本文主要是介绍GoogleNet网络训练集和测试集搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
测试集和训练集都是在之前搭建好的基础上进行修改的,重点记录与之前不同的代码。
还是使用的花分类的数据集进行训练和测试的。
一、训练集
1、搭建网络
设置参数:使用辅助分类器,采用权重初始化
net = GoogleNet(num_classes=5, aux_logits=True, init_weights=True)2、参数输出
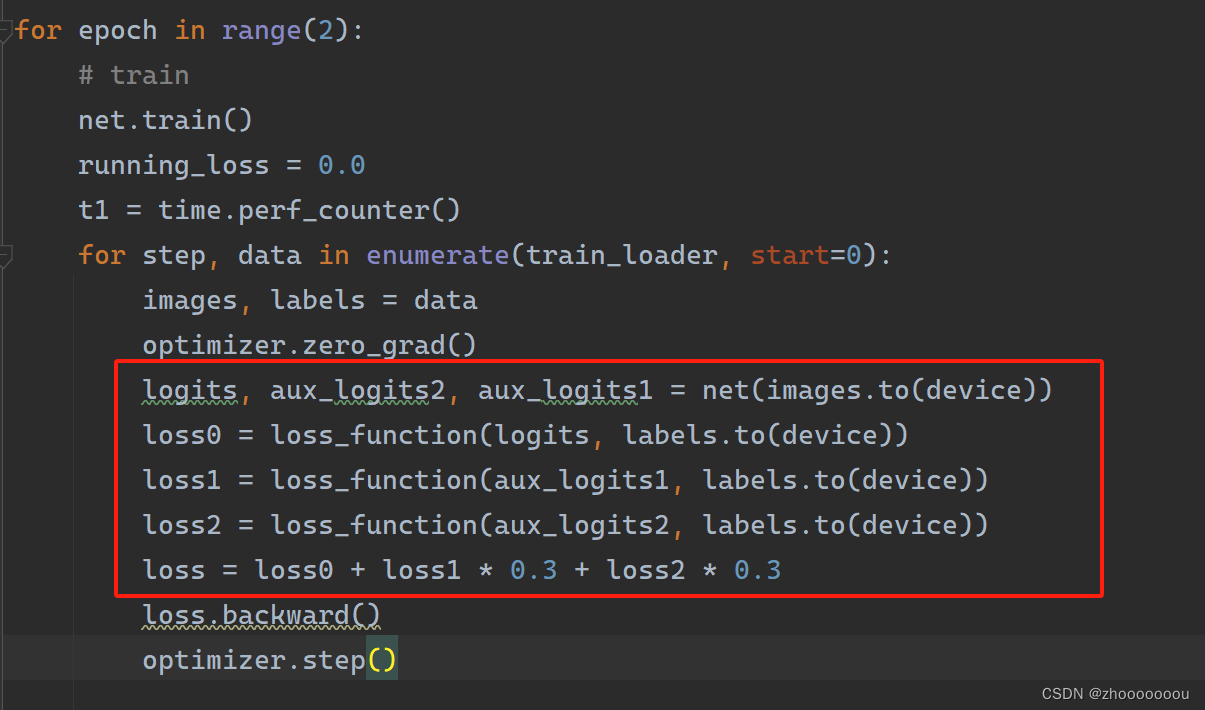
之前的模型只有 1 个输出,但由于GoogleNet使用了两个辅助分类器,所以会有 3 个输出。
定义三个输出,分别计算主分类器、辅助分类器1、辅助分类器2的损失函数并相加,最后将损失函数反向传播,使用优化器更新参数模型。
不单独放代码了,不知道哪里是改动的。图片中红色框中是改动的
整个训练集的代码
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib as plt
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import GoogleNet
import os
import json
import timedevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = data_root + "/data_set/flower_data"
# train set
train_dataset = datasets.ImageFolder(root=image_path + "/train",transform=data_transform["train"])
train_num = len(train_dataset)# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflower': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# 把文件写入接送文件
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices,json', 'w') as json_file:json_file.write(json_str)batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=0)
#
validate_dataset = datasets.ImageFolder(root=image_path + "/val",transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size,shuffle=False, num_workers=0)# test_data_iter = iter(validate_loader)
# test_image, test_label = next(test_data_iter)
#
# # 查看图片
# def imshow(img):
# img = img / 2 + 0.5
# nping = img.numpy()
# plt.imshow(np.transpose(nping, (1, 2, 0)))
# plt.show()
# # print labels
# print(' '.join('%5s' % str(cla_dict[test_label[j].item()]) for j in range(4)))
# # show images
# imshow(utils.make_grid(test_image))net = GoogleNet(num_classes=5, aux_logits=True, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0003)best_acc = 0.0
save_path = './GoogleNet.pth'
