本文主要是介绍通用大模型研究重点之五:llama family,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLAMA Family
decoder-only类型
LLaMA(Large Language Model AI)在4月18日公布旗下最大模型LLAMA3,参数高达4000亿。目前meta已经开源了80亿和700亿版本模型,主要升级是多模态、长文本方面工作。
模型特点:采用标准的decoder-only,tokennizer的分词表128k,24K的GPU集群,15T的公开数据,非英占5%,包括30种语言。训练数据增加7倍,代码量增加2倍。
个人理解:按照Sacling low的研究,当参数一定条件下,增加数据量可以明显提示模型的表达能力。并且研究发展在一定条件下增加数据比增加参数在知识表示方面效果更加显著。当然在Scaling low研究中openai和google的观点从文献上看是对立的,这种对立统一或者帮助我们在设计模型时给出一个指导,数据不足可以通过参加参数提升效果,数据充足情况下可以通过模型学习SFT,LORA、MOE三种学习范式提升效果。
LLaMA模型3:
- 优点:
- 最先进的性能:模型3通常是系列中最大规模的模型,提供了最先进的性能,尤其是在复杂的语言任务上。
- 强大的泛化能力:大量的参数使得模型3在多种任务上都有出色的泛化能力。
- 更好的多任务学习:由于其规模和设计,模型3适合于多任务学习场景,可以同时处理多种不同的自然语言处理任务。
- 缺点:
- 高资源消耗:最大的模型规模意味着最高的计算和存储需求,这可能使得在没有高性能计算资源的情况下难以部署。
- 环境影响:训练和运行如此大规模的模型可能对环境产生较大的影响,因为需要大量的电力和计算资源。
通用异同点:
- 架构改进:随着版本的提升,LLaMA模型通常会采用更先进的架构设计,以提高效率和性能。
- 任务适应性:所有版本的LLaMA模型都旨在处理多种自然语言处理任务,如文本分类、问答、文本生成等。
