本文主要是介绍Google DeepMind: Many-Shot vs. Few-Shot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍了如何通过增大上下文窗口,利用大型语言模型(LLMs)进行多实例上下文学习(Many-Shot In-Context Learning,ICL)的方法。主要描述了现有的几实例上下文学习方法虽然在推理时能够通过少量例子学习,但当例子数量增多时,其性能并没有得到明显提升。此外,文章还解释了现有工作由于依赖人工生成的例子数量有限,无法充分利用多实例上下文学习的潜力。
核心挑战
1️⃣ 挑战1:如何在没有人工例子的情况下进行有效的多实例学习
多实例ICL在例子数量增加时表现出显著的性能提升,但受限于可用的人工生成例子数量。文章通过引入强化上下文学习(Reinforced ICL)使用模型生成的思考过程作为替代,有效解决了这一挑战。
2️⃣ 挑战2:如何克服预训练偏差,提升模型在复杂推理任务上的表现
文章通过实施无监督ICL,完全去除提示中的推理过程,只用特定领域的问题来提示模型。这种方法特别适用于复杂的推理任务,并能有效地克服预训练中的偏见。
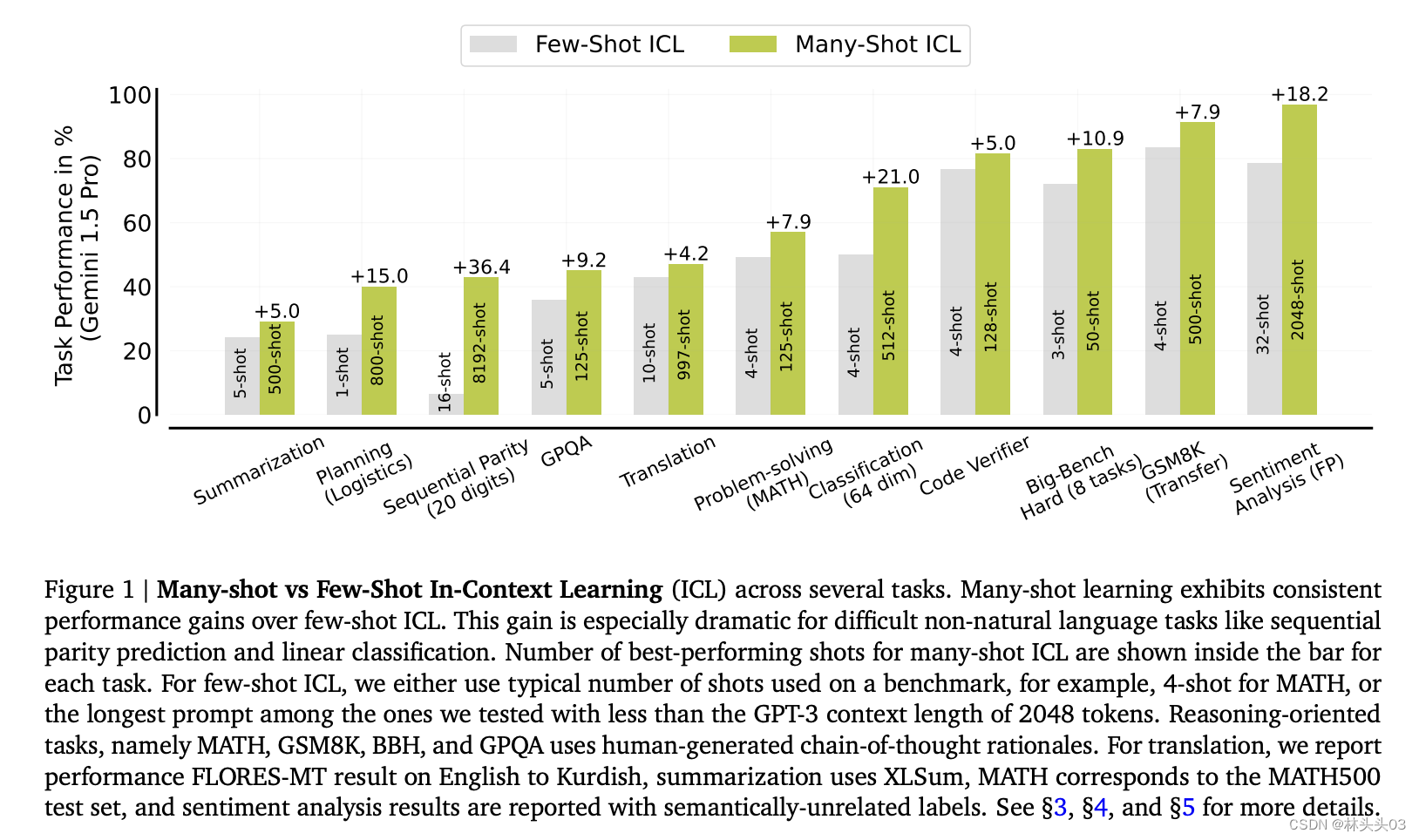
Figure 1: 展示了在多种任务上进行多实例和几实例上下文学习(ICL)的性能比较。图中显示,随着实例(shots)数量的增加,从几实例到多实例学习,性能有显著的提升,尤其是在一些非自然语言任务(如序列奇偶性预测和线性分类)上表现更为突出。图表还标出了在多实例学习中表现最佳的实例数量。
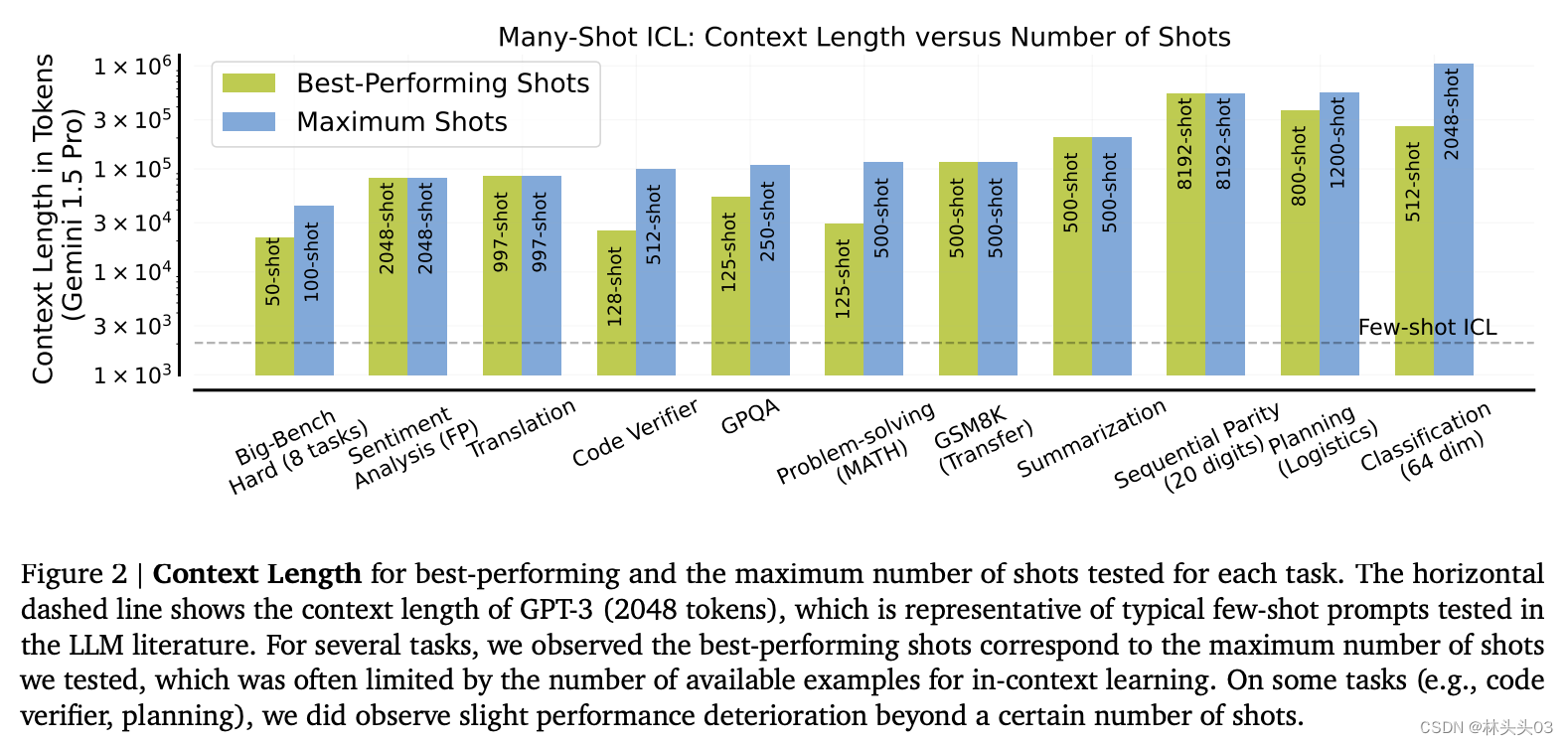