# best_acc = 0.0
for epoch in range(2):# trainnet.train()running_loss = 0.0t1 = time.perf_counter()for step, data in enumerate(train_loader, start=0):images, labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = net(images.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()rate = (step+1) / len(train_loader)a = "*" * int(rate*50)b = "." *int((1-rate)*50)print("\rtrain loss: (:3.0f)%[()->:.3f)".format(int(rate * 100), a, b, loss), end="")print()print(time.perf_counter()-t1)net.eval()acc = 0.0with torch.no_grad():for data_test in validate_loader:test_images, test_labels = data_testoutputs = net(test_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += (predict_y == test_labels.to(device)).sum().item()accurate_test = acc / val_numif accurate_test > best_acc:best_acc = accurate_testtorch.save(net.state_dict(), save_path)print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, running_loss / step, acc / val_num))
print("Finished Training")
训练完成
中间有几次报错,不过在看懂报错后很快改过来了。

二、测试集
载入模型
在创建模型的时候,aux_logits不会构建辅助分类器,但是之前训练的参数会保存。
所以,在载入模型的时候,要设置参数strict=False, 它可以精准匹配当前模型与所需要载入的权重模型的结构。
辅助分类器中的参数全部存放在unexpecte_keys中。

测试集全部代码
可以自己找图片进行预测看准确率。
import torch
import matplotlib.pyplot as plt
import json
from model import GoogleNet
from PIL import Image
from torchvision import transformsdata_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load image
img = Image.open("8.jpeg")
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)# read class_indent
try:json_file = open('./class_indices,json', 'r')class_indict = json.load(json_file)
except Exception as e:print(e)exit(-1)# create model
model = GoogleNet(num_classes=5, aux_logits=False)
model_weight_path = "./GoogleNet.pth"
missing_keys, unexpected_keys = model.load_state_dict(torch.load(model_weight_path), strict=False)
model.eval()
with torch.no_grad():output = torch.squeeze(model(img))predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].item())
plt.show()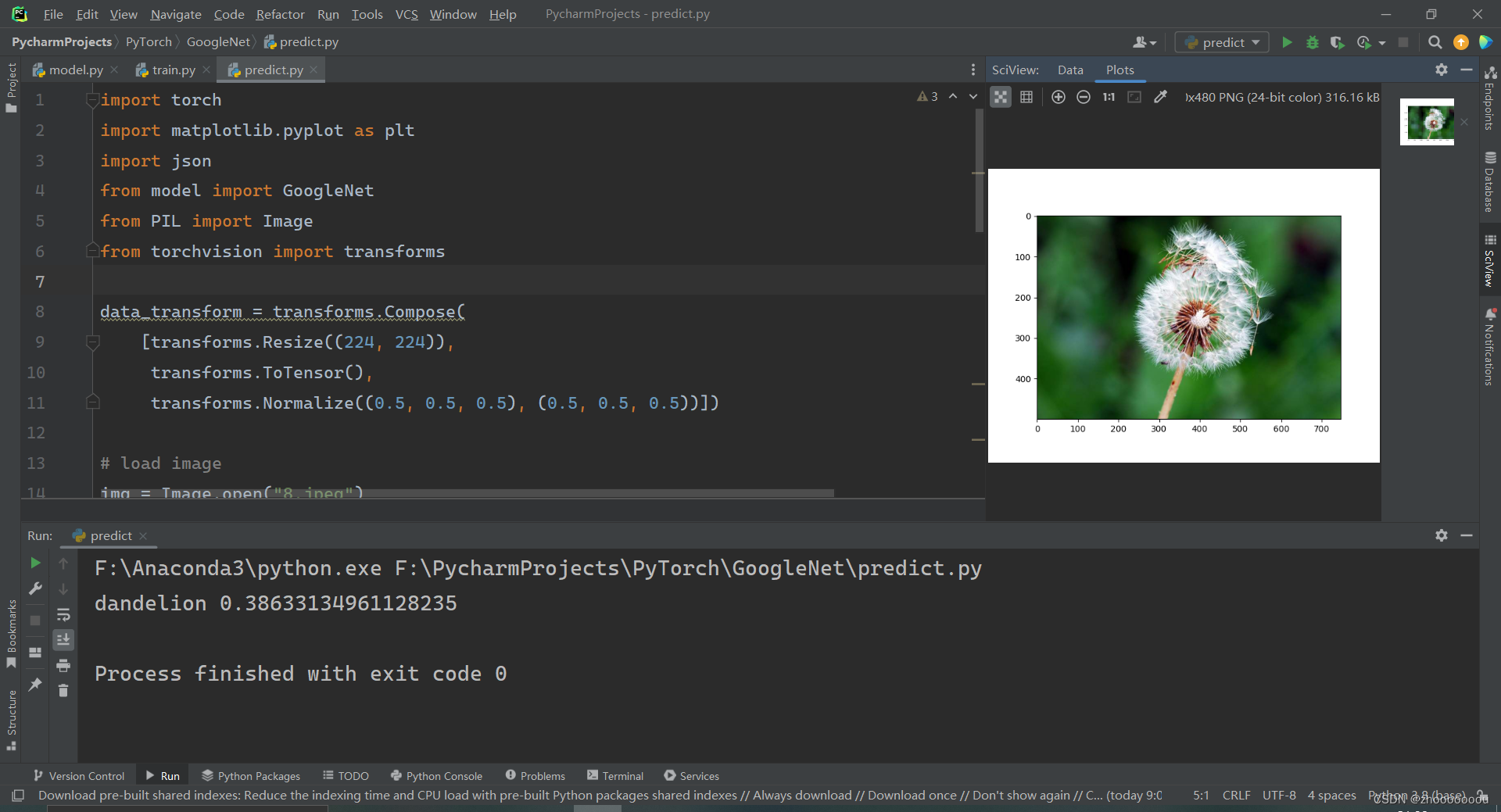
准确率好低,可能是模型训练的还不够吧。
这篇关于GoogleNet网络训练集和测试集搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









