本文主要是介绍深度学习500问——Chapter08:目标检测(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
8.2.4 R-FCN
8.2.5 FPN
8.2.6 Mask R-CNN
8.2.4 R-FCN
R-FCN 有哪些创新点
R-FCN仍然属于two-stage目标检测算法:RPN + R-FCN
- Fully convolutional
- 位置敏感得分图(position-sentive score maps)
our region-based detector is fully convolutional with almost all computation shared on the entire image. To achieve this goal, we propose position-sensitive score maps to address a dilemma between translation-invariance in image classification and translation-variance in object detection.
R-FCN backbone:ResNet
ResNet-101 + R-FCN:83.6% in PASCAL VOC 2007 test datasets
既提高了mAP,又加快了检测速度。
假设我们只有一个特征图用来检测右眼。那么我们可以使用它定位人脸吗?应该可以。因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。现在我们回顾一下所有问题。在Faster R-CNN中,检测器使用了多个全连接层进行预测。如果有2000个ROI,那么成本非常高。R-FCN通过减少每个ROI所需的工作量实现加速。上面基于区域的特征图与ROI是独立的,可以在每个ROI之外单独计算。剩下的工作就比较简单了,因此R-FCN的速度比Faster R-CNN快。
人脸检测
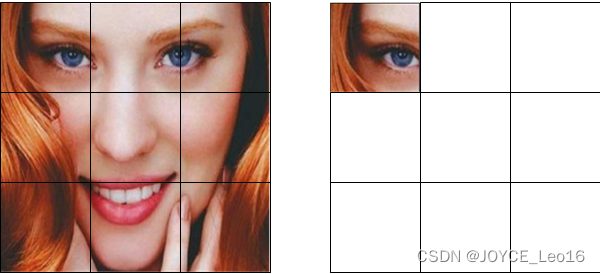
现在我们来看一下5×5的特征图M,内部包含一个蓝色方块。我们将方块平均分成3×3个区域。现在,我们在M中创建了一个新的特征图,来检测方块的左上角(TL)。这个新的特征图如下图(右)所示。只有黄色的网格单元[2,2]处于激活状态。在左侧创建一个新的特征图,用于检测目标的左上角。

检测示例
我们将方块分成9个部分,由此创建了9个特征图,每个用来检测对应的目标区域。这些特征图叫做位置敏感得分图(position-sensitive score map),因为每个图检测目标的子区域(计算其得分)。
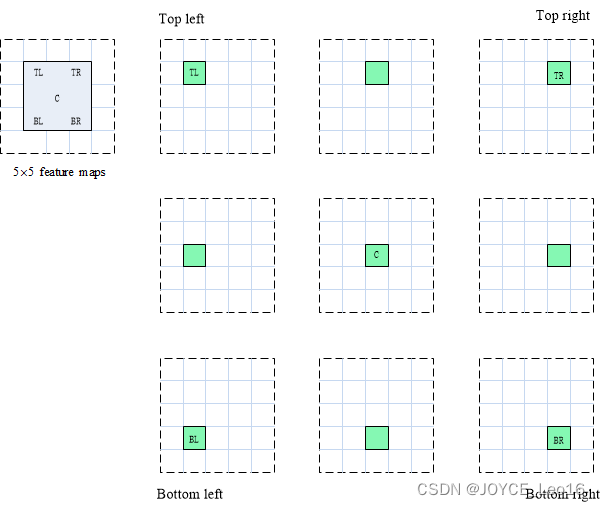
