本文主要是介绍第五章,数据可视化-ggplot2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
虽然,目前有很多工具可以用来进行数据分析,但是R语言在数据可视化上的优势基本无它能敌。其中最具盛名的包就是Hadly Wickham开发的ggplot2包。
正文
一,快速探索数据-从qplot开始
R中查看函数文档信息
require(ggplot2)
help("qplot")qplot(x, y, ..., data, facets = NULL, margins = FALSE, geom = "auto", xlim = c(NA, NA), ylim = c(NA, NA), log = ",
main = NULL, xlab = NULL, ylab = NULL, asp = NA, stat = NULL, position = NULL)



二,图层语法中,图的结构表述

(一),数据和映射
1,ggplot创建图形对象
p = ggplot(data=diamonds, aes(x= carat,y= price, color= cut))
p是第一层图层语法模型中的第一层,其中data参数,控制数据来源,只能是数据框格式,aes参数,控制了对哪些变量进行图形映射,以及映射方式;aes中的属性包括,color,shape,fill 等等
p = ggplot(mtcars, aes(x= mpg,,y= wt))
p + geom_point()
# geom_point() 第二图层告诉了ggplot2要绘制散点图

⚠️aes中的属性映射,如果变量是分类变量,为了防止被当做数值型,一般用factor处理一下,比如 aes(… ,…, color = factor(a))
# 此处,因为factor的处理,cyl被当做分类属性值
p+geom_point(aes(color=factor(cyl)))


2,几个对象
分组 aes(…, group ),默认group=1,表示所有离散变量的交互作用,来控制哪些观测值用于哪些图形元素。
几何对象大致可分为两类,由group来控制,当没有离线变量等情况时,继续用自定义设置group结构。

例1,
当x,y 里面的值没有离散变量时,需要设定group
library(“nlme”) #用到这包里面的数据Oxboyshead(Oxboys)ggplot(Oxboys,aes(age,height))+geom_point()
图中数据,表示了每个样本对象Subject,对应的年龄、身高情况的散点图,属于个体集合对象。

当把他们变成线图时,问题就出来了。 由于没有设置group,被认为是群体几个对象,画出来的是乱的线图。
ggplot(Oxboys,aes(age,height))+geom_line()

设定group后,ggplot就知道,每个subject的所有数据映射到一个图形对象
ggplot(Oxboys,aes(age,height,group=Subject))+geom_line()

(二),添加图层
创建图层是用下面的layer函数实现的
layer(geom = NULL, stat = NULL, data = NULL, mapping = NULL,position = NULL, params = list(), inherit.aes = TRUE,check.aes = TRUE, check.param = TRUE, show.legend = NA)
但是实际中,我们会用到快捷函数geom_* 或 stat_* 来实现。
图层之间是用加号’+’连接的。
1,创建几何对象
每一个几何对象都有一个默认的的统计变换,当然统计变换可以自己设定更改。
下图举个例子,更多几何对象,参考ggplot2。

2,统计变换
因为geom_*(aes(stat= ‘’ ))都会给定一个默认的统计变换,如上表。所以,一般不会需要更改,除非需要自定义图形的时候。
3,位置调整
位置调整一般多见于离散数据的重叠,连续数据很少需要微调。
五种位置position的参数如下

更详细的设置需要结合下面的函数,调整参数实现:

# 堆叠图像宽度不一致的情况
ggplot(mtcars, aes(factor(cyl), fill = factor(vs))) +geom_bar(position = 'dodge’)

# 通过详细的设置来调整
ggplot(mtcars, aes(factor(cyl), fill = factor(vs))) +
+ geom_bar(position = position_dodge2(preserve = "single"))
(三), 标尺/标度 scale
前面我们已经看到了,画图就是在做映射,不管是映射到不同的几何对象上,还是映射各种图形属性。这一小节介绍标尺,在对图形属性进行映射之后,使用标尺可以控制这些属性的显示方式,比如坐标刻度,可能通过标尺,将坐标进行对数变换;比如颜色属性,也可以通过标尺,进行改变.
可以看到标尺设置的内容有8种(颜色color/colour算一种):
- 透明度alpha
- 线条颜色color
- 填充色fill
- 线型linetype
- 形状shape
- 大小size
- x轴
- y轴
(标尺设置的内容都有对应的映射设置类型,但映射比标尺多了xmin, xmax, ymin, ymax, xend, yend,group和string等)
每一种标尺的设置都形如scale_*,具体参见ggplot2中的说明,下面举个例子:
(1) 连续型颜色标尺
ggplot2提供了十多个填充色设置的标尺函数参见上表
先看看“continuous”的用法。对于数据为非因子型的填充色映射,ggplot2自动使用“continuous”类型颜色标尺表示连续颜色空间。如果要修改默认颜色就要使用scale_fill_continuous函数进行修改,这个函数最有用的参数是low和high,分别表示低端和高端数据的颜色,中间颜色根据颜色空间space自动计算:
p + geom_raster() +
scale_fill_continuous(low="darkgreen", high="orangered", space='rgb')

