个模块,WebDriverWait为等待类,用于设置显式等待;excepted_conditions为预期条件类,用于设置显式等待的条件;TimeoutException为超时异常类,用于异常时的处理。
- 然后,生成了WebDriverWait对象,指定最长等待时间为10秒。再调用它的until()方法,传入一个等待预期的条件类expected_conditionds(别名为EC),这里传入了条件presence_of_element_located,表示节点出现,其参数是节点的定位元组,即ID为search Keywords的搜索框。这样做的效果是,程序会每隔500毫秒检测一下条件,如果条件成立了(搜索框被加载进来了,即使页面为全部加载完),则返回该节点,执行下一步,否则继续等待,直到超过设置的最长时间10秒,然后抛出TimeoutException异常。
这篇关于动态渲染页面的爬取(理论知识)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