生成9个得分图
下图中红色虚线矩形是建议的ROI。我们将其分割成3×3个区域,并询问每个区域包含目标对应部分的概率是多少。例如,左上角ROI区域包含左眼的概率。我们将结果存储成3×3 vote数组,如下图(右)所示。例如,vote_array[0][0]包含左上角区域是否包含目标对应部分的得分。
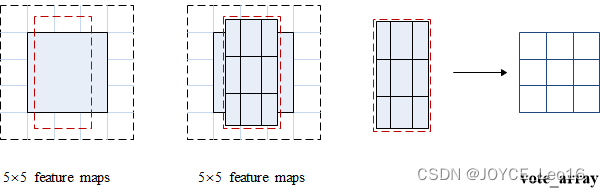
将ROI应用到特征图上,输出一个3x3数组。将得分图和ROI映射到vote数组的过程叫做位置敏感ROI池化(position-sensitive ROI-pool)。该过程与前面讨论过的ROI池化非常接近。
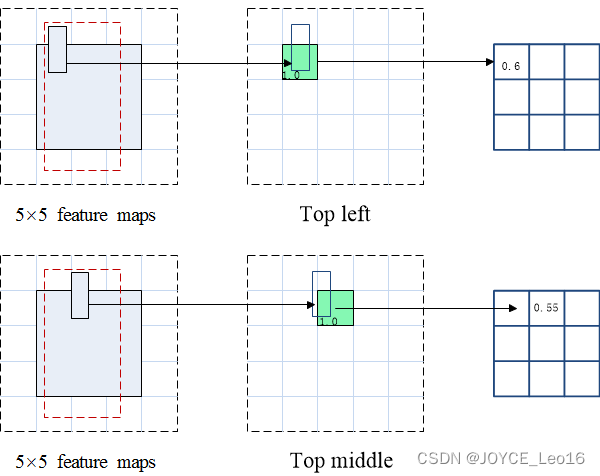
将ROI的一部分叠加到对应的得分图上,计算V[i][j]。在计算出位置敏感ROI池化的所有值后,类别得分是其所有元素得分的平均值。
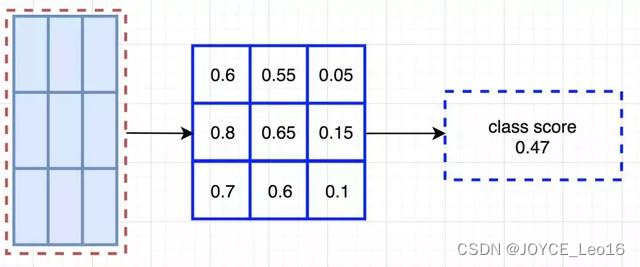
ROI池化
假如我们有C个类别要检测。我们将其扩展为C+1个类别,这样就为背景(非目标)增加了一个新的类别。每个类别有3×3个得分图,因此一共有(C+1)×3×3个得分图。使用每个类别的得分图可以预测出该类别的类别得分。然后我们对这些得分应用 softmax 函数,计算出每个类别的概率。以下是数据流图,在本案例中,k=3。
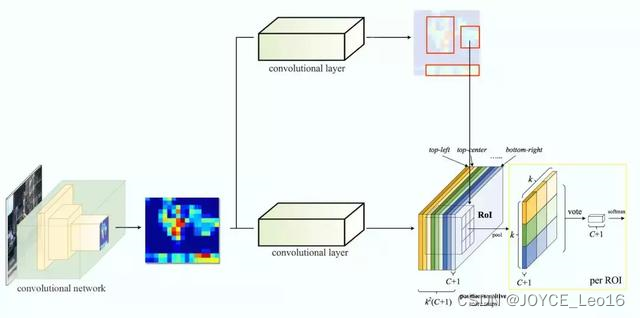
8.2.5 FPN
FPN有哪些创新点
- 多层特征
- 特征融合
解决目标检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升小物体(small object)检测的性能。
在物体检测里面,有限计算量情况下,网络的深度(对应到感受野)与stride通常是一对矛盾的东西,常用的网络结构对应的stride一般会比较大(如32),而图像中的小物体甚至会小于stride的大小,造成的结果就是小物体的检测性能急剧下降。传统解决这个问题的思路包括:
- 图像金字塔(image pyramid),即多尺度训练和测试。但该方法计算量大,耗时较久。
- 特征分层,即每层分别预测对应的scale分辨率的检测结果,如SSD算法。该方法强行让不同层学习同样的语义信息,但实际上不同深度对应不同层次的语义特征,浅层网络分辨率高,学到更多是细节特征,深层网络分辨率低,学到更多是语义特征。
因而,目前多尺度的物体检测主要面临的挑战为:
- 如何学习具有强语义信息的多尺度特征?
- 如果设计通用的特征表示来解决物体检测中的多个子问题?如object proposal,box localization,instance segmentation。
- 如何高效计算多尺度的特征表示?
