本文主要是介绍批量插入10w数据方法对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境准备(mysql5.7)
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '唯一id',
`user_id` bigint(10) DEFAULT NULL COMMENT '用户id-uuid',
`user_name` varchar(100) NOT NULL COMMENT '用户名',
`user_age` bigint(10) DEFAULT NULL COMMENT '用户年龄',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=300001 DEFAULT CHARSET=latin1;
配置依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.9</version>
</dependency>
方式一:普通JDBC插入
public class JDBCDemo {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/daily_learn_db";
String user = "root";
String password = "123456";
String driver = "com.mysql.jdbc.Driver";
// sql语句
String sql = "INSERT INTO User(user_id,user_name,user_age) VALUES (?,?,?);";
Connection conn = null;
PreparedStatement ps = null;
// 开始时间
long start = System.currentTimeMillis();
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, user, password);
ps = conn.prepareStatement(sql);
// 循环遍历插入数据
for (int i = 1; i <= 100000; i++) {
ps.setLong(1, Long.parseLong(RandomUtil.randomNumbers(5)));
ps.setString(2, "coderwhs");
ps.setLong(3, Long.parseLong(RandomUtil.randomNumbers(2)));
ps.executeUpdate();
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(普通插入方式):" + (end - start) + " ms");
}
}
运行结果 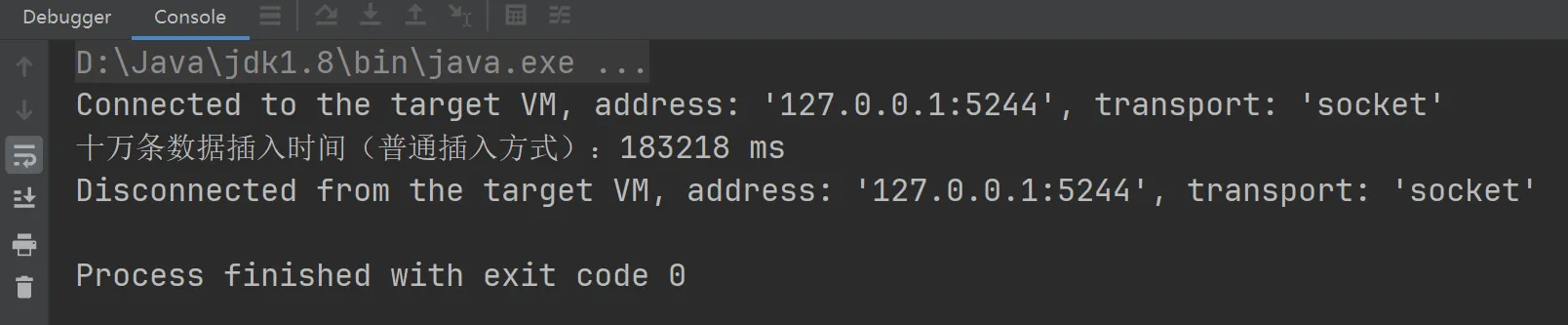 可以看到,一条一条插入10w条数据,一共需要约183s时间
可以看到,一条一条插入10w条数据,一共需要约183s时间
方式二:JDBC批量插入+手动事务提
public static void main(String[] args) {
// url 设置允许重写批量提交 rewriteBatchedStatements=true
String url = "jdbc:mysql://localhost:3306/daily_learn_db?rewriteBatchedStatements=true";
String user = "root";
String password = "123456";
String driver = "com.mysql.jdbc.Driver";
String sql = "INSERT INTO User(user_id,user_name,user_age,create_time) VALUES (?,?,?,now())";
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, user, password);
ps = conn.prepareStatement(sql);
// 关闭自动提交事务
conn.setAutoCommit(false);
for (int i = 1; i <= 100000; i++) {
ps.setLong(1, Long.parseLong(RandomUtil.randomNumbers(5)));
ps.setString(2, "coderwhs");
ps.setLong(3, Long.parseLong(RandomUtil.randomNumbers(2)));
// 加入批处理(将当前待执行的sql加入缓存)
ps.addBatch();
// 以1000条数据作为分片,参考mybatisPlus的默认切片值
if(i % 1000 == 0){
// 执行缓存中的sql语句,并且清空缓存
ps.executeBatch();
ps.clearBatch();
}
}
ps.executeBatch();