(2)离散(间断)型颜色标尺
scale_color_discrete或scale_color_hue设置颜色不是很直观,如果想要啥来啥,那就用manual类型函数:
p + geom_point() +
scale_color_manual(values=c('blue','cyan', 'yellow', 'orange', 'red'))

(3)坐标轴尺度
两种方式,比如
- 通过 scale_y_log10() 将Y轴坐标进行log10变换
- 或自己有限进行数据变换将Y’ = log10(Y), 再画出 Y’ 与 X之间的关系
(4)颜色
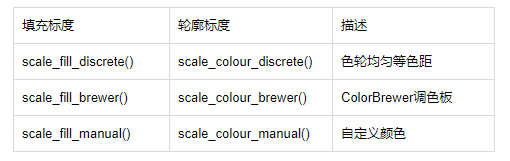
(四), 坐标系统 coordinate
坐标系统控制坐标轴,可以进行变换,例如XY轴翻转,笛卡尔坐标和极坐标转换,以满足我们的各种需求。


(五), 分面 facet
分面有两种方式来实现:
(1) 缠绕分面 facet_wrap
facet_warp 即“缠绕分面”,对数据分类只能应用一个标准,不同组数据获得的图形按从左到右从上到下的“缠绕”顺序进行排列
facet_wrap(facets, nrow = NULL, ncol = NULL, scales = “fixed”, shrink = TRUE, as.table = TRUE, drop = TRUE)
- facets:分面参数如 ~cut,表示用 cut 变量进行数据分类
- nrow:绘制图形的行数
- ncol:绘制图形的列数,一般nrow/ncol只设定一个即可
- scales:坐标刻度的范围,可以设定四种类型。fixed 表示所有小图均使用统一坐标范围; free表示每个小图按照各自数据范围自由调整坐标刻度范围;free_x为自由调整x轴刻度范围;free_y为自由调整y轴刻度范围。
- shrinks:也和坐标轴刻度有关,如果为TRUE(默认值)则按统计后的数据调整刻度范围,否则按统计前的数据设定坐标。
- as.table:和小图排列顺序有关的选项。如果为TRUE(默认)则按表格方式排列,即最大值(指分组level值)排在表格最后即右下角,否则排在左上角。
- drop:是否丢弃没有数据的分组,如果为TRUE(默认),则空数据组不绘图。
# 分面可以让我们按照某种给定的条件,对数据进行分组,然后分别画图。
ggplot(small, aes(x=carat, y=price))
+geom_point(aes(colour=cut))
+scale_y_log10()
+facet_wrap(~cut,scales="fixed")+stat_smooth()

(2) 网格分面 facet_grid
facet_grid(facets, margins = FALSE, scales = “fixed”, space = “fixed”, shrink = TRUE, labeller = “label_value”, as.table = TRUE, drop = TRUE)
和facet_wrap比较,除不用设置ncol和nrow外(facets公式已经包含)外还有几个参数不同:
-
必须拥有相同的X值与Y值
- margins :相当于是否添加行、列的汇总图;
- space :这个参数要配合scales使用,如果为fixed(默认),所有小图的大小都一样,如果为free/free_x/free_y,小图的大小将按照坐标轴的跨度比例进行设置。
- labeller :设定小图标签的
p <- ggplot(mpg, aes(displ, cty)) + geom_point()
p + facet_grid(. ~ cyl) # 一行多列
p + facet_grid(drv ~ .) #一列多行
p + facet_grid(drv ~ cyl) #多行多列
(六), 主题 theme
ggthemes包提供了一些主题可供使用
library(ggthemes)
p+theme_wsj()
此外,ggplot2默认也提供了很多的主题属性,可以自行调整,例子如下:
(1) 去掉y轴的刻度标签
p+theme(axis.text.y = element_blank())
若同时,去掉y轴的刻度线
p+theme(axis.ticks = element_blank(), axis.text.y = element_blank())
(2) 将刻度标签文本旋转
例,旋转30度
p+theme(axis.text.x = element_text(angle=30,hjust=1,vjust=1))
同时,用element_text()还可以设置刻度标签文本的大小、样式、字体等属性:
p+theme(axis.text.x = element_text(
family=“Times”, face=“italic” , colour=“darked” , “size”=rel(0.9)))
(3)element_text()
family:Helvetica 无衬线,Times 有衬线 Courier 等宽;
face:plain普通,bold粗体,italic斜体,bold.italic粗斜体
size:单位磅
lineheight:行间距倍数
…
(4)margin()
theme中边框距离,图片与边框之间的距离
margin(t = 0, r = 0, b = 0, l = 0, unit = “pt”)
设置的顺序是上、右、下、左
ggplot(…) + theme(plot.margin = margin(2,2,2,2,"cm”))
(七)I/O
ggplot2的输出有两种形式:矢量型,光栅型(像素矩阵)
ggsave()
(八)其他
(1)【手动匹配形状】
ggplot2 中对应的shape palette最多只有6个,也就是说如果想把第7个及以上的分类匹配不同的形状时,需要手动匹配
假设一个数据集 data由product/reason/count三个维度构成,因为product是a~g七个
运行下列code时
ggplot(data,aes(x=reason,y=count))
+geom_point(aes(colour=product,size=10,shape=product))
就会发现product=g的图形,在图中是空的:

