本文主要是介绍爬虫的各位看过来,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近无意中找到了一个很牛逼的网站,可以把网站的那些请求头拿到,这大大节省了我们找header的时间,那我们了看看这个网站以及看看如何使用它吧!
网址:https://curl.trillworks.com/
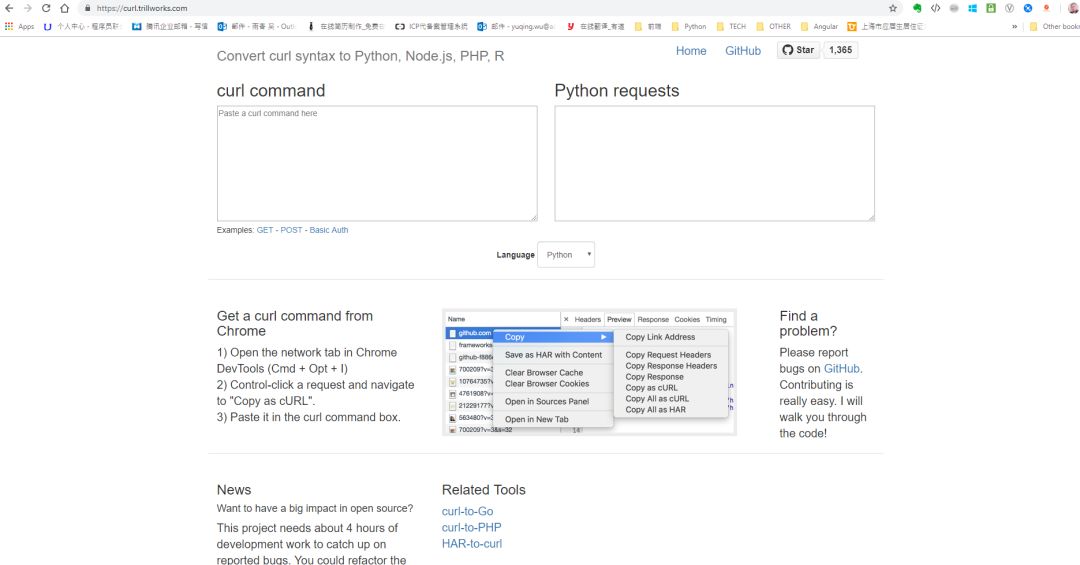
打开网址是这样的一个页面。在页面上有使用教程
Get a curl command from Chrome
1) Open the network tab in Chrome DevTools (Cmd + Opt + I)
2) Control-click a request and navigate to "Copy as cURL".
3) Paste it in the curl command box.
我们用豆瓣电影来试试:
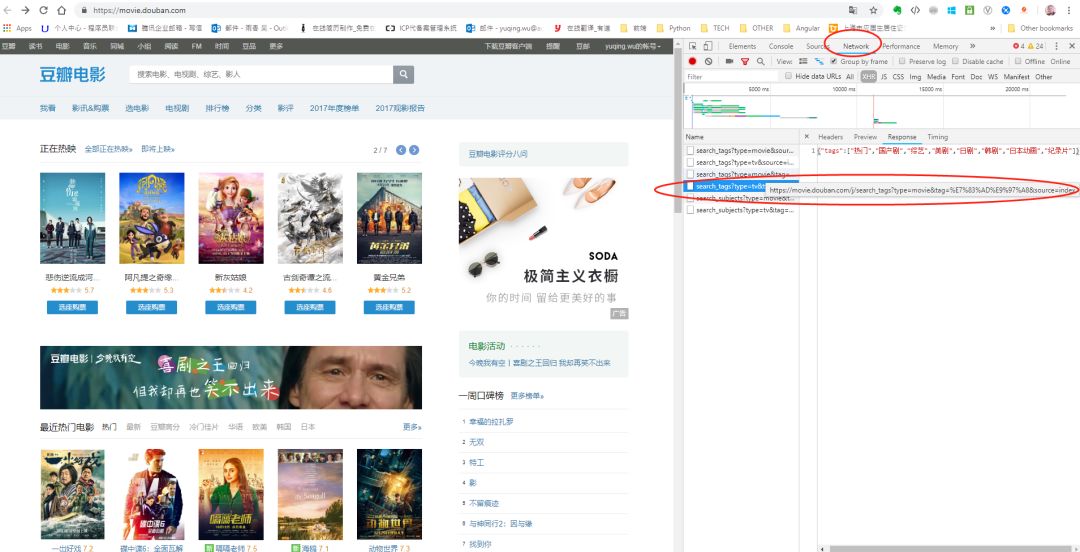
选中圈圈里的内容,右键选择“copy”,再选择“Copy as Curl”
之后把copy的内容粘贴到方框里:
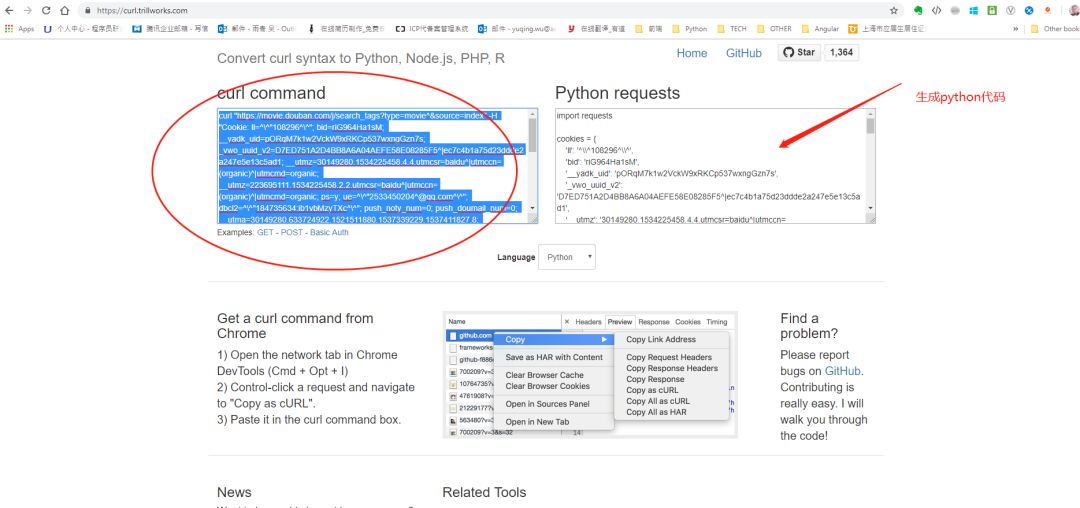
生成代码:
import requests
headers = {
'Origin': 'https://movie.douban.com',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Accept': '*/*',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive',
}
params = (
('include', 'anony_home'),
)
response = requests.get('https://m.douban.com/j/puppy/frodo_landing', headers=headers, params=params)
print(response.text)
#NB. Original query string below. It seems impossible to parse and
#reproduce query strings 100% accurately so the one below is given
#in case the reproduced version is not "correct".
# response = requests.get('https://m.douban.com/j/puppy/frodo_landing?include=anony_home', headers=headers)
是不是很方便?
都不用自己手动一个一个去找了!

这篇关于爬虫的各位看过来的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









