本文主要是介绍多因子模型的因子分组-克隆巴赫α系数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
优质博文:IT-BLOG-CN
在建立我们的Alpha模型之前,我们得先知道什么是Alpha?Alpha是一条或者一系列能够预测股票走势的信息资讯组合。而这每一条非随机的信息资讯,我们称之为多因子模型的因子。多因子模型因子的选择需要避免系统性风险模型(例如中国的上证综指,美国的S&P500等等)中的因子,或者是不系统性风险模型中因子有高相关度的因子,而选取不同的因子组别中的因子,使我们的模型更加稳定。因为多因子模型中的各因子决定了你的投资风格,而相对固定的投资风格是评判你多因子模型的稳定性以及好坏的标准之一,所以因子分组对于我们多因子模型来说非常重要。通常我们有三种分组方式,我们今天先介绍第一种方法----免隆巳赫α系数Cronbach’s Alpha。
克隆巴赫α系数是经常用到的一个信度指标,它指的是某一个维度内,不同题项间的一致程度。系数的计算主要有以下两个方法:
(1)
其中, 是每个因子方差的总和,
是每个因子方差的总和,  是所有因子总和的方差,
是所有因子总和的方差,m为因子个数。
(2)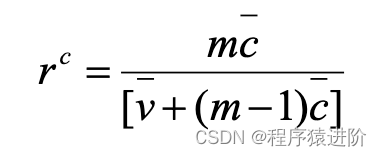
其中,  是因子间方差的平均值,
是因子间方差的平均值,  是因子方差的平均值,
是因子方差的平均值,m为因子的个数。
当计算得到的克隆巴赫α系数低于0.7时,我们认为这一组因子内部的一致性较低,说明这组因子里有多于1个因子并不属于这个因子分组。通过这一方法,我们能够确定我们的多因子模型到底有多少组不同的因子,并且确定每一组里的因子有哪些。
在知道克隆巴赫α系数的计算之后,我们通常通过以下步骤来对因子进行分组:计算因子总体的克隆巴赫α系数,假如结果低于0.7,那么分别移除组里的1个因子,并分别计算剩余因子的克隆巴赫α系数并移除克隆巴赫α系数数值提升最大的那个因子。
假如移除后的克隆巴赫α系数数值仍然低于0.7,重复步骤1。
当你计算得到第一个大于等于0.7的克隆巴赫α系数,那么所测试的因子为一个组。
将所有被移除的因子形成一个总体并计算克隆巴赫α系数,然后重复步骤1~3。
不断地形成新的因子分组,直到所有因子都被完全分类。
通常我们借助SPSS软件的Reliability Analysis功能来计算克隆巴赫α系数并对因子进行分组。
克隆巴赫α系数的优点比较明显:公式简单易懂,计算简单方便,相关概念和计算步骤容易理解等,因此该方法在很多领域都被使用,但是克隆巴赫α系数也存在它的局限性:当被分组的因子个数较少的时候,克隆巴赫α系数的方法就缺少可信度,而且当组内因子个数较少时,其分组可信度也较低。
这篇关于多因子模型的因子分组-克隆巴赫α系数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







