本文主要是介绍提取出图像的感兴趣区域,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是我们的原图像

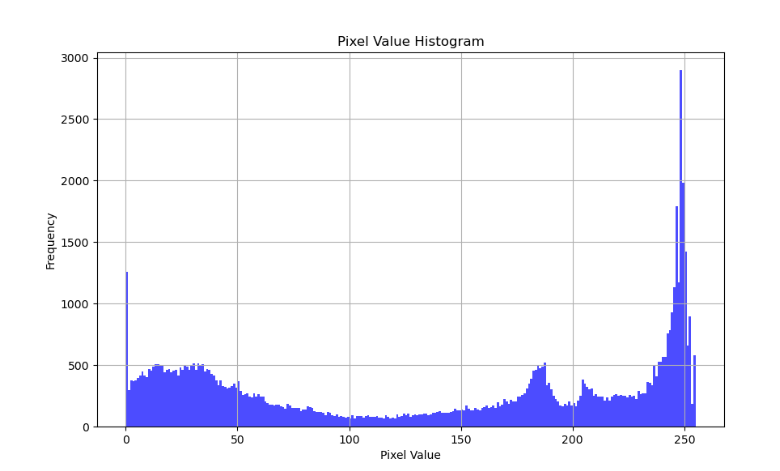
将图像的数值统计后进行条形图展示
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np# 图像路径
image_path = r"D:\My Data\Figure\OIP.jpg"# 打开图像
image = Image.open(image_path)# 将图像转换为numpy数组
image_array = np.array(image)# 统计像素值
pixel_values = image_array.flatten()# 绘制条形图
plt.figure(figsize=(10, 6))
plt.hist(pixel_values, bins=range(256), color='blue', alpha=0.7)
plt.title('Pixel Value Histogram')
plt.xlabel('Pixel Value')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
我们使用3Dslice标注了一张图像,进行展示
我们将标注好的标签保存为了.tif格式,进行可视化后为
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image# 图像路径
image_path = r"D:\My Data\TempWritelabel\Segmentation-Segment_1-label_1.tif"# 打开图像
image = Image.open(image_path)# 将图像转换为numpy数组
image_array = np.array(image)# 可视化图像
plt.imshow(image_array, cmap='gray')
plt.axis('off') # 关闭坐标轴
plt.show()

使用图像数值统计代码进行数值统计标注的图像数值
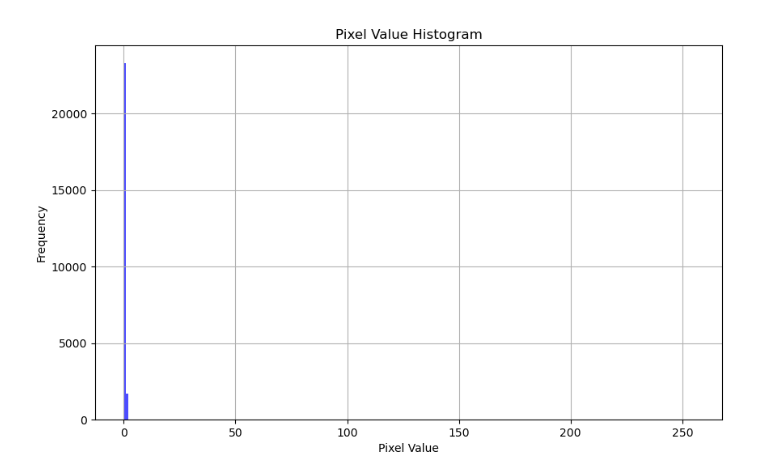 可见我们标注图像的数值只有0和1,前景为1,背景为0.
可见我们标注图像的数值只有0和1,前景为1,背景为0.
这时候,我们将原始图像×标签图像,就是标注图像的区域,那么就在原始图像上提取出标注图像的位置。
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np# 原始图像路径
original_image_path = r"D:\My Data\Figure\OIP.jpg"
# 标注图像路径
label_image_path = r"D:\My Data\TempWritelabel\Segmentation-Segment_1-label_1.tif"# 打开原始图像和标注图像
original_image = Image.open(original_image_path)
label_image = Image.open(label_image_path)# 将图像转换为numpy数组
original_image_array = np.array(original_image)
label_image_array = np.array(label_image)# 如果原始图像是三通道,复制标签图像到三通道
if original_image_array.shape[-1] == 3:label_image_array = np.repeat(label_image_array[:, :, np.newaxis], 3, axis=2)# 将原始图像和标注图像的像素值进行相乘
new_image_array = original_image_array * label_image_array# 将新图像转换为PIL图像对象
new_image = Image.fromarray(new_image_array.astype('uint8'))# 可视化新图像
plt.imshow(new_image)
plt.axis('off')
plt.title('New Image')
plt.show()

这时候我们如果运用上一篇博文的代码,去除周围的0像素,那么处理后的图像

感觉左边的0像素没有完全去除掉,还可以再去除一些。仔细观察发现,应该是标注的时候有一个点标注为了1。可能是这个噪声点导致的

我们将这张只有感兴趣的图像,用来深度学习,就会大大减少遭受的干扰,从而更好的收敛。
这篇关于提取出图像的感兴趣区域的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