此时需要手动匹配图形:
根据product=='g’定位对应点的坐标值:
ggplot(da,aes(x=reason,y=count))
+geom_point(aes(colour=product,size=10,shape=product))
+geom_point(aes(reason[product=='g'],count[product=='g']),colour='black',shape=11,size=5)
ggplot2中的shape有下面25种类型(R语言原生的绘图类型共255种,包括字母数字等内容)

(2)【一页多图】
此处内容转载丹追兵的文章
library(grid) # 用grid包完成布局
核心为 viewport() 函数
参数如下:
- x:绘图区域相对页面左下角原点的x坐标,默认单位为npc,Normalised Parent Coordinates,含义是归一化的父区域坐标
- y:绘图区域相对页面左下角原点的y坐标
- width:绘图区域的宽度(x轴方向)
- height:绘图区域的高度(y轴方向)
- just:x和y所指的位置,默认为矩形中心位置
- angle:将绘图区域旋转多少度
- name:此viewport的名字,用于搜索和定位
例子1:
grid.show.viewport(viewport(x=0.6, y=0.6, width=unit(1, "inches"), height=unit(1, "inches"), angle=30))

一,用调用 viewport() 与 print.ggplot()
print( ggplot对象, vp = ) 函数中,可以设置vp(viewport)选项,来指定画图的位置。
require(ggplot2)
library(grid)# 生成三个ggplot对象
p.hist.len <- ggplot(iris) + geom_histogram(aes(x=Sepal.Length))
p.hist.wid <- ggplot(iris) + geom_histogram(aes(x=Sepal.Width)) + coord_flip()
p.scatter <- ggplot(iris) + geom_point(aes(x=Sepal.Length, y=Sepal.Width))# 创建三个不同的vp位置
grid.newpage()
vp.len <- viewport(x=0, y=0.66, width=0.66, height=0.34, just=c("left", "bottom"))
vp.wid <- viewport(x=0.66, y=0, width=0.34, height=0.66, just=c("left", "bottom"))
vp.scatter <- viewport(x=0, y=0, width=0.66, height=0.66, just=c("left", "bottom"))# 运用vp, 画出指定的位置的ggplot对象
print(p.hist.len, vp=vp.len)
print(p.hist.wid, vp=vp.wid)
print(p.scatter, vp=vp.scatter)

二,更复杂图像用矩形网格布局
grid.layout(nrow = 1, ncol = 1,widths = unit(rep_len(1, ncol), "null"),heights = unit(rep_len(1, nrow), "null"),default.units = "null", respect = FALSE,just="centre")
例子:# 新建画布
grid.newpage()# 创建矩形网格布局,pushviewport函数把布局插入到根节点
pushViewport(viewport(layout = grid.layout(2,2))) # 自定义布局分配函数
vplayout <- function(x,y)viewport(layout.pos.row = x,layout.pos.col = y)# 三个图形
a = qplot(date,unemploy, data = economics, geom = 'line',fill='red')
b = qplot(uempmed,unemploy, data = economics)
c = qplot(uempmed,unemploy, data = economics,geom = 'path')# 画图
print(a,vp = vplayout(1,1:2))
print(c,vp = vplayout(2,1))
print(b,vp = vplayout(2,2))

这篇关于第五章,数据可视化-ggplot2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





