本文主要是介绍LPA算法简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 背景
标签传播算法(Label Propagation Algorithm)是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。
2. 算法流程
1. 为每个节点随机的指定一个自己特有的标签;
2. 逐轮刷新所有节点的标签,直到所有节点的标签不再发生变化为止。
对于每一轮刷新,节点标签的刷新规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋值给当前节点。当个数最多的标签不唯一时,随机选择一个标签赋值给当前节点。
在LPA中,节点的标签更新通常有同步更新和异步更新两种方法。
1. 同步更新:节点x在t时刻的更新是基于邻接节点在t-1时刻的标签;
2. 异步更新:节点x在t时刻更新时,其部分邻接节点是t时刻更新的标签,还有部分的邻接节点是t-1时刻更新的标签。
LPA算法在标签传播过程中采用的是同步更新,但同步更新应用在二分结构网络中,容易出现标签震荡的现象。因此,之后大多采用异步更新策略来避免这种现象的出现。
3. 算法原理
3.1 相似矩阵构建
令( x1,y1) … ( xl,yl) 是已标注数据,YL={ y1…yl} ∈{ 1…C} 是类别标签,类别数 C 已知,且均存在于标签数据中。令( xl + 1,yl + 1) …( xl + u,yl + u) 为未标注数据,YU={ yl + 1 … yl + u} 不可观测,l << u,n=l+u。令数据集 X = { x1…xl + u} ∈R。问题转换为: 从数据集 X 中,利用YL的学习,为未标注数据集YU的每个数据找到对应的标签。将所有数据作为节点(包括已标注和未标注数据),创建一个图,这个图的构建方法有很多,这里我们假设这个图是全连接的,节点i和节点j的边权重为:,这里α是超参。
还有个非常常用的图构建方法是knn图,也就是只保留每个节点的k近邻权重,其他的为0,也就是不存在边,因此是稀疏的相似矩阵。
2.2 LPA算法
通过节点之间的边传播 label。边的权重越大,表示两个节点越相似,那么label越容易传播过去。定义一个N x N的概率转移矩阵P:
,
表示从节点 i 转移到节点 j 的概率。
将 YL 和 YU 合并,得到一个N x C的 soft label 矩阵 F=[YL; YU]。
soft label的意思是,保留样本 i 属于每个类别的概率,而不是互斥性的,这个样本以一个概率属于一个类。最后确定这个样本 i 类别时,取概率最大的那个类作为它的类别。
F 里面有个YU,一开始是不知道的,最开始随便设置一个值就可以了。
简单的LP算法如下:
1. 执行传播:F=PF;
2. 重置F中样本的标签:FL=YL;
3. 重复步骤(1)和(2)直到F收敛。
步骤(1)就是将矩阵 P 和矩阵 F 相乘,这一步,每个节点都将自己的 label 以 P 确定的概率传播给其他节点。如果两个节点越相似(在欧式空间中距离越近),那么对方的 label 就越容易被自己的 label 赋予。步骤(2)非常关键,因为 labeled 数据的 label 是事先确定的,它不能被带跑,所以每次传播完,它都得回归它本来的 label。
2.3 变身的LPA算法
每次迭代都是计算一个 soft label 矩阵 F=[YL; YU],但是 YL 是已知的,计算它没有什么用,在步骤(2)的时候,还得把它弄回来。我们关心的只是 YU,那能不能只计算 YU 呢?将矩阵P做以下划分:
令
这时算法就一个运算:
迭代上面这个步骤直到收敛就ok了。可以看到 不但取决于 labeled 数据的标签及其转移概率,还取决了 unlabeled 数据的当前 label 和转移概率。因此 LP 算法能额外运用 unlabeled 数据的分布特点。
2.4 收敛性证明
当n趋近于无穷大是,有

因此

4. 优缺点
4.1 优点
1. 算法逻辑简单,时间复杂度低,接近线性复杂度,在超大规模网络下会有优异的性能,适合做社区发现的baseline;
2. 无须定义优化函数,无须事先指定社区个数,算法会利用自身的网络结构来指导标签传播。
4.2 缺点
1. 雪崩效应:社区结果不稳定,随机性强。由于当邻居节点的社区标签权重相同时,会随机取一个。导致传播初期一个小的错误被不断放大,最终没有得到合适的结果。尤其是异步更新时,更新顺序的不同也会导致最终社区划分结果不同。

