本文主要是介绍论文解读-ASAP: Fast Mobile Application Switch via Adaptive Prepaging,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
研究背景:
用户使用移动设备同时打开多个App,很容易造成移动设备的内存紧缺。现有解决方法一般采用杀死守护进程(lmkd)来释放内存或者基于压缩算法的in-memory swap(ZRAM)方式, 这些方法会面临用户切换回被杀死的进程过程效率低下问题,且严重影响用户体验。
其中Android操作系统的in-memory swap机制:其特点是需要压缩和解压缩匿名页,比通过I/O将匿名页写入磁盘更快,但是压缩的页依然占用内存空间且压缩解压缩占用CPU时钟周期。而lmkd机制又比ZRAM机制先执行。为此,作者使用Launch time和Switch Time比较lmkd和ZRAM, 普通swap之间的差异,发现lmkd占用时间较大,需要减少lmkd的使用,围绕ZRAM的优化展开。
论文方案:
实验发现,造成switch time大大增加的罪魁祸首就是请求调页的低效率,文件页和匿名页的交换足迹(footprint)不一样。为文件页和匿名页设计不同的预取器,利用预取来提高硬件利用率。对于文件页,利用不变的特点减少负载;对于匿名页,则利用实时信息追踪变化的switch footp
|
|
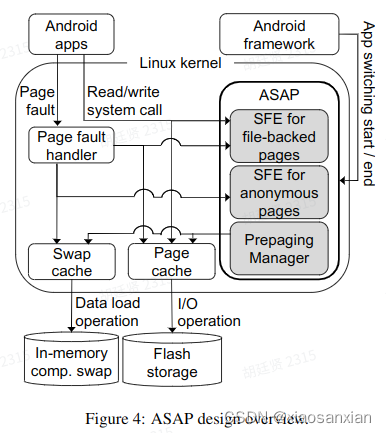
针对文件页,设计了五个部分:

| Offline profiling 利用前十次交换,把访问超过八次的页当作预取的候选页。其结果被存储在一个文件中。 Fault logging 记录每次交换时的缺页信息。存放在fault buffer中。 Prepaging Target Insert 匹配fault buffer和offline candidate table,能匹配到,则插入prepaging target table。 Prepaging Target Merging Extent:一次切换时同一文件中被访问的页的集合。两个extent相近则合并。 Prepaging Target Eviction 被预取的页只要在一次交换中没有被用到,则从prepaging target table中移除。 |
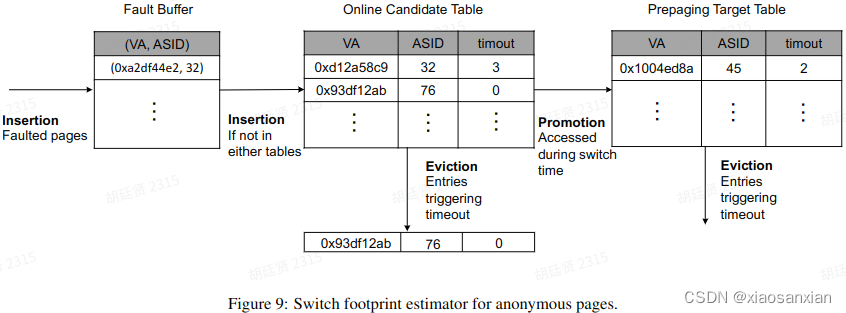
针对匿名页,设计了如下五个部分:
|
|
| Fault logging 记录所有匿名页的缺页中断。 Access logging 根据页表的访问位,记录Prepaging Target Table和Online Candidate Table中的页在应用切换时的访问情况。 Prepaging Target Insertion 把新的缺页中断加入Online Candidate Table。 Prepaging Target Promotion 若在Online Candidate Table中的页被访问了,则加入prepaging target table。 Prepaging Target Eviction 在prepaging target table和Online Candidate Table中的页有个超时计时器,每次切换时计时器减小,而页被访问时计时器重置,超时后页被丢弃。 |
实验结论:
ASAP通过合理设计预取机制,在两种设备上,平均性能分别提高了22.2%、28.3%,取得了不错的效果。ASAP是一种全新的swap机制,基于预取策略很好地改进了用户体验。
这篇关于论文解读-ASAP: Fast Mobile Application Switch via Adaptive Prepaging的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