- 资源效率:尽管规模不同,但LLaMA系列模型的一个共同目标是提高资源效率,即在尽可能少的资源消耗下提供高性能。
LLaMA模型2:
- 优点:
- 提升的性能:相比于模型1,模型2通常具有更多的参数和更大的规模,这使得它在更广泛的任务上表现更好。
- 更好的上下文理解:增加的参数和改进的架构有助于模型更好地理解和处理长文本。
- 缺点:
- 增加的资源需求:相比于模型1,模型2需要更多的计算资源,这可能限制了它在资源受限的环境中的可用性。
- 可能的过拟合风险:更大的模型规模如果没有适当的正则化,可能在小数据集上出现过拟合。
LLaMA模型1:
- 优点:
- 较小的规模:相比于其他大型语言模型,LLaMA模型1具有较小的模型尺寸,这使得它在资源有限的环境中更容易部署。
- 高效的性能:尽管规模较小,但LLaMA模型1在多种自然语言处理任务上展现出了高效的性能。
- 缺点:
- 有限的上下文理解:由于模型规模的限制,模型1可能在处理非常长文本或需要深层次推理的任务时表现不佳。
- 较少的参数:较少的参数可能导致模型在一些复杂的任务上泛化能力不足。
请注意,具体的技术细节、性能指标和应用场景可能会随着模型版本的更新而变化。此外,对于每个版本的详细优缺点,通常需要通过实际的基准测试和使用体验来确定。如果需要最新和最详细的信息,建议查阅官方发布的技术文档或相关的研究论文。
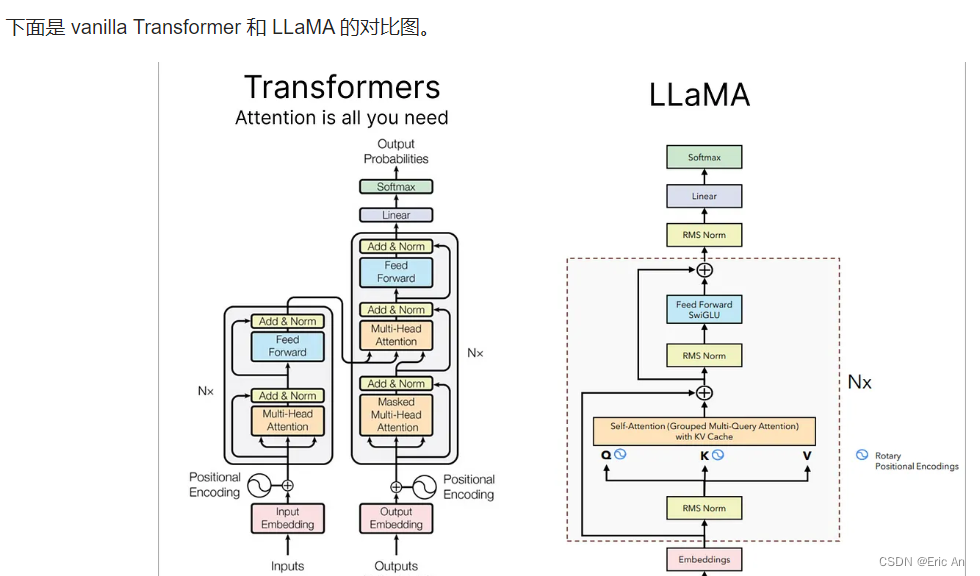
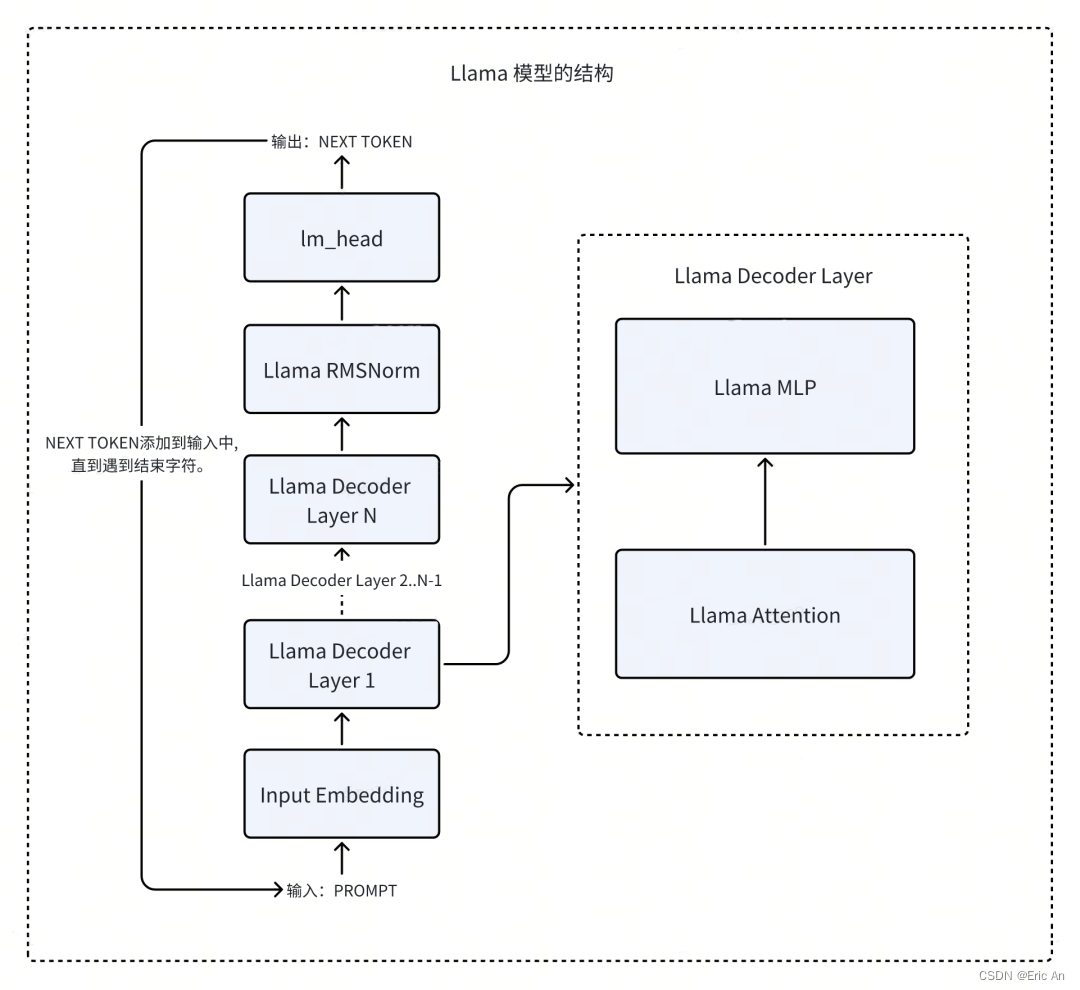
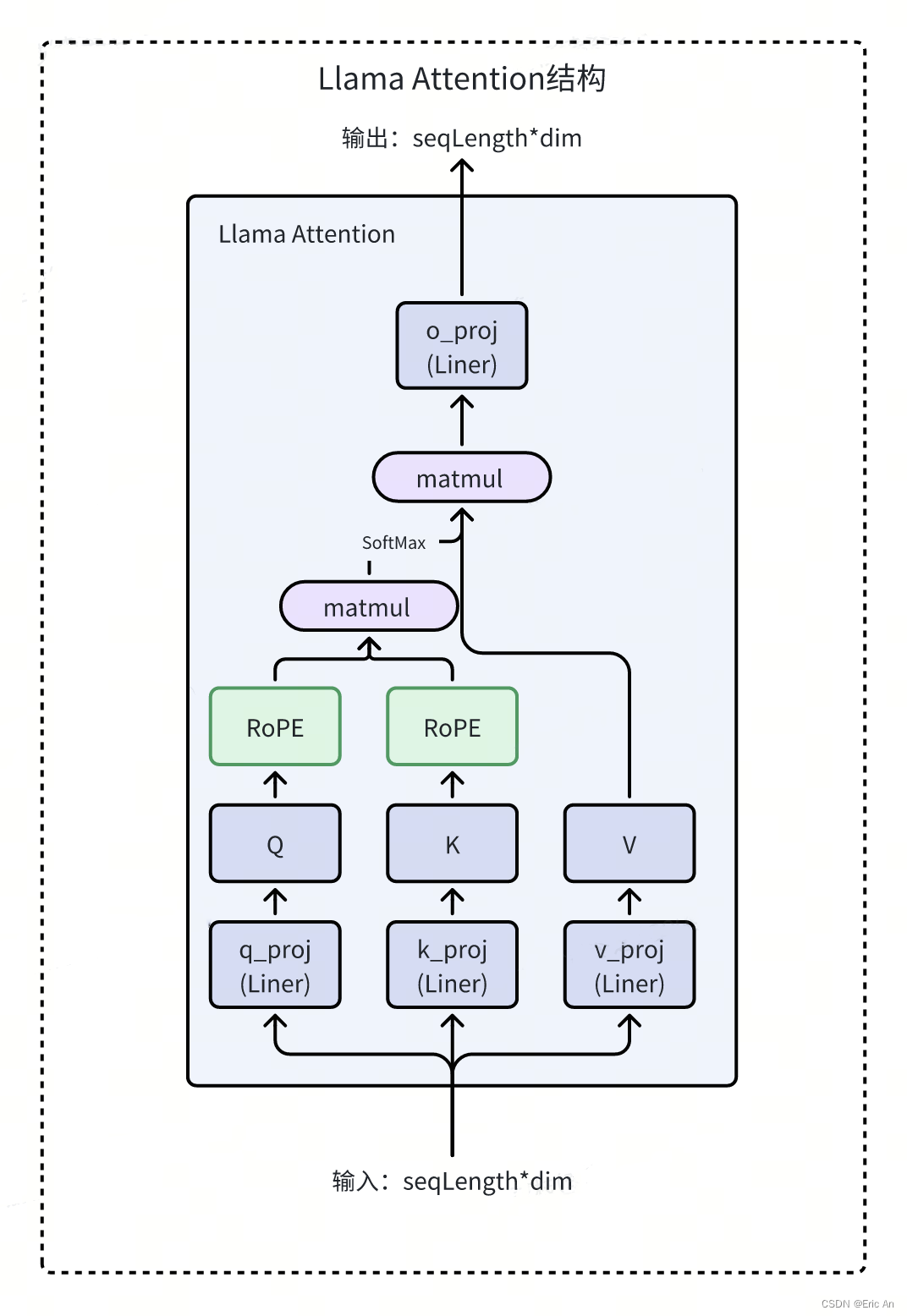
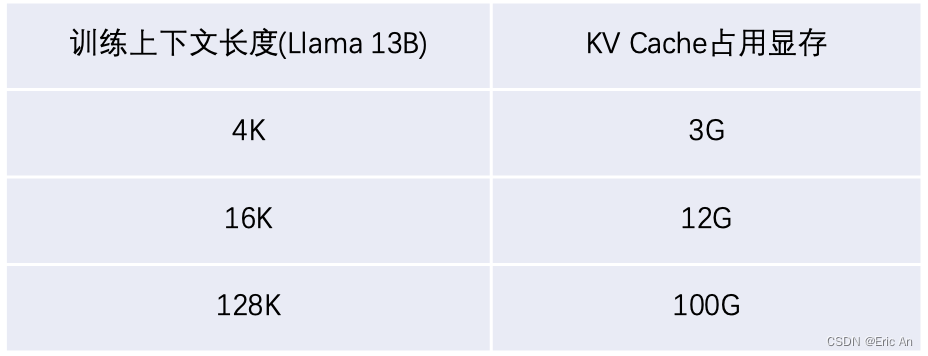
其他国际知名大模型
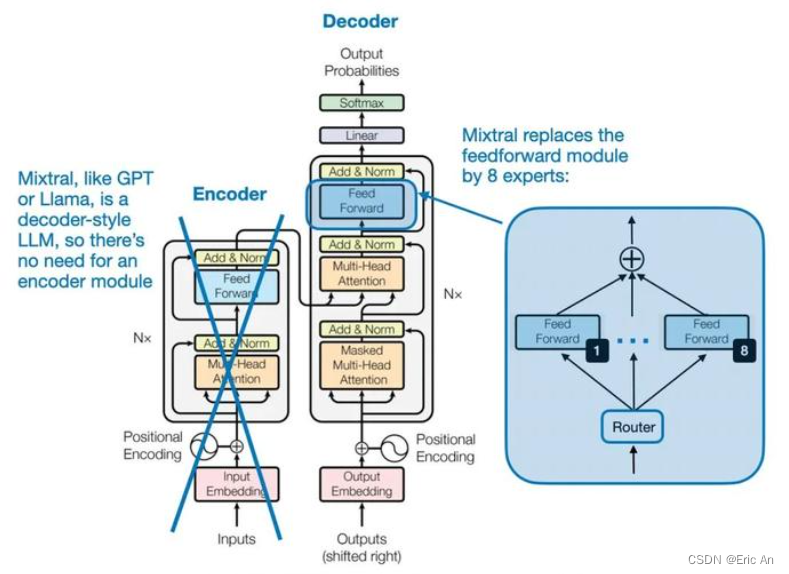
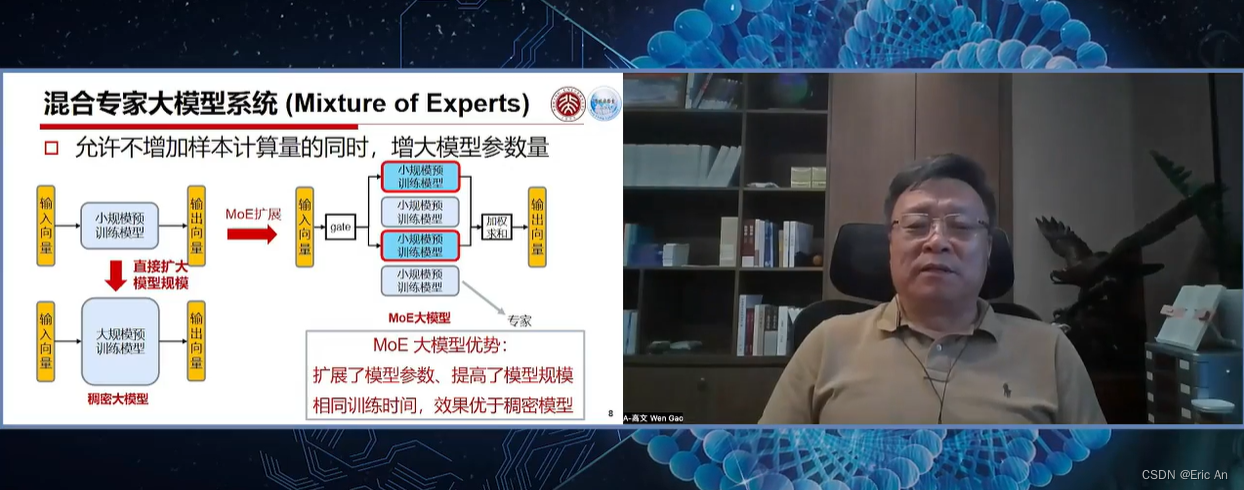



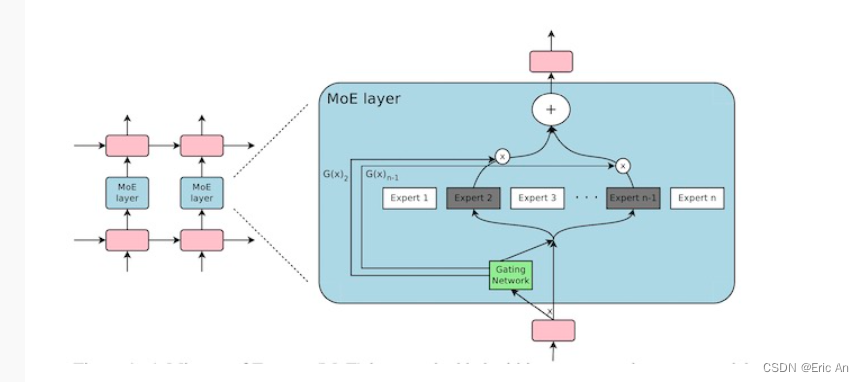