FPN网络直接在Faster R-CNN单网络上做修改,每个分辨率的feature map 引入后——分辨率缩放两倍的feature map做element-wise相加的操作。通过这样的连接,每一层预测所用的feature map都融合了不同分辨率、不同语义强度的特征,融合不同分辨率的feature map分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义(rich semantic)特征。同时,,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。
作者接下来实验了将FPN应用在Faster RCNN上的性能,在COCO上达到了state-of-the-art的单模型精度。在RPN上,FPN增加了8.0个点的平均召回率(average recall,AR);在后面的目标检测上,对于COCO数据集,FPN增加了2.3个点的平均精确率(average precision,AP),对于VOC数据集,FPN增加了3.8个点的AP。
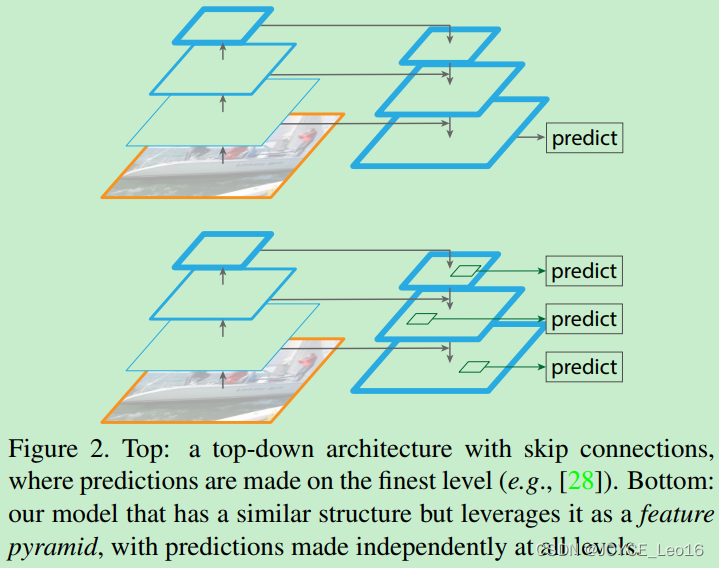
FPN算法主要由三个模块组成,分别是:
- Bottom-up pathway(自底向上线路)
- Lareral connections(横向连接)
- Top-down path(自顶向下线路)
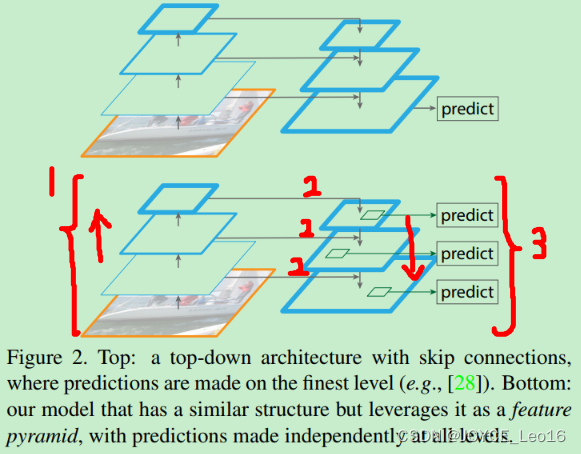
1、Bottom-up pathway(自底向上线路)
FPN是基于Faster R-CNN进行改进,其backbone是ResNet-101,FPN主要应用在Faster R-CNN中的RPN(用于bouding box proposal generation)和Faster R-CNN(用于object detection)两个模块中。
其中RPN和Faster R-CNN分别关注的是召回率(recall)和精确率(precision),在这里对比的指标分别为Average Recall(AR)和Average Precision(AP)。
注:Bottom-up可以理解为自底向上,Top-down可以理解为自顶向下。这里的下指的是low-level。上是指high-level,分别对应于提取的低级(浅层)特征和高级语义(高层)特征。
Bottom-up pathway是卷积网络的前向传播过程。在前向传播过程中,feature map的大小可以在某些层发生改变。一些尺度(scale)因子为2,所以后一层feature map的大小是前一层feature map大小是二分之一,根据此关系进而构成了feature pyramid(hierarchy)。
然而还有很多层输出的feature map是一样的大小(即不进行缩放的卷积),作者将这些层归为同一stage。对于feature pyramid,作者为每个stage定义一个pyramid level。
作者将每个stage的最后一层的输出作为feature map,然后在不同stage进行同一操作,便构成了feature pyramid。
具体来说,对于ResNet-101,作者使用了每个stage的最后一个残差结构的特征激活输出。将这些残差模块输出表示为 {C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有 {4,8,16,32}像素的步长.考虑到内存占用,没有将conv1包含在金字塔中。
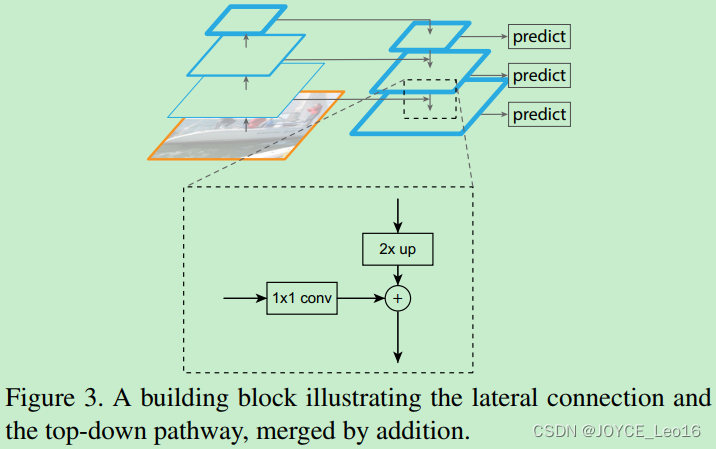
2、Top-down pathway and lateral connections
Top-down pathway是上采样(upsampling)过程,而later connection(横向连接)是将上采样的结果和bottom-up pathway生成的相同大小的feature map进行融合(merge)。
注:上采样尺度因子为2,因为为了和之前下采样卷积的尺度因子等于2一样。上采样是放大,下采样是缩小。
具体操作如下图所示,上采样(2x up)feature map与相同大小的bottom-up feature map进行逐像素相加融合(element-wise addition),其中bottom-up feature先要经过1x1卷积层,目的是为了减少通道维度(reduce channel dimensions)。
注:减少通道维度是为了bottom-up feature map的通道数量与top-down feature map的通道数量保持一致,又因为两者feature map大小一致,所以可以进行对应位置像素的叠加(element-wise addition)。
8.2.6 Mask R-CNN
