本文主要是介绍华为WLAN配置——二层互通数据采用隧道转发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

1.接入交换机连通性配置
[SW1]vlan batch 300 to 303
[SW1-GigabitEthernet0/0/1]port link-type access
[SW1-GigabitEthernet0/0/1]port default vlan 300
[SW1-GigabitEthernet0/0/2]port link-type access
[SW1-GigabitEthernet0/0/2]port default vlan 300
[SW1-GigabitEthernet0/0/4]port link-type access
[SW1-GigabitEthernet0/0/4]port default vlan 303
[SW1-GigabitEthernet0/0/3]port link-type trunk
[SW1-GigabitEthernet0/0/3]port trunk allow-pass vlan all
2.汇聚交换机的连通性配置:
[SW2]vlan batch 300 to 303
[SW2-GigabitEthernet0/0/1]port link-type trunk
[SW2-GigabitEthernet0/0/1]port trunk allow-pass vlan all
[SW2-GigabitEthernet0/0/2]port link-type trunk
[SW2-GigabitEthernet0/0/2]port trunk allow-pass vlan all
3.AC的连通性配置:
[AC]vlan batch 300 to 303
[AC-GigabitEthernet0/0/1]port link-type trunk
[AC-GigabitEthernet0/0/1]port trunk allow-pass vlan all
[AC-Vlanif300]ip add 10.1.30.3 24
4.配置汇聚交换机作为网关
[SW2-Vlanif300]ip add 10.1.30.1 24
[SW2-Vlanif301]ip add 10.1.31.1 24
[SW2-Vlanif302]ip add 10.1.32.1 24
[SW2-Vlanif303]ip add 10.1.33.1 24
5.配置汇聚交换机为DHCP服务器
[SW2]dhcp enable
[SW2]ip pool ap-pool
[SW2-ip-pool-ap-pool]gateway-list 10.1.30.1
[SW2-ip-pool-ap-pool]network 10.1.30.0 mask 24
[SW2-ip-pool-ap-pool]dns-list 114.114.114.114
[SW2]ip pool ssid-b-1
[SW2-ip-pool-ssid-b-1]gateway-list 10.1.31.1
[SW2-ip-pool-ssid-b-1]network 10.1.31.0 mask 24
[SW2-ip-pool-ssid-b-1]dns-list 114.114.114.114
[SW2-ip-pool-ssid-b-1]ip pool ssid-b-2
[SW2-ip-pool-ssid-b-2]gateway-list 10.1.32.1
[SW2-ip-pool-ssid-b-2]network 10.1.32.0 mask 24
[SW2-ip-pool-ssid-b-2]dns-list 114.114.114.114
[SW2-ip-pool-ssid-b-2]ip pool vlan303
[SW2-ip-pool-vlan303]gateway-list 10.1.33.1
[SW2-ip-pool-vlan303]network 10.1.33.0 mask 24
[SW2-ip-pool-vlan303]dns-list 114.114.114.114
[SW2-Vlanif300]dhcp select global
[SW2-Vlanif301]dhcp select global
[SW2-Vlanif302]dhcp select global
[SW2-Vlanif303]dhcp select global
6.AP的配置
[AC-wlan-view]ap-group name ap-group1 //创建AP组
[AC]capwap source interface Vlanif 300 //配置与AP通信的源接口
[AC-wlan-view]regulatory-domain-profile name domain1 //创建域管理模板
[AC-wlan-regulate-domain-domain1]country-code CN //配置国家代码
[AC-wlan-view]ap-group name ap-group1 //创建AP组
[AC-wlan-ap-group-ap-group1]regulatory-domain-profile domain1 //绑定域管理模板到AP组
[AC-wlan-view]ap auth-mode mac-auth //配置认证方式
[AC-wlan-view]ap-mac 00e0-fc69-3d90 ap-id 0 //绑定AP1
[AC-wlan-ap-0]ap-name b-1
[AC-wlan-ap-0]ap-group ap-group1 //加入到AP组
[AC-wlan-view]ap-mac 00e0-fc25-80f0 ap-id 1 //绑定AP2
[AC-wlan-ap-1]ap-name b-2
[AC-wlan-ap-1]ap-group ap-group1

7.WLAN业务配置:
[AC-wlan-view]security-profile name security-1 //创建安全模板
[AC-wlan-view]ssid-profile name b-1
[AC-wlan-ssid-prof-b-1]ssid b-1
[AC-wlan-view]ssid-profile name b-2
[AC-wlan-ssid-prof-b-2]ssid b-2
[AC-wlan-view]vap-profile name b-1-vap //创建vap模板
[AC-wlan-vap-prof-b-1-vap]forward-mode tunnel //转发方式选择隧道
[AC-wlan-vap-prof-b-1-vap]service-vlan vlan-id 301 //绑定AP1
[AC-wlan-vap-prof-b-1-vap]security-profile security-1 //选择安全模板
[AC-wlan-vap-prof-b-1-vap]ssid-profile b-1
[AC-wlan-view]vap-profile name b-2-vap
[AC-wlan-vap-prof-b-2-vap]forward-mode tunnel
[AC-wlan-vap-prof-b-2-vap]service-vlan vlan-id 302
[AC-wlan-vap-prof-b-2-vap]security-profile security-1
[AC-wlan-vap-prof-b-2-vap]ssid-profile b-2
[AC-wlan-view]ap-group name ap-group1 //进入AP组
[AC-wlan-ap-group-ap-group1]vap-profile b-1-vap wlan 1 radio all //绑定VAP模板
[AC-wlan-ap-group-ap-group1]vap-profile b-2-vap wlan 2 radio all


8.验证隧道转发
让AP1连接到b-1的channel 1,AP2连接到b-2的channel 149
STA1可以ping通STA2
在STA1上抓包如下:
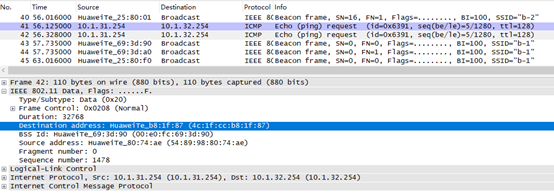
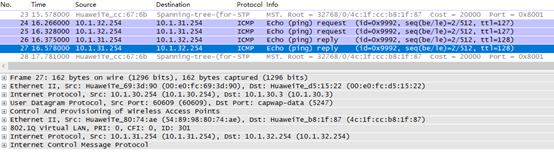
在AP1上抓包如下:验证了隧道封装
这篇关于华为WLAN配置——二层互通数据采用隧道转发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