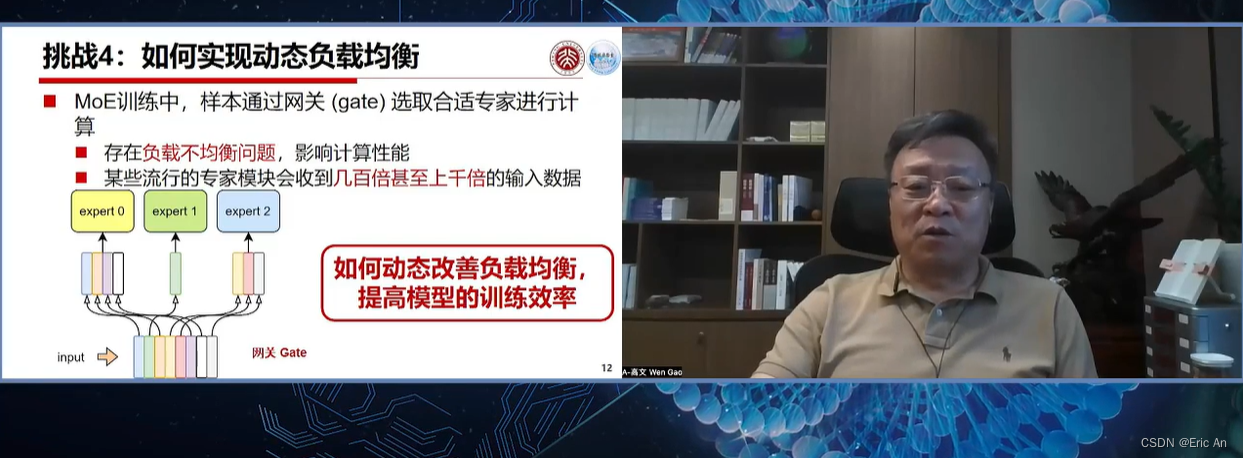
也有将MoE作为一个独立的层[2],将多个MoE结构堆叠在另一个网络中,一个MoE层的输出作为下一层MoE层的输入,其输出作为另一个下一层的输入,其具体过程如下图所示:
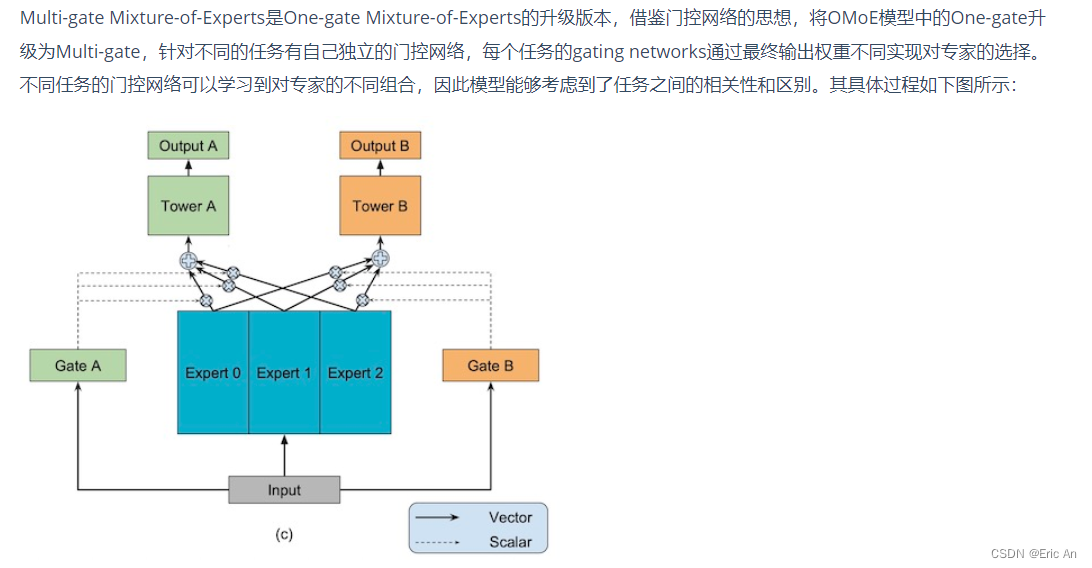
MoE代码实现
MoE,即Mixture of Experts它允许模型在不同的任务和数据集上进行训练和微调。MoE结构是一种将多个专家网络结合起来,以便处理各种输入的技术。每个专家网络可以专门处理一种类型的任务或数据,而主网络则负责将输入分配给最合适的专家网络。MoE结构的代码简化的MoE结构的概念性伪代码示例原理:```python
import torch
import torch.nn as nnclass Expert(nn.Module):def __init__(self, size):super(Expert, self).