本文主要是介绍抓取L4d2地图信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
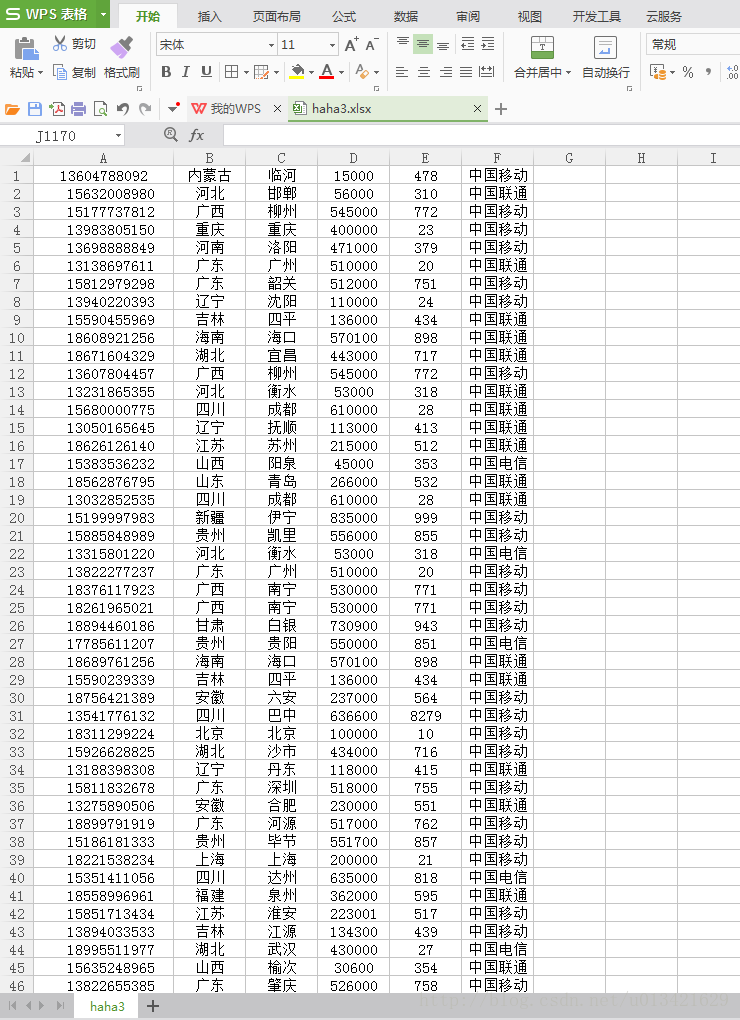
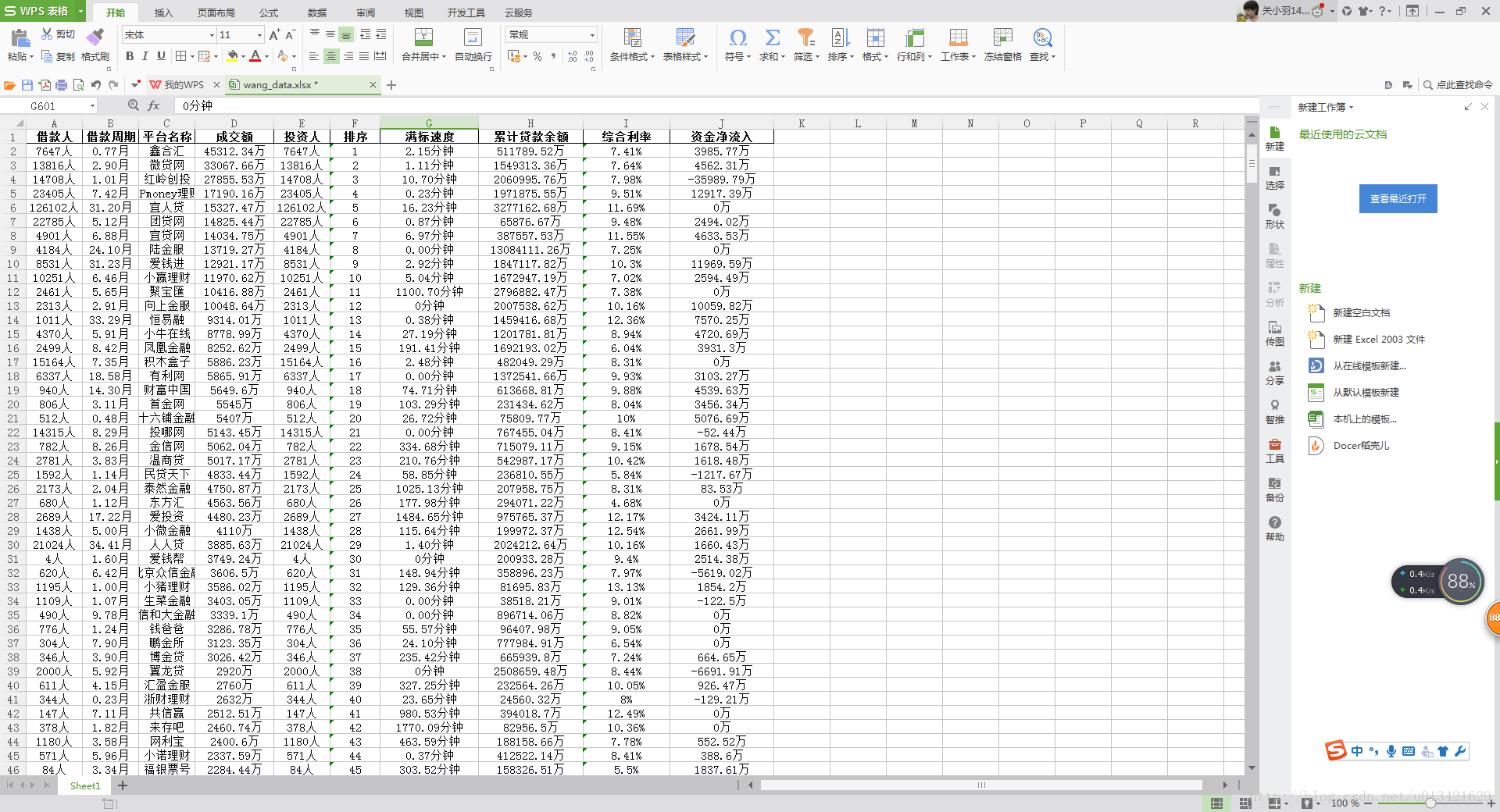
程序用途:从 www.orangetage.com/map/ 获取指定页数的所有地图的信息 储存到txt文件
效果演示
# -*- coding: utf-8 -*-
# Version: Python 3.9.5
# Author: TRIX
# Date: 2021-09-07 21:22:40
# Use: 从http://www.orangetage.com/map/获取指定页数的所有地图的信息 储存到txt文件
from logging import basicConfig,DEBUG,debug,CRITICAL,disable # Import debugging module
#disable(CRITICAL)# Remove # when the program is completed
basicConfig(level=DEBUG, format='%(levelname)s: %(message)s. [%(lineno)d]%(filename)s <%(asctime)s>',filename='debug.log',filemode='w')# Set debugging mode. Replace print() with debug()import requests,bs4
def get_html(page):#获取每页的htmlpages_list=[]#判断页数类型if '-' in page:#如果页数类似 12-32pages_list.extend(page.split('-'))for n in range(int(pages_list[0])+1,int(pages_list[-1])):pages_list.insert(1,n)else:pages_list.append(page)#如果页数类似 15#页数转页面源代码#如果第一页是1 且只有一页if pages_list[0]=='1' and len(pages_list)==1:pages_list[0]=requests.get('http://www.orangetage.com/map/index.html')#如果第一页是1 且不只一页elif pages_list[0]=='1' and len(pages_list)!=1:pages_list[0]=requests.get('http://www.orangetage.com/map/index.html')for i,e in enumerate(pages_list[1:],1):pages_list[i]=requests.get('http://www.orangetage.com/map/{}.html'.format(e))#如果第一页不是1 且只有一页elif pages_list[0]!='1' and len(pages_list)==1:pages_list[0]=requests.get('http://www.orangetage.com/map/{}.html'.format(pages_list[0]))#如果第一页不是1 且不只一页elif pages_list[0]!='1' and len(pages_list)!