上图中展示了一次 LPA 的流程:初始化阶段,每个节点都以自己作为社区标签。比如a的社区就是a,c的社区就是c。当进入传播阶段,节点c的邻居节点共4个:a,b,c,d。而社区标签也是4个:a,b,c,d,假设随机取了一个a。如果是异步更新,此时b,d,e三个节点的邻居节点中社区标签均存在2个a,所以他们都会立马更新成a。如果c当时随机选择的是b,那么d,e就会更新成b,从而导致b社区标签占优,而最终的社区划分也就成b了。
2. 震荡效应:社区结果来回震荡,不收敛,当传播方式处于同步更新的时候,尤其对于二分图或子图存在二分图的结构而言,极易发生。
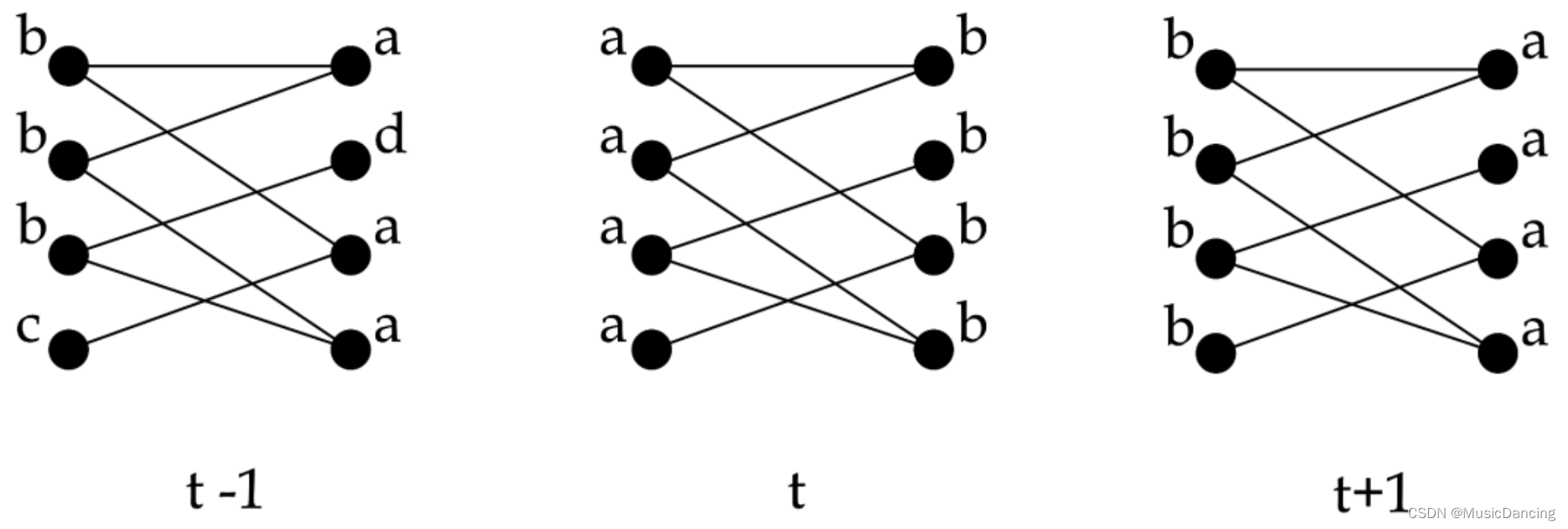
上图中展示了一次二分图中 LPA 的流程,在同步更新的时候,每个节点依赖的都是上一轮迭代的社区标签。当二分图左边都是a,右边都是b时,a社区的节点此时邻居节点都是b,b社区的节点此时邻居节点都是a,根据更新规则,此时a社区的节点将全部更新为b,b社区的节点将全部更新为a。此时算法无法收敛,使得整个网络处于震荡中。
参考:【知识图谱】两种 Python 方法实现社区发现之标签传播算法(LPA)_标签传播算法 python-CSDN博客
这篇关于LPA算法简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