__init__()self.fc = nn.Linear(size, size)def forward(self, x):return self.fc(x)class MixtureOfExperts(nn.Module):def __init__(self, size, num_experts, top_k_experts):super(MixtureOfExperts, self).__init__()self.experts = nn.ModuleList(Expert(size) for _ in range(num_experts))self.top_k_experts = top_k_expertsdef forward(self, x):# 假设x是我们的输入,我们将其分发到不同的专家expert_outputs = [expert(x) for expert in self.experts]# 选择top-k专家的输出top_k_indices = torch.topk(expert_outputs, self.top_k_experts, dim=0)[1]# 将选择的专家输出合并起来selected_expert_outputs = [torch.index_select(expert_output, 0, top_k_indices) for expert_output, expert in zip(expert_outputs, self.experts)]# 将所有选定的专家输出相加combined_output = torch.stack(selected_expert_outputs).sum(0)return combined_output# 假设我们的输入大小为256,我们有5个专家,并且我们选择top-2专家
model = MixtureOfExperts(256, 5, 2)# 假设输入数据batch的大小为32
input_data = torch.randn(32, 256)# 前向传播
output_data = model(input_data)
Grok
MoE类型
Mistral
MoE类型
Gemma
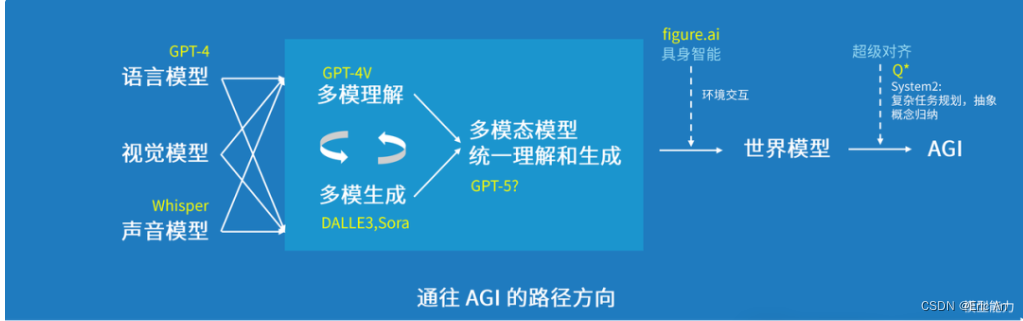
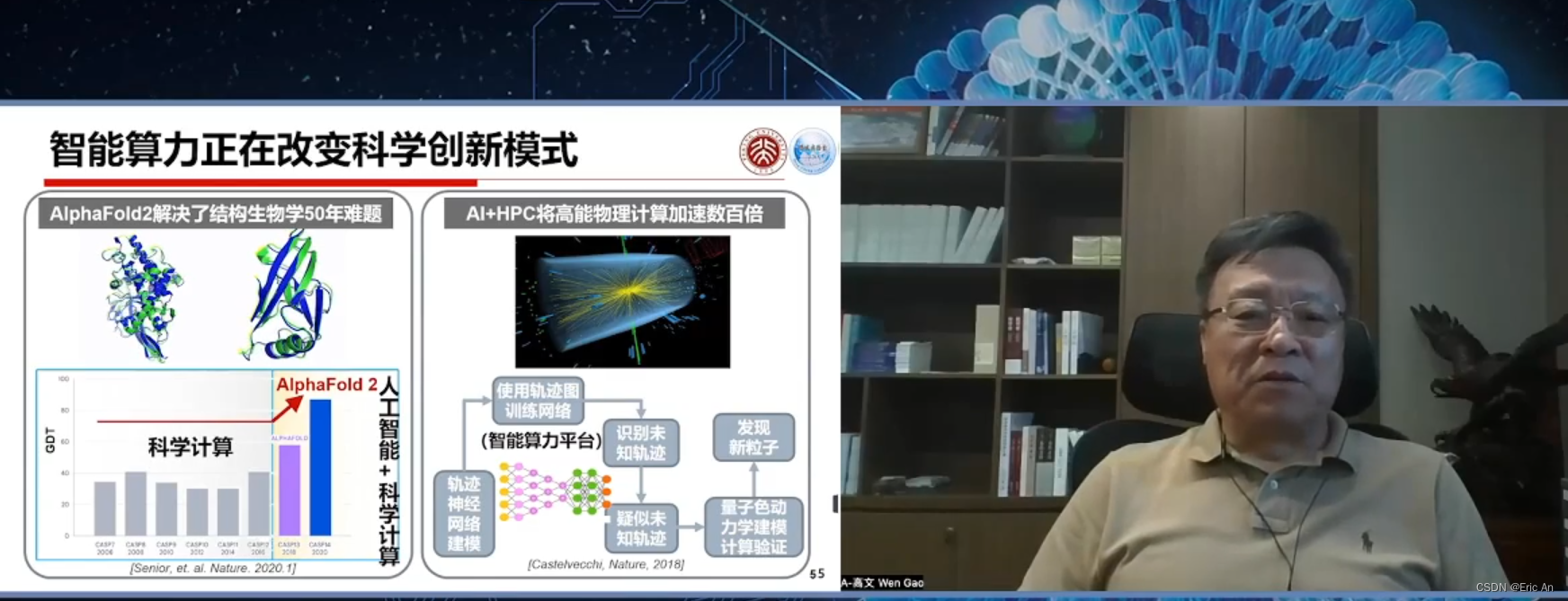
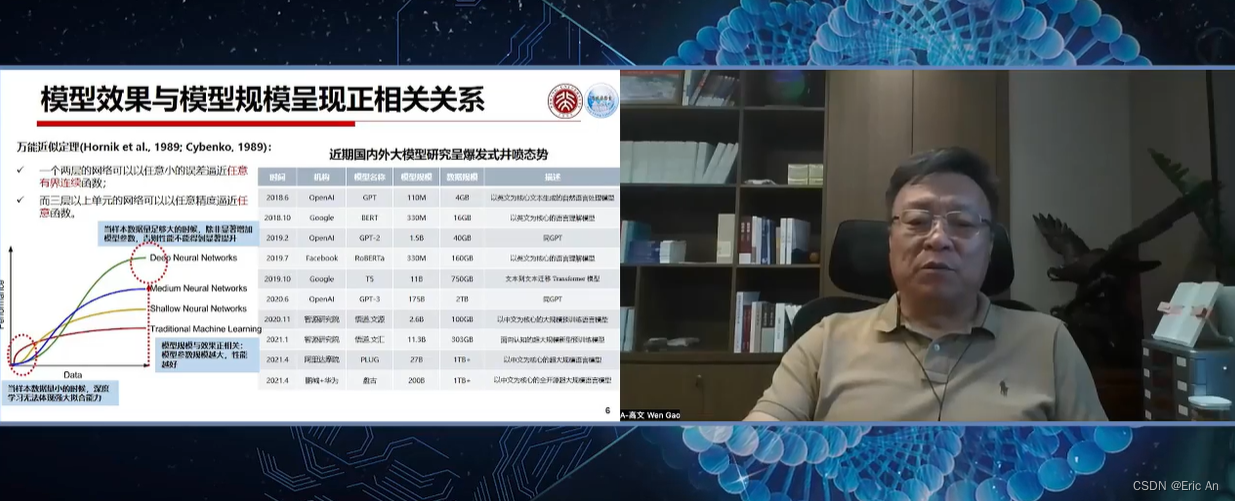
VLA研究领域(智能体、具身智能)
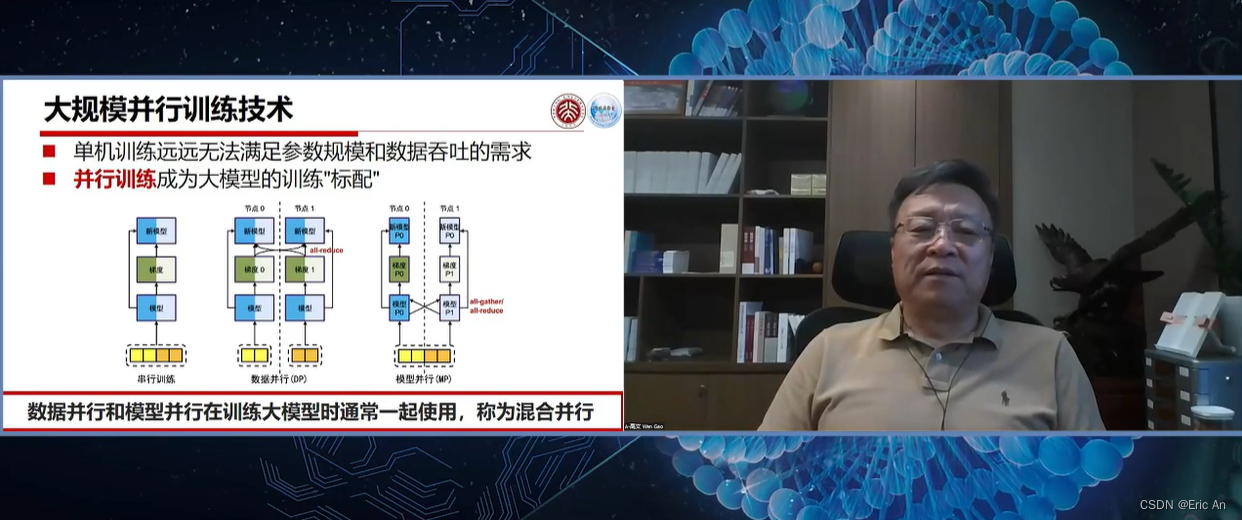
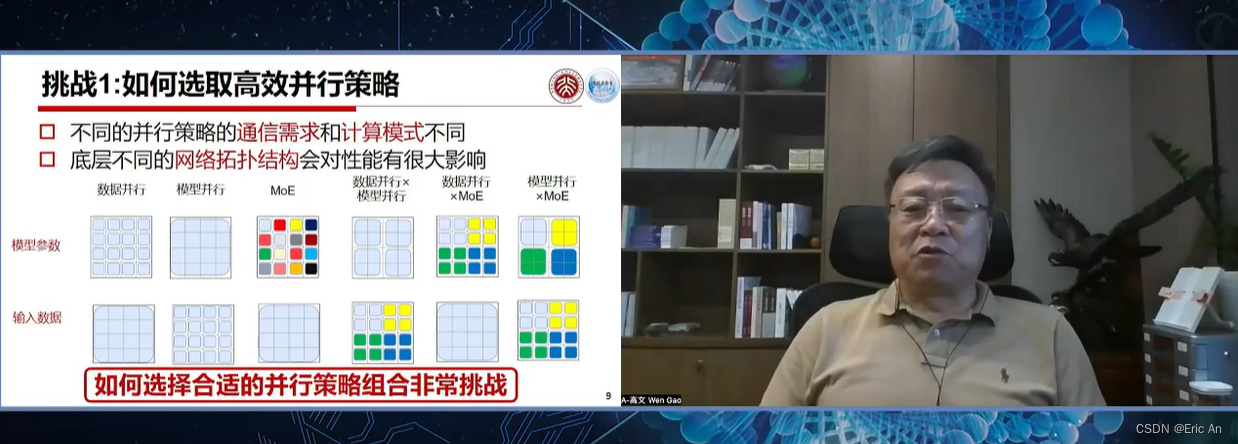
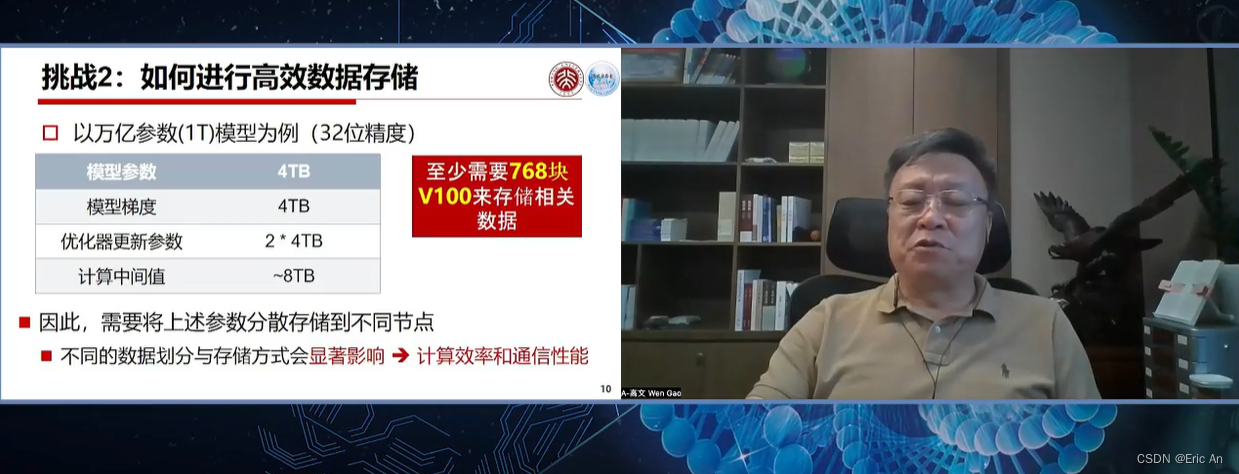
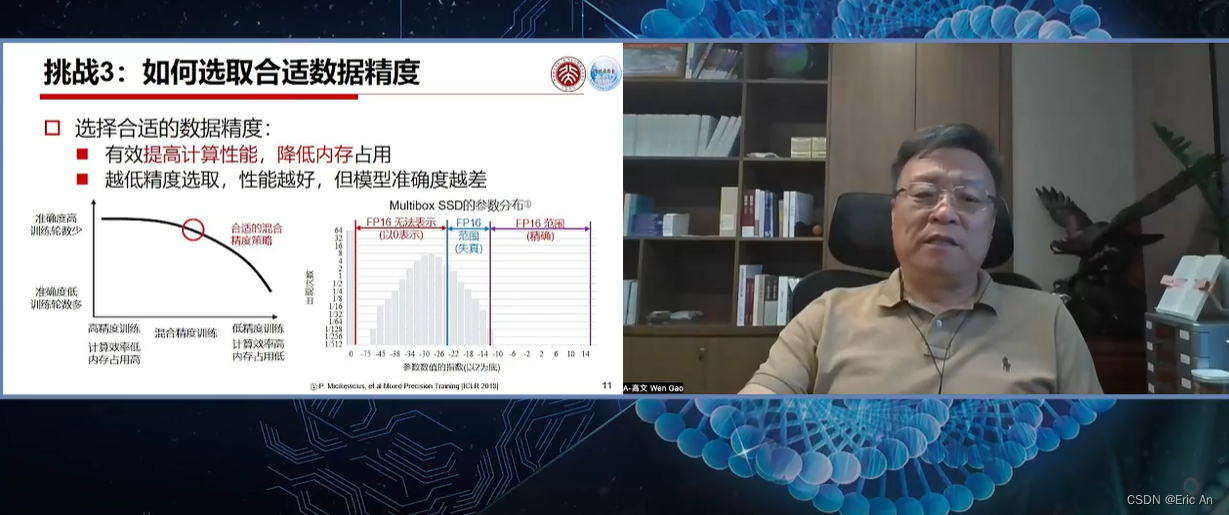
这篇关于通用大模型研究重点之五:llama family的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







