本文主要是介绍Mxnet (16): 并行网络(GoogLeNet),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GoogLeNet吸收了NiN中网络串联网络的思想,并在此基础上做了很大改进。以前的网络中对kernel_size的选取1~11都有,GoogLeNet的见解是多种大小的内核一起使用可能会有利,有点选举的赶脚
1.Inception 块
GoogLeNet中的基础卷积块叫作Inception块,得名于同名电影《盗梦空间》(Inception)。与NiN块相比,这个基础块在结构上更加复杂
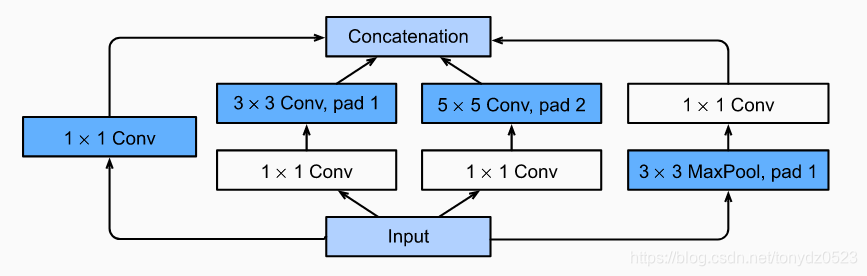
其实由四个并行路线组成:
- 1×1 卷积
- 3×3 卷积 + 1×1 卷积
- 5×5 卷积 + 1×1 卷积
- 3×3 最大池化层 + 1×1 卷积
4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
Inception块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
class Inception(nn.Block):# c1 ~ c4 为各自层的通道数def __init__(self, c1, c2, c3, c4, **kwargs):super(Inception, self).__init__(**kwargs)# Path 1 单1 x 1卷积层self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu')# Path 2 1 x 1卷积层后接3 x 3卷积层self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu')self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1,activation='relu')# Path 3 1 x 1卷积层后接5 x 5卷积层self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu')self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2,activation='relu')# Path 4 3 x 3最大池化层后接1 x 1卷积层self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1)self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu')def forward(self, x):p1 = self.p1_1(x)p2 = self.p2_2(self.p2_1(x))p3 = self.p3_2(self.p3_1(x))p4 = self.p4_2(self.p4_1(x))# 在通道纬度上进行连接输出return np.concatenate((p1, p2, p3, p4), axis=1)
2GoogLeNet模型
GoogLeNet使用总共9个初始块和全局平均池的堆栈来生成其估计值。初始块之间的最大池化会降低维数。第一个模块类似于AlexNet和LeNet。块的堆栈是从VGG继承的,并且全局平均池避免了最后使用完全连接的层的堆栈。

- 第一模块使用一个64通道的 7 × 7 7×7 7×7 卷积层。
b1 = nn.Sequential()
b1.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3, activation='relu'),nn.MaxPool2D(pool_size=3, strides=2, padding=1))
- 第二模块使用2个卷积层:首先是64通道的 1×1 卷积层,然后是将通道增大3倍的 3×3 卷积层。它对应Inception块中的第二条线路。
b2 = nn.Sequential()
b2.add(nn.Conv2D(64, kernel_size=1, activation='relu'),nn.Conv2D(192这篇关于Mxnet (16): 并行网络(GoogLeNet)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








