本文主要是介绍【论文速读】| 大语言模型是边缘情况模糊测试器:通过FuzzGPT测试深度学习库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本次分享论文为:Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT
基本信息
原文作者:Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, Lingming Zhang
作者单位:伊利诺伊大学厄巴纳-香槟分校
关键词:模糊测试、深度学习库、大语言模型、程序合成
原文链接:
https://arxiv.org/abs/2304.02014v1
开源代码:暂无
论文要点
论文简介:这篇论文提出了一种名为FuzzGPT的新方法,它利用大语言模型(LLMs)生成非常规程序来测试深度学习(DL)库。通过对历史中引发错误的程序的研究,FuzzGPT能够生成更有效的测试程序,检测出多达76个错误,其中49个被确认为新的错误,包括11个高优先级错误或安全漏洞。
研究目的:为了解决传统fuzzing技术在自动生成有效测试程序方面存在的挑战,本文通过整合大语言模型的生成能力,提出了一个新颖的方法来增强软件测试的效率和覆盖范围,尤其是针对复杂的深度学习库。
研究贡献:
1.本文首次提出利用大语言模型(LLMs)生成异常输入程序以提高模糊测试的有效性。FuzzGPT作为一种新型的自动化模糊测试工具,能够根据历史错误触发程序或直接遵循人类指令生成不寻常的测试程序,适用于多种应用领域。
2.研究者们实现了FuzzGPT的三种变体:少样本学习、零样本学习和微调,基于Codex和CodeGen等先进的GPT风格模型,并特别开发了直接利用ChatGPT指令跟随能力的零样本变体。
3.通过在PyTorch和TensorFlow两个深度学习库上的广泛测试,FuzzGPT在提高代码覆盖率方面显著优于现有的TitanFuzz工具,并成功发现了49个新错误,包括多个高优先级的安全漏洞。
引言
深度学习(DL)已在多个领域得到广泛应用。然而,由于这些应用依赖于复杂的DL库,库中的错误可能会导致严重后果,包括对安全关键应用的影响。尽管传统Fuzzing方法很有力,但在生成适用于DL库的输入程序时,它面临多个挑战。这些程序不仅需要符合编程语言的语法和语义,还必须满足构建有效计算图的张量和操作符约束。TitanFuzz是一个先前的尝试,它通过利用预训练的大语言模型来生成有效的DL程序。然而,这些模型通常只生成常规程序,不足以探索库的边缘行为。与此相对,FuzzGPT引入了一种新策略,通过对大语言模型(LLMs)进行“微调”和“上下文学习”,生成更多的异常程序,以探索DL库中未覆盖的路径。
研究背景
在开发深度学习(DL)应用时,常用的库如PyTorch和TensorFlow功能虽强大,但仍存在许多潜在错误。针对这些库的fuzzing研究通常集中在模型级和API级。然而,现有方法,无论是复用和变异现有种子模型,还是依赖手动编写的规范,均仅能覆盖有限的API和程序模式。为此,FuzzGPT被提出以通过自动化技术生成更多样化的输入程序,从而提升Fuzzing的效果和效率。
研究方法
