本文主要是介绍女上司问我:误删除PG百万条数据,可以闪回吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者:IT邦德
中国DBA联盟(ACDU)成员,10余年DBA工作经验
擅长主流数据Oracle、MySQL、PG、openGauss运维
备份恢复,安装迁移,性能优化、故障应急处理等可提供技术业务:
1.DB故障处理/疑难杂症远程支援
2.Mysql/PG/Oracle/openGauss
数据库部署及数仓搭建•••
微信:jem_db
QQ交流群:587159446
公众号:IT邦德
文章目录
- 前言
- 📣 1.闪回查询
- ✨ 1.1 概述
- ✨ 1.2 flashback前提
- 📣 2.pg_dirtyread插件
- 📣 3.安装插件pg_dirtyread
- ✨ 3.1 授权解压
- ✨ 3.2 编译和安装
- ✨ 3.3 安装插件
- 📣 4.安装插件pageinspect
- 📣 5.闪回案例
- ✨ 5.1删除找回
- ✨ 5.2 drop列恢复
- ✨ 5.3 基于时间点闪回
- 📣 6.总结
前言
闪回查询(Flashback Query)是一种在数据库中执行时间点查询的技术。
📣 1.闪回查询
✨ 1.1 概述
闪回查询(Flashback Query)是一种在数据库中执行时间点查询的技术。它允许查询数据库中过去某个时间点的数据状态,并返回相应的查询结果。通常闪回查询分为表级以及行级的闪回查询。PostgreSQL数据库由于MVCC的机制,对于DML的操作,更改或者删除的元祖暂时标记为死元祖并未真正的在物理上清理,直到vacuum运行时才清理这些死元祖,这为行级的闪回查询提供了可能。
✨ 1.2 flashback前提
1.延迟VACUUM,确保误操作的数据还没有被垃圾回收。
vacuum_defer_cleanup_age = 5000000
–延迟500万个事务再回收垃圾,
误操作后在500万个事务内,
如果发现了误操作,才有可能使用本文提到的方法闪回。
2.记录未被freeze,确保无操作的数据,
以及后面提交的事务号没有被freeze(抹去)。
vacuum_freeze_min_age = 50000000
–事务年龄大于5000万时,才可能被抹去事务号。
3、开启事务提交时间跟踪,确保可以从xid得到事务结束的时间
track_commit_timestamp = on
–开启事务结束时间跟踪,开启事务结束时间跟踪后,
会开辟一块共享内存区存储这个信息。
📣 2.pg_dirtyread插件
pg_dirtyread是PostgreSQL数据库的一个扩展插件。当在PG执行了误操作SQL(如UPDATE或DELETE) 后,它可以从表中读取未被vacuum的死元祖,可用于查看意外删除或更改的受损数据,达到类似“闪回查询”的功能。pg_dirtyread基于MVCC多版本机制,通过检索查询旧版本,获取指定老版本数据,实现行级的数据还原。
📣 3.安装插件pg_dirtyread
pg_dirtyread 不存在于 contrib 目录下,
因此需要单独编译
GitHub地址:https://github.com/df7cb/pg_dirtyread

安装包:pg_dirtyread-2.6.tar.gz
https://github.com/df7cb/pg_dirtyread/archive/refs/tags/2.6.tar.gz
✨ 3.1 授权解压
cp /opt/pg_dirtyread-2.6.tar.gz /home/postgres/
chown postgres:postgres /home/postgres/pg_dirtyread-2.6.tar.gz
su - postgres
tar -xzvf pg_dirtyread-2.6.tar.gz
cd pg_dirtyread-2.6
✨ 3.2 编译和安装
[postgres@centos79 pg_dirtyread-2.6]$ make
[postgres@centos79 pg_dirtyread-2.6]$ make install

✨ 3.3 安装插件
postgres=# CREATE EXTENSION pg_dirtyread;
postgres=# select * from pg_available_extensions;

📣 4.安装插件pageinspect
pageinspect模块提供函数让你从低层次观察数据库页面的内容,这对于调试目的很有用。所有这些函数只能被超级用户使用。
pageinspect的源码在postgres源码包的contrib目录下,解压postgre源码包后进入对应的目录。
[root@centos79 ~]# find / -name contrib
/pgccc/soft/postgresql-15.6/contrib
/usr/share/git-core/contrib
/usr/share/doc/git-1.8.3.1/contrib
/home/postgres/pg_dirtyread-2.6/contrib
cd /pgccc/soft/postgresql-15.6/contrib/pageinspect/
make && make install

postgres=# create extension pageinspect;
postgres=# select * from pg_available_extensions;

📣 5.闪回案例
✨ 5.1删除找回
-创建测试表CREATE TABLE foo (bar bigint, baz text); -- 测试方便,先把自动vacuum关闭掉。ALTER TABLE foo SET (autovacuum_enabled = false, toast.autovacuum_enabled = false);--插入数据INSERT INTO foo VALUES (1, 'Test'), (2, 'New Test'); --删除所有数据DELETE FROM foo; postgres=# select * from foo;postgres=# SELECT * FROM pg_dirtyread('foo') as t(bar bigint, baz text);