Figure 2: 描述了在多种任务上,最佳性能的实例数量与最大测试实例数量之间的关系,并展示了这些数量与上下文长度的关系。图中的水平虚线表示GPT-3的典型上下文长度(2048个令牌),这是LLM文献中测试的典型几实例提示的代表。对于多个任务,最佳性能的实例数量通常对应于测试的最大实例数量,尽管在某些任务(如代码验证器、规划)上,实例数量超过一定数目后,性能有所下降。
1️⃣ 挑战1:在没有人工例子的情况下进行有效的多实例学习
想象一下你正在尝试学习做饭,但没有食谱,只能依靠看别人做来学习。在多实例上下文学习中,我们面临的挑战类似于需要在没有详细食谱(人工例子)的情况下,通过观察许多不同的烹饪示例来学习如何烹饪。
为了解决这个问题,文章提出了“强化上下文学习”(Reinforced ICL)。这类似于你在观察了几次烹饪后,尝试自己做菜,然后根据结果(好吃或不好吃)来调整你的烹饪方法。在这种方法中,模型不再依赖人工编写的解释,而是生成自己的思考过程来学习。这就好比你通过实践和自我反思来掌握烹饪技巧,而不是仅仅模仿别人的做法。
2️⃣ 挑战2:克服预训练偏差,提升模型在复杂推理任务上的表现
设想你习惯于在城市环境中驾驶,突然有一天你需要在崎岖的山路上开车。你的驾驶习惯和技巧可能需要调整以适应这种新环境。
在文章中,挑战2类似于模型需要适应新的、可能与其训练数据不一致的任务或领域。这里引入的“无监督上下文学习”(Unsupervised ICL)策略相当于模型不再依赖于问题-解决方案对进行学习,而是直接面对问题。这就像你在没有导航的情况下探索山路,必须依赖自己对驾驶的基本理解和即时的判断来应对不同的驾驶情况。
通过这种方式,模型通过直接面对挑战,不依赖既定的解决方案模式,而是学习如何自行构建解决策略,从而有效地克服了预训练中的偏见,并增强了在新领域的适应性和解决问题的能力。这种策略特别适合复杂的推理任务,可以让模型在面对未知和复杂问题时表现更佳。
