本文主要是介绍一周学会Django5 Python Web开发-Django5模型数据新增,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
锋哥原创的Python Web开发 Django5视频教程:
2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计46条视频,包括:2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~、第2讲 Django5安装、第3讲 Django5创建项目(用命令方式)等,UP主更多精彩视频,请关注UP账号。![]() https://www.bilibili.com/video/BV14Z421z78C/Django对数据库的数据进行增、删、改操作是借助内置ORM框架所提供的API方法实现的,简单来说,它在模型基础类 Model里定义数据操作方法,通过类继承将这些操作方法传给开发者自定义的模型对象,再由模型对象调用即可实现数据操作。
https://www.bilibili.com/video/BV14Z421z78C/Django对数据库的数据进行增、删、改操作是借助内置ORM框架所提供的API方法实现的,简单来说,它在模型基础类 Model里定义数据操作方法,通过类继承将这些操作方法传给开发者自定义的模型对象,再由模型对象调用即可实现数据操作。
添加操作通过模型的save方法实现,添加下可以返回主键id值。
我们在前面实例的基础上,来实现这个例子。
因为添加页面是需要图书类别的数据,我们用下拉框实现。所以这里需要一个预处理操作。
先在views.py里定义一个添加预处理方法preAdd
def preAdd(request):"""预处理,添加操作:param request::return:"""bookTypeList = BookTypeInfo.objects.all()print(bookTypeList)content_value = {"title": "图书添加", "bookTypeList": bookTypeList}return render(request, 'book/add.html', context=content_value)urls.py里加下映射:
path('book/preAdd', helloWorld.views.preAdd),原先的list.html,加上添加的链接:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{ title }}</title>
</head>
<body>
<h3>{{ title }}</h3>
<a href="/book/preAdd">添加</a><br/><br/>
<table border="1"><tr><th>编号</th><th>图书名称</th><th>价格</th><th>出版日期</th><th>图书类别</th></tr>{% for book in bookList %}<tr><td>{{ book.id }}</td><td>{{ book.bookName }}</td><td>{{ book.price }}</td><td>{{ book.publishDate | date:'Y-m-d' }}</td><td>{{ book.bookType.bookTypeName }}</td></tr>{% endfor %}
</table>
</body>
</html>再创建下图书添加页面add.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{ title }}</title>
</head>
<body>
<h3>{{ title }}</h3>
<form action="/book/add" method="post">{% csrf_token %}<table><tr><td>图书名称:</td><td><input type="text" name="bookName"></td></tr><tr><td>出版日期:</td><td><input type="text" name="publishDate"></td></tr><tr><td>图书类别:</td><td><select name="bookType_id">{% for bookType in bookTypeList %}<option value="{{ bookType.id }}">{{ bookType.bookTypeName }}</option>{% endfor %}</select></td></tr><tr><td>图书价格:</td><td><input type="text" name="price"></td></tr><tr><td colspan="2"><input type="submit" value="提交"></td></tr></table>
</form>
</body>
</html>最后在views.py里创建图书添加函数add:
def add(request):"""图书添加:param request::return:"""# print(request.POST.get("bookName"))# print(request.POST.get("publishDate"))# print(request.POST.get("bookType_id"))# print(request.POST.get("price"))book = BookInfo()book.bookName = request.POST.get("bookName")book.publishDate = request.POST.get("publishDate")book.bookType_id = request.POST.get("bookType_id")book.price = request.POST.get("price")book.save()# 数据添加后,获取新增数据的主键idprint(book.id)return bookList(request)运行测试:浏览器输入:http://127.0.0.1:8000/book/list
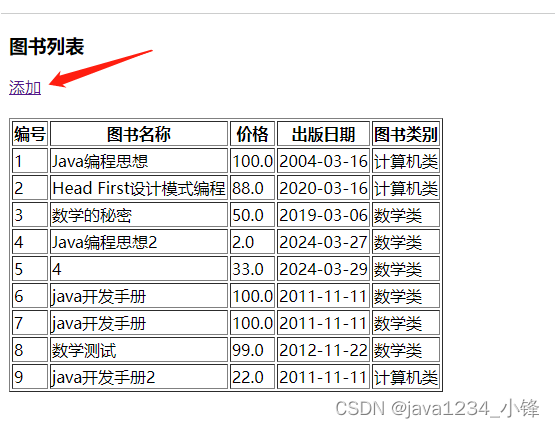
点击添加链接,
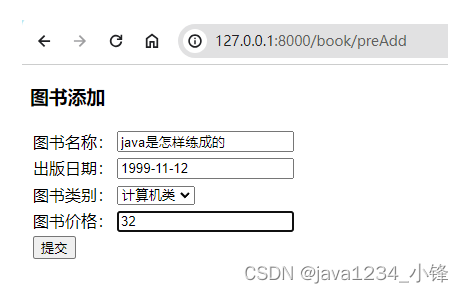
进入图书添加页面,输入图书信息,点提交:
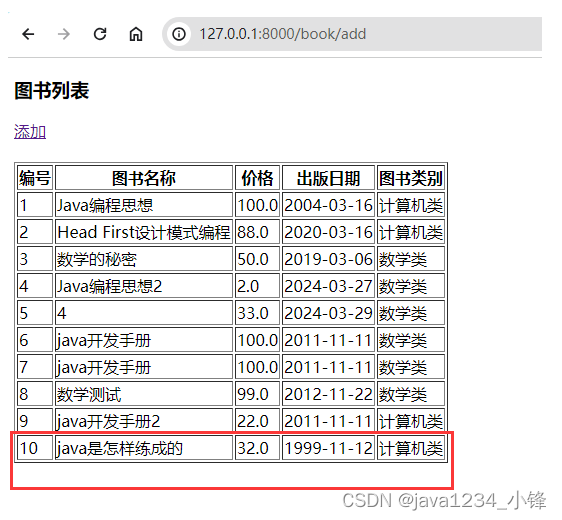
页面显示最新数据;
这篇关于一周学会Django5 Python Web开发-Django5模型数据新增的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