✨ 5.2 drop列恢复
CREATE TABLE ab(a text, b text); INSERT INTO ab VALUES ('Hello', 'World'); ALTER TABLE ab DROP COLUMN b; DELETE FROM ab; postgres=# select * from ab;postgres=# SELECT * FROM pg_dirtyread('ab') ab(a text, dropped_2 text);a | dropped_2-------+-----------Hello | World(1 row)可以看到,虽然b列被drop掉了,但是仍然可以读取到数据。如何指定列:这里使用dropped_N来访问第N列,从1开始计数。局限:由于PG删除了原始列的元数据信息,因此需要在表列名中指定正确的类型,这样才能进行少量的完整性检查。包括类型长度、类型对齐、类型修饰符,并且采取的是按值传递。

✨ 5.3 基于时间点闪回
pg_xact_commit_timestamp函数:查询事务提交时间
如果只想恢复到其中的某一个时间点的数据,首先需要通过系统函数 pg_xact_commit_timestamp,得到每个元祖写入事务的提交时间(xmin)以及删除/更新事务提交时间(xmax)。加以处理后,进而实现基于时间点的闪回查询。
–设置参数
track_commit_timestamp = on
–模拟数据
create table bak (id int,info text);
insert into bak values(1,‘aaa’),(2,‘bbb’),(3,‘ccc’);
delete from bak;
–通过事务提交时间,查询数据历史版本
select pg_xact_commit_timestamp(xmin) as xmin_time,
pg_xact_commit_timestamp(case xmax when 0 then null else xmax end) as xmax_time,*
from pg_dirtyread(‘bak’) as t(tableoid oid,ctid tid,xmin xid,xmax xid,cmin cid,
cmax cid,id int,info text);

根据xmin_time,xmax_time,我们可以查看每个元祖的历史版本操作,何时插入以及何时进行更新/删除的。
闪回查询某个时间点的数据
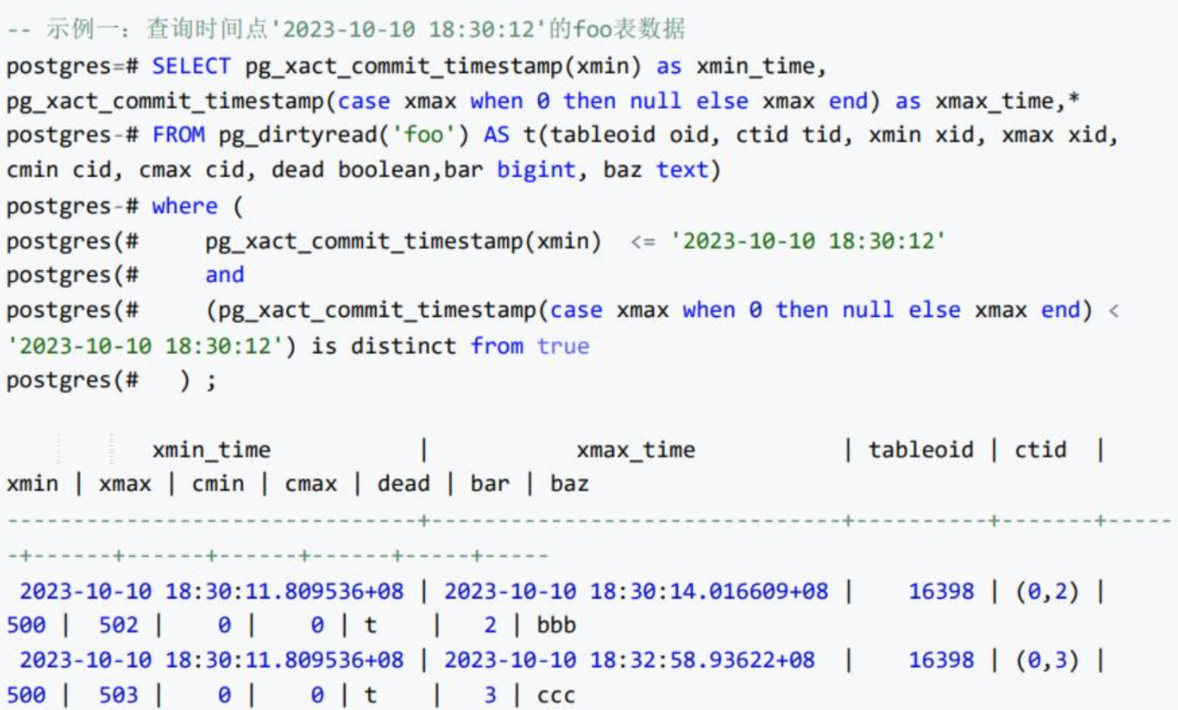
根据事务提交顺序,逆序,逐个事务排除,逐个事务回退,其语法为:

1、$ts表示要查询某个表在ts这个时间点上的数据,
ts指一个具体的历史时间。
2、A is distinct from B:
表示排除A表达式与B表达式相匹配的行。
📣 6.总结
PostgreSQL数据库由于MVCC的机制,对于DML的操作,更改或者删除的元祖暂时标记为死元祖并未真正的在物理上清理,直到vacuum运行时才清理这些死元祖,这为行级的闪回查询提供了可能。
这篇关于女上司问我:误删除PG百万条数据,可以闪回吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