另外本文中有几个有趣的发现和观点:
1️⃣ 多实例学习的效果超过了预期:文章发现,与几实例学习相比,多实例学习在各种任务上都表现出显著的性能提升,特别是在复杂的非自然语言任务中,如序列奇偶性预测和线性分类。
2️⃣ 模型生成的解释可能优于人工编写的解释:在某些任务中,即使在实例数量相同的情况下,使用模型生成的思考过程(Reinforced ICL)的性能有时甚至能超过使用人工编写的解释。这表明在某些情况下,模型自身生成的内容能更有效地促进学习。
3️⃣ 多实例ICL能够克服预训练偏见:与几实例ICL相比,多实例ICL在处理倾向性标签(如情感分析中的标签替换)时表现出更好的适应性和准确性,显示出随着训练实例的增加,模型能够有效地克服其预训练中的偏见。
4️⃣ 下一个令牌预测损失可能不是下游性能的可靠指标:研究还揭示了,在使用与测试集分布不一致的提示时,负对数似然(NLL)可能无法预测下游ICL性能。这表明评估模型性能时需要考虑更多的指标,而不仅仅是传统的损失函数。
总结
本文通过实验和新方法展示了大型语言模型在多实例上下文学习中的潜力,特别是在克服预训练偏见和处理复杂任务方面的能力。这些发现为未来利用语言模型进行更高效学习提供了有价值的见解和方法论。
今日 git 更新了多篇 arvix 上最新发表的论文,更详细的总结和更多的论文,
请移步 🔗github 搜索 llm-paper-daily 每日更新论文,觉得有帮助的,帮帮点个 🌟 哈。
这篇关于Google DeepMind: Many-Shot vs. Few-Shot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








