本文主要是介绍数据分析特辑 - 如何用Tableau做一个数据故事?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
挺多公司都有使用Tableau这个可视化软件,因为在分析的进阶阶段所以自己抽空在B站(不得不说,B站是个不错的学习网站)跟着学习视频实操了一波,大概了解了一些图表的绘制以及一些升级操作。刚好有个契机所以用了Tableau从头到尾弄了一个数据故事,这里主要讲下心路历程吧,作为自己绘制第一个数据故事存在的不足还是比较多的,也方便自己以后再次复盘。
Tableau故事绘制
这里其实不会讲太多Tableau的实际操作,更多的还是对整体步骤层面的思考~这个绘制过程是以课题式的形式开展的,从数据集的选择到最终整体看板的布局都思考了一番,具体如下:
1.选择数据集
在知乎上有挺多关于数据集搜索方法的好回答,我自己也做了相应的总结,在我的上一篇博客里可以了解:https://blog.csdn.net/Totoro1745/article/details/108027574
2.确定数据集以及分析主题
通过上述方式我在Kaggle看中了一份数据集,其中是关于销售额破10w的电子游戏排名情况以及相应数据,具体的数据字段如下所示:
- Rank - Ranking of overall sales
- Name - The games name
- Platform - Platform of the games release (i.e. PC,PS4, etc.)
- Year - Year of the game’s release
- Genre - Genre of the game
- Publisher - Publisher of the game
- NA_Sales - Sales in North America (in millions)
- EU_Sales - Sales in Europe (in millions)
- JP_Sales - Sales in Japan (in millions)
- Other_Sales - Sales in the rest of the world (in millions)
- Global_Sales - Total worldwide sales.
从数据中可以了解到的数据信息有:
- 全球排名靠前的电子游戏相关信息
- 排名所用指标为全球销量
- 销量中有分不同的地区:北美、欧洲、日本以及其他
- 发行年份字段有存在空值,时间区间为1980-2020
对分析的主题定位在:
- 电子游戏市场分析
3.故事构思
这里的话我想提一下《用数据讲故事》这本书,里面对如何去表达数据其实有一套方法,从受众出发,抓住数据重点,真正地传达具体的信息,这里就附一张书籍的简单导图,把书中的精髓应用到实践中还是需要不断地去打磨的~
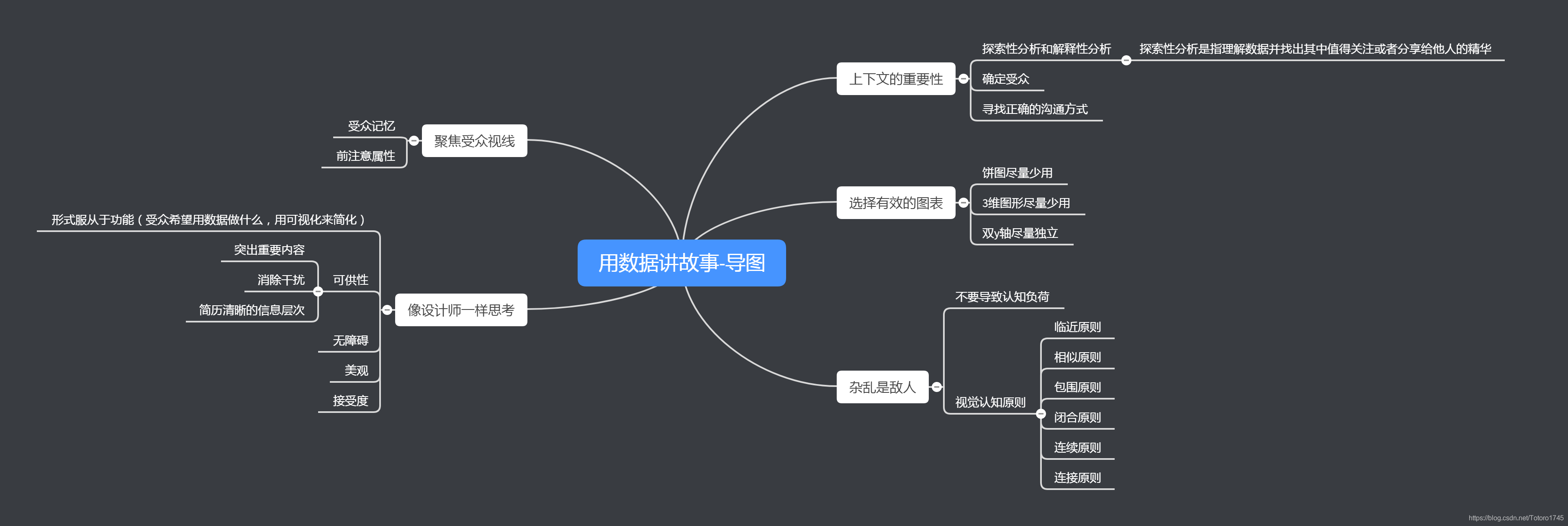
通过数据的初步摸索以及定位的思考,我的受众初步定位为对这份数据毫无了解的人,因此我的想法是以整体入手再对局部进行突出,同时抓住分析过程中的一些具体节点进行扩展。整体的布局如下导图所示:(慢慢地习惯用导图去做思路的梳理,强推使用幕布,快速上手)

4.故事绘制
前期工作做的差不多了,这个时候就该开始动手了~这里不会讲Tableau的实际操作过程,就放一张成果的首页图,对图表的选择以及细节的凸显都是需要不断学习的,也希望有在数据这条路上前行的人儿多点交流!除此之外,在Tableau官网的gallery有挺多好的作品可以去多看看。

这篇关于数据分析特辑 - 如何用Tableau做一个数据故事?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