=1:for i,e in enumerate(pages_list,0):pages_list[i]=requests.get('http://www.orangetage.com/map/{}.html'.format(e))#设置编码格式for i,n in enumerate(pages_list):#print(pages_list[i].apparent_encoding)#网页编码格式 得知是gbkpages_list[i].encoding='gbk'#设置编码为gbkpages_list[i]=pages_list[i].textreturn pages_listdef get_map(page):#寻找地图pages_list=get_html(page)#debug(len(pages_list))#记录调试日志map_url_list=[]#寻找页面里的地图urlfor i,n in enumerate(pages_list):pages_list[i]=bs4.BeautifulSoup(n,'lxml').select('div[class="list_img"] > a')#处理html 寻找 <div class="list_img"> 里的 <a>for x,url_tag in enumerate(pages_list[i]):map_url_list.append(url_tag.get('href'))#寻找 <a> 里的 url#debug(pages_list)page_count=1map_count=1map_list=['' for map_i,n in enumerate(map_url_list)]#地图所有相关信息 组成列表#寻找地图页面里的地图信息 和 下载地址for map_i,n in enumerate(map_url_list):map_url_list[map_i]=requests.get(n)map_url_list[map_i].encoding='gbk'map_url_list[map_i]=map_url_list[map_i].text#获得地图htmlmap_list[map_i]+='------第{}页-第{}个地图------\n'.format(page_count,map_count)map_count+=1if map_count==9:map_count=1page_count+=1#获取地图信息map_info_list=bs4.BeautifulSoup(map_url_list[map_i],'lxml').select('span[style="font-family:微软雅黑;"]')#寻找 <span style="font-family:微软雅黑;"> 里的地图信息if len(map_info_list)!=1:map_list[map_i]+='地图简介:'for info_i,info_tag in enumerate(map_info_list):map_info_list[info_i]=info_tag.text.replace('\r\n','\n')#处理地图信息map_list[map_i]+=map_info_list[info_i]+'\n'#获取地图下载地址map_link_list=bs4.BeautifulSoup(map_url_list[map_i],'lxml').select('ul[class="l xz_a wrap blue"] > li > a')#寻找 <ul class="l xz_a wrap blue"> 里的 <li> 里的 <a>#debug(map_link_list)for link_i,url_tag in enumerate(map_link_list):map_list[map_i]+=url_tag.text+':'map_list[map_i]+=url_tag.get('href')+'\n'#添加下载地址到map_list对应元素map_list[map_i]+='\n\n'with open('l4d2_maps_info.txt','w',encoding='utf-8') as f:#写入txtf.write('在第{}页一共找到{}个地图\n\n\n'.format(page,len(map_url_list)))for map_i,n in enumerate(map_url_list):f.write(map_list[map_i])get_map('18-25')这篇关于抓取L4d2地图信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!