FuzzGPT 通过结合大语言模型(LLM)的能力和历史错误触发程序的数据集,创新地生成能够发现新缺陷的非常规测试程序。首先,从开源软件库中收集和分析已知的错误触发程序,以构建一个训练数据集。然后,使用这些数据对LLM进行微调和上下文学习,以增强其生成异常测试输入的能力。通过这种方式,FuzzGPT不仅学习了编程语言的语法和语义,还学习了深度学习计算图的构建约束,从而有效地提高了软件测试的覆盖率和效率。此外,该方法还特别强调了在生成过程中利用历史错误数据的重要性,以更好地捕捉可能的错误触发模式。
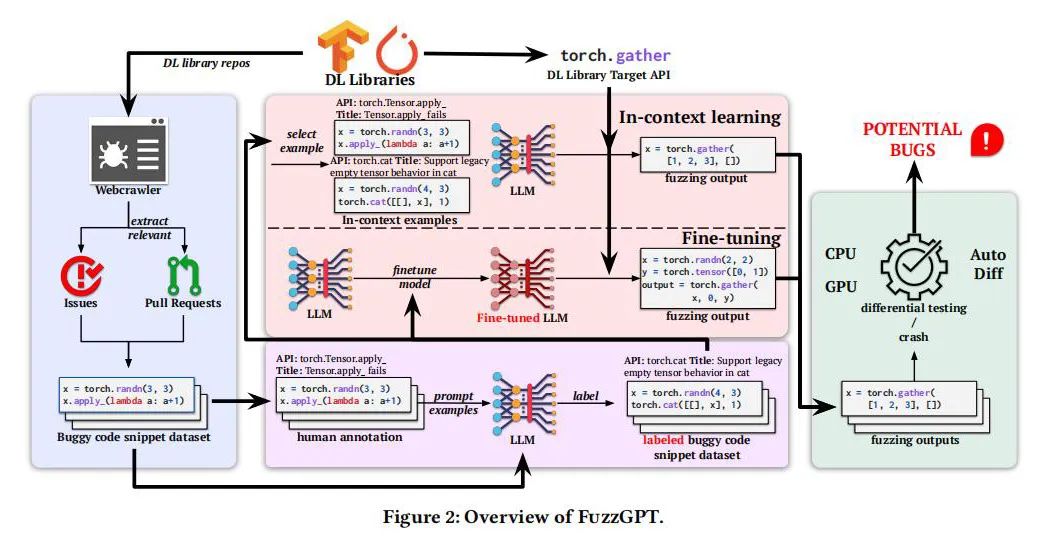
实现方法
FuzzGPT是基于大语言模型(LLM),如GPT和Codex,利用这些模型学习历史错误触发代码片段来自动化生成测试代码的工具。首先,从开源项目中抓取bug报告和错误代码,以建立包含错误触发代码的数据集。然后,采用微调(Fine-tuning)和上下文学习(In-context Learning)方法来调整LLM,从而使其能够生成可能触发深度学习库潜在错误的代码。在微调过程中,通过梯度下降法调整模型参数,以最大化预测错误触发代码的准确性。上下文学习则是通过分析历史错误示例来优化生成逻辑,无需更改模型权重。这两种策略共同增强了模型在寻找新bug方面的实际应用能力。
研究评估
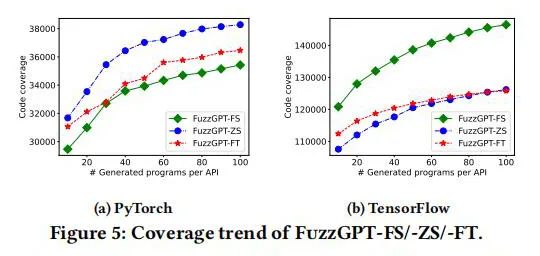
在实际测试中,FuzzGPT对两个流行的深度学习库PyTorch和TensorFlow进行了广泛评估。与现有模糊测试技术TitanFuzz相比,FuzzGPT在测试覆盖率和错误检测方面都表现出显著优势。FuzzGPT成功识别了总共76个错误,其中49个是之前未被发现的新错误,包括11个高优先级错误或安全漏洞。此外,FuzzGPT利用从大语言模型生成的测试输入,在PyTorch和TensorFlow中实现了比TitanFuzz更高的代码覆盖率。这些结果有效证实了FuzzGPT结合历史错误数据和大语言模型策略在提升软件质量和安全性方面的实用性和效率。
结果分析
FuzzGPT的测试结果不仅证实了其在深度学习库模糊测试中的有效性,还展示了其优越性。通过对两个主流深度学习库——PyTorch和TensorFlow——的广泛测试,FuzzGPT在错误检测和测试覆盖率方面均优于现有技术。它成功检测了76个错误,其中49个是新发现的,包括11个高优先级错误或安全漏洞。相比于TitanFuzz等传统模糊测试工具,FuzzGPT在发现新代码路径和触发边缘案例方面表现更为卓越。这些成果突显了FuzzGPT结合大语言模型和历史错误数据进行模糊测试的独特优势,有效地提高了深度学习库的测试深度和广度。
论文结论
通过整合大语言模型和历史错误触发程序,FuzzGPT在深度学习库的模糊测试领域显著提升了效能。这项研究不仅揭示了多个之前未识别的错误,包括关键的安全漏洞,而且还显著提高了代码覆盖率,从而证明了其在探测深度学习库潜在缺陷的有效性。此外,FuzzGPT展示了大语言模型在自动生成高风险测试输入方面的巨大潜力,为该领域的未来研究和实践提供了新的方向和方法,特别是在提升软件测试的自动化和智能化水平方面。
原作者:论文解读智能体
润色:Fancy
校对:小椰风

这篇关于【论文速读】| 大语言模型是边缘情况模糊测试器:通过FuzzGPT测试深度学习库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