ps.clearBatch();
// 事务提交
conn.commit();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
try {
// 事务回滚
if (conn != null){
conn.rollback();
}
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(批量插入方式):" + (end - start) + " ms");
}
运行结果: 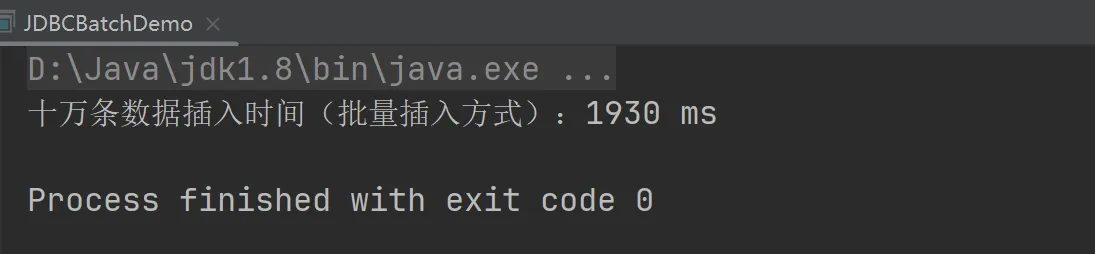 时间上约为1.9秒,比起第一种方式提高了近100倍的效率
时间上约为1.9秒,比起第一种方式提高了近100倍的效率
这种实现方式需要注意几个问题:
-
使用 prepareStatement的如下三个方法来实现批量操作
-
addBatch():该方法用于向批处理中添加一批参数。通常在执行批量操作之前,通过多次调用该方法,将不同参数的sql添加到批处理之中,然后一次性将这些参数一起提交给数据库执行。 -
executeBatch():该方法表示执行当前的批处理参数。该方法会返回一个整数数组,表示批处理每个操作所影响的行数。 -
clearBatch():该方法用于清空当前的批处理参数,每次执行完后需要调用该方法进行清空
-
在url上需要加上 rewriteBatchedStatements=true才能实现真正的批处理。这个设置是实现允许重写批量提交;在默认不开启的情况下,会无视executeBatch()方法,将原本应该批量执行的sql又拆成单条语句去执行 -
使用批处理方式时,sql语句后面不能以分号结束,单条语句执行时可以用分号结束。这是因为批处理时候需要进行sql拼接,若带有分号,则会变成 INSERT INTO User(user_id,user_name,user_age,create_time) VALUES (?,?,?,now());,(?,?,?,now());,(?,?,?,now());,则会执行报错 -
为什么以1000作为分片大小?这是参考MybatisPlus框架的默认分片大小,分片操作可以避免一次性提交的数据量过大而导致数据库处理时出现性能问题和内存占用过高问题,合理的分片大小可以减轻数据库的负担 -
手动提交事务可以提高插入速度,在批量插入大量数据时,手动事务提交相对自动事务提交可以减少磁盘的IO次数,减少锁竞争,提高性能。可以通过 setAutoCommit(false)关闭自动提交事务,等全部插入完成后再commit()手动提交事务
方式三:MyBatis / MyBatis Plus 实现批量插入
UserMapper.xml代码
<insert id="insertByOne">
INSERT INTO user(user_id,user_name,user_age,create_time)
VALUES (#{userId},#{userName},#{userAge},now())
</insert>
<insert id="insertByForeach">
INSERT INTO user(user_id,user_name,user_age,create_time)
VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.userId},#{user.userName},#{user.userAge},now())
</foreach>
</insert>
UserServiceImpl代码
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User>
implements UserService{
@Resource
private UserMapper userMapper;
@Resource
private SqlSessionFactory sqlSessionFactory;
//普通插入
@Override
public int saveByFor(List<User> feeList) {
// 记录结果(影响行数)
int res = 0;
// 循环插入
for (User user : feeList) {
res += userMapper.insertByOne(user);
}
return res;
}
//foreach动态拼接插入
@Override
public int saveByForeach(List<User> feeList) {
// 通过mapper的foreach动态拼接sql插入
return userMapper.insertByForeach(feeList);
}
//批处理插入
@Transactional
@Override
public int saveByBatch(List<User> feeList) {
// 记录结果(影响行数)
int res = 0;
// 开启批处理模式
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper feeMapper = sqlSession.getMapper(UserMapper.class);
