本文主要是介绍1688采集一件代发API接口数据,商品详情,支持高并发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
业务场景:作为全球最大的 B2C 电子商务平台之一,阿里巴巴中国站(1688)平台提供了丰富的商品资源,吸引了大量的全球买家和卖家。为了方便开发者接入 1688 平台,1688 平台提供了丰富的 API 接口,其中商品详情接口是非常重要的一部分。大家有探讨稳定采集 1688 整站实时商品详情数据接口,通过该接口开发者可以更好地了解商品的情况,商品详情详细信息查询,数据参数包括:获取商品列表主图、视频、价格、标题、优惠价、最小起批价、一件代发价、库存、销量、sku、sku 属性、sku 图片、详情描述等页面上有的数据完整解决方案帮助买家更准确地进行商品选购。这个引起了我技术挑战的兴趣。目前,自己做了压测,QPS 高、出滑块概率极低,API 整体稳定,可满足业务场景的性能需求。
1688 商品详情 API 接口是 1688 开放平台提供的一项接口服务,允许第三方开发者通过API 接口获取 1688 平台上商品的详细信息。1688 商品详情 API 接口文档包含了接口请求地址、请求参数、响应参数和示例等详细信息,开发者在使用该接口服务时需要先仔细查阅接口文档,确保自己了解接口的使用方法和限制条件。

1、API公共参数示例
请求地址: https://api-gw.onebound.cn/1688/item_get
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(演示示例) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=610947572360
参数说明:num_iid:1688商品ID
sales_data:&sales_data=1 获取近30天成交数据
agent:&agent=1 获取1688分销代发价格数据
3. 请求代码示例,支持高并发请求(CURL、PHP 、PHPsdk 、Java 、C# 、Python...)
# coding:utf-8
"""
Compatible for python2.x and python3.x
requirement: pip install requests
"""
from __future__ import print_function
import requests
# 请求示例 url 默认请求参数已经做URL编码
url = "https://api-vx.Taobaoapi2014.cn/1688/item_get/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&num_iid=610947572360"
headers = {
"Accept-Encoding": "gzip",
"Connection": "close"
}
if __name__ == "__main__":
r = requests.get(url, headers=headers)
json_obj = r.json()
print(json_obj)
4、响应参数示例
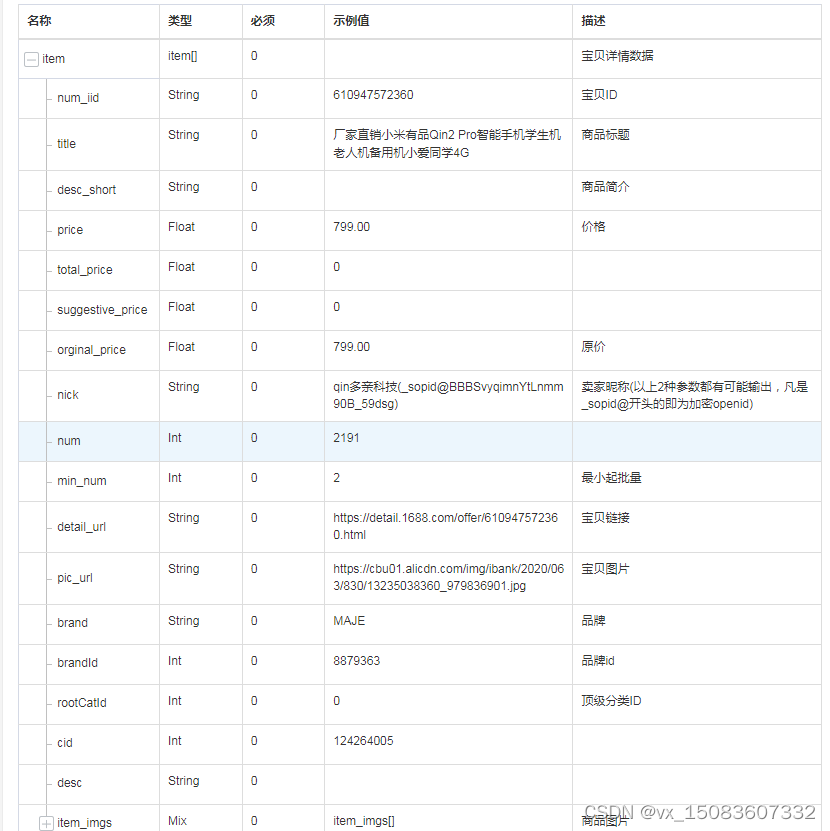
这篇关于1688采集一件代发API接口数据,商品详情,支持高并发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