Mask R-CNN有哪些创新点
- Backbone:ResNeXt-101 + FPN
- RoI Align替换RoI Pooling
Mask R-CNN 是一个实例分割(Instance segmentation)算法,主要是在目标检测的基础上再进行分割。Mask R-CNN算法主要是Faster R-CNN + FCN,更具体一点就是ResNeXt + RPN + RoI Align + Fast R-CNN + FCN。
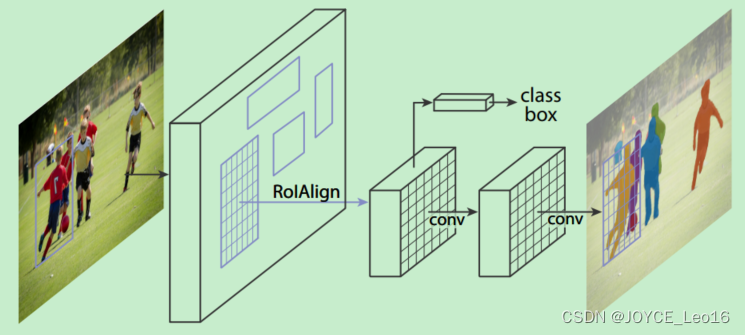
Mask R-CNN 算法步骤:
- 输入一幅你想要处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 对这个feature map中的每一个点设定预定的RoI。从而获得多个候选RoI;
- 将这些候选的RoI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的RoI;
- 对这些剩下的RoI进行RoI Align操作(即先将原图和feature map和pixel对应起来,然后将feature map和固定的feature对应起来);
- 对这些RoI进行分类(N类别分类)、BB回归和MASK生成(在每一个RoI里面进行FCB操作)。
RoI Pooling 和 RoI Align有哪些不同
RoI Align 是在MASK-RCNN中提出的一种区域特征聚集方式,很好地解决了RoI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。实验显示,在检测任务中将RoI Pooling替换为RoI Align可以提升检测模型的准确性。
在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,RoI Pooling的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故RoI Pooling这一操作存在两次量化的过程。
- 将候选框边界量化为整数点坐标值。
- 将量化后的边界区域平均分割成
个单元(bin),对每一个单元的边界进行量化。
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里。作者把它总结为“不匹配问题(misalignment)”。
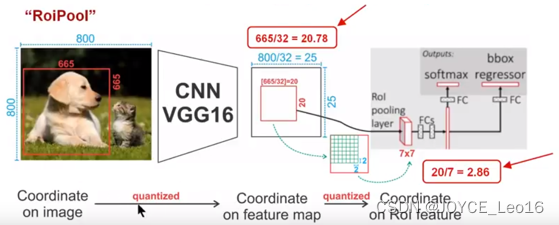
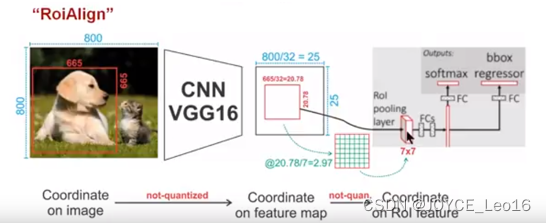
下面我们用直观的例子具体分析一下上述区域不匹配问题。如下图所示,这是一个Faster-RCNN检测框架。
输入一张的图片,图片上有一个
的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是RoI Pooling直接将它量化为20。
接下来需要把框内的特征池化的大小,因此将上述包围框平均分割成
个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是RoI Pooling再次把它量化为2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
为了解决RoI Pooling的上述缺点,作者提出了RoI Align这一改进的方法,如下图。
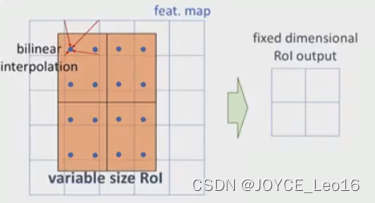
RoI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,RoI Align并不能简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如下图所示:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。
在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,RoI Align 在遍历取样点的数量上没有RoI Pooling那么多,但却可以获得更好的性能,这主要归功于解决了mis alignment的问题。
值得一提的是,在实验时发现,RoI Align在VOC 2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受mis alignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
这篇关于深度学习500问——Chapter08:目标检测(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