for (int i = 1; i <= feeList.size(); i++) {
// 利用mapper的单条插入方法插入
res += feeMapper.insertByOne(feeList.get(i-1));
// 进行分片类似 JDBC 的批处理
if (i % 100000 == 0) {
sqlSession.commit();
sqlSession.clearCache();
}
}
sqlSession.commit();
sqlSession.clearCache();
return res;
}
}
下面分别对方式三种的三种情况进行测试
3.1 普通插入
/**
* 单条插入
*/
@Test
public void saveByFor() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// 普通插入
userService.saveByFor(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(普通插入方式):" + (end - start) + " ms");
}
 可以看到时间上和使用原生JDBC耗时差不多,约为18.4秒
可以看到时间上和使用原生JDBC耗时差不多,约为18.4秒
3.2 foreach动态拼接插入
/**
* foreach动态拼接插入
*/
@Test
public void saveByForeach() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// foreach动态拼接插入
userService.saveByForeach(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(foreach动态拼接插入方式):" + (end - start) + " ms");
}
运行时报错  原因:
原因:
默认情况下 MySQL 可执行的最大 SQL 语句大小为 4194304 即 4MB,这里使用动态 SQL 拼接后的大小远大于默认值,故报错。
修改: 设置 MySQL 的默认 sql 大小来解决此问题(这里设置为 10MB) 到数据库执行:set global max_allowed_packet=10 * 1024 * 1024;
再次运行  这种方式的优缺点也很明显,优点是耗时还是比较快的,但是缺点很明显,就是无法预知SQL到底有多大,不能总是修改SQL默认的阈值
这种方式的优缺点也很明显,优点是耗时还是比较快的,但是缺点很明显,就是无法预知SQL到底有多大,不能总是修改SQL默认的阈值
3.3 批处理插入
/**
* 批处理插入
*/
@Test
public void saveByBatch() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// 批处理插入
userService.saveByBatch(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(批处理插入方式):" + (end - start) + " ms");
}
 可以看到使用批处理方式耗时仅1.3s,效率还是非常客观的。
可以看到使用批处理方式耗时仅1.3s,效率还是非常客观的。
但是需要注意几个问题:
-
同样需要开启允许重写批量处理提交 rewriteBatchedStatements=true -
代码中需要使用批处理模式,利用 SqlSessionFactory设置批处理模式并获取对应的Mapper接口 -
代码中也进行了分片操作 -
方法中加上 @Transactional注解起到手动提交事务的效果
3.4 mybatisPlus自带的批处理插入
/**
* mybatisPlus自带的批处理插入
*/
@Test
public void saveBatch() {
// 获取 10w 条测试数据
List<User> feeList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// MP 自带的批处理插入
userService.saveBatch(feeList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(mybatisPlus自带的批处理插入):" + (end - start) + " ms");
}
可以看到这种方式虽然比批处理插入方式差一丢丢,但是效率还是比较客观,不过同样需要开启允许重写批量处理提交 rewriteBatchedStatements=true
总结
-
使用 JDBC 推荐使用自己实现批处理方式
-
使用 MyBatis / MyBaits Plus 推荐使用自己实现的批处理方式或 mybatisPlus 自带的批处理方法 记得使用批处理方式进行批量插入一定要带上
rewriteBatchedStatements=true
本文由 mdnice 多平台发布
这篇关于批量插入10w数据方法对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





