本文主要是介绍支持处理30万中文汉字的超长文本大模型——“国产大模型五虎”之零一万物,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
在前面的四篇文章中,我们分别介绍了KimiChat,MiniMax,智谱AI以及百川智能四个国产大模型,他们都被称之为“国产大模型五虎”。今天来到了这个系列的最后一章:零一万物,至此,大模型五虎全部集齐。
在介绍零一万物之前,我们先来看一组数据
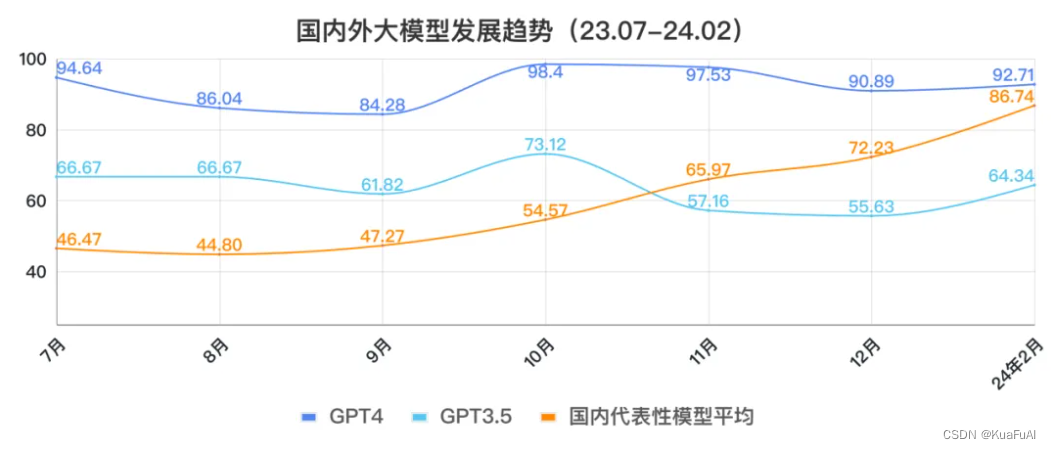 这是截止到今年2月份, 中文大模型基准SuperCLUE统计的关于“国内外大模型发展趋势”的数据,其中的数值代表了发展的水平,我们可以清晰的看到虽然GPT一直是处于领先地位,但是国内的大模型已经实现了代际赶超的奇迹,远超GPT3.5的水平,无限接近GPT4.0的能力。
这是截止到今年2月份, 中文大模型基准SuperCLUE统计的关于“国内外大模型发展趋势”的数据,其中的数值代表了发展的水平,我们可以清晰的看到虽然GPT一直是处于领先地位,但是国内的大模型已经实现了代际赶超的奇迹,远超GPT3.5的水平,无限接近GPT4.0的能力。
由此可知,尽管国内大模型发展起步的晚,但是在发展规模和发展潜力上却有着显著的优势。同样的,今天我们介绍的大模型,也是起步虽晚,但目前已经在超长文本处理领域取得了领先的地位。
下面我们就来一探究竟,看看这最后“一虎”,到底有何能力受诸多资方的青睐

提到李开复,相信大家都不陌生吧,曾在微软,谷歌等企业任职,后来创立了创新工场,一直活跃在AI领域。
零一万物则是由他带领一众全球顶尖科技公司的专业人才创立的一家AI大模型创业公司,专注于AI 2.0平台和应用的研发。

零一万物最新发布的大模型是“Yi”系列,包括Yi-6B和Yi-34B两个版本,
Yi-34B是一个具有340亿参数的基础模型,而Yi-6B的参数规模为60亿
这两个模型都是中英双语开源大模型
Yi-34B在关键指标上胜过市场上已有的领先开源模型,包括Meta的Llama 2,并在Hugging Face英文开源社区平台和C-Eval中文评测的最新榜单中爬升到第一位,成为全球开源大模型“双料冠军”
Yi-34B拥有全球大模型中最长的200K上下文窗口,可以处理约40万字的文本(官网公布的数据,实际上属于是反向虚标了,值得表扬),相当于他可以阅读理解超1000页PPT,一次性读完两本《三体》
既然说到这了,那我们就来实测一下看看它超长文本处理的能力到底是不是浪得虚名
我节选了《平凡的世界》的其中部分文字约25万字(原文100W字),来测试一下它的阅读能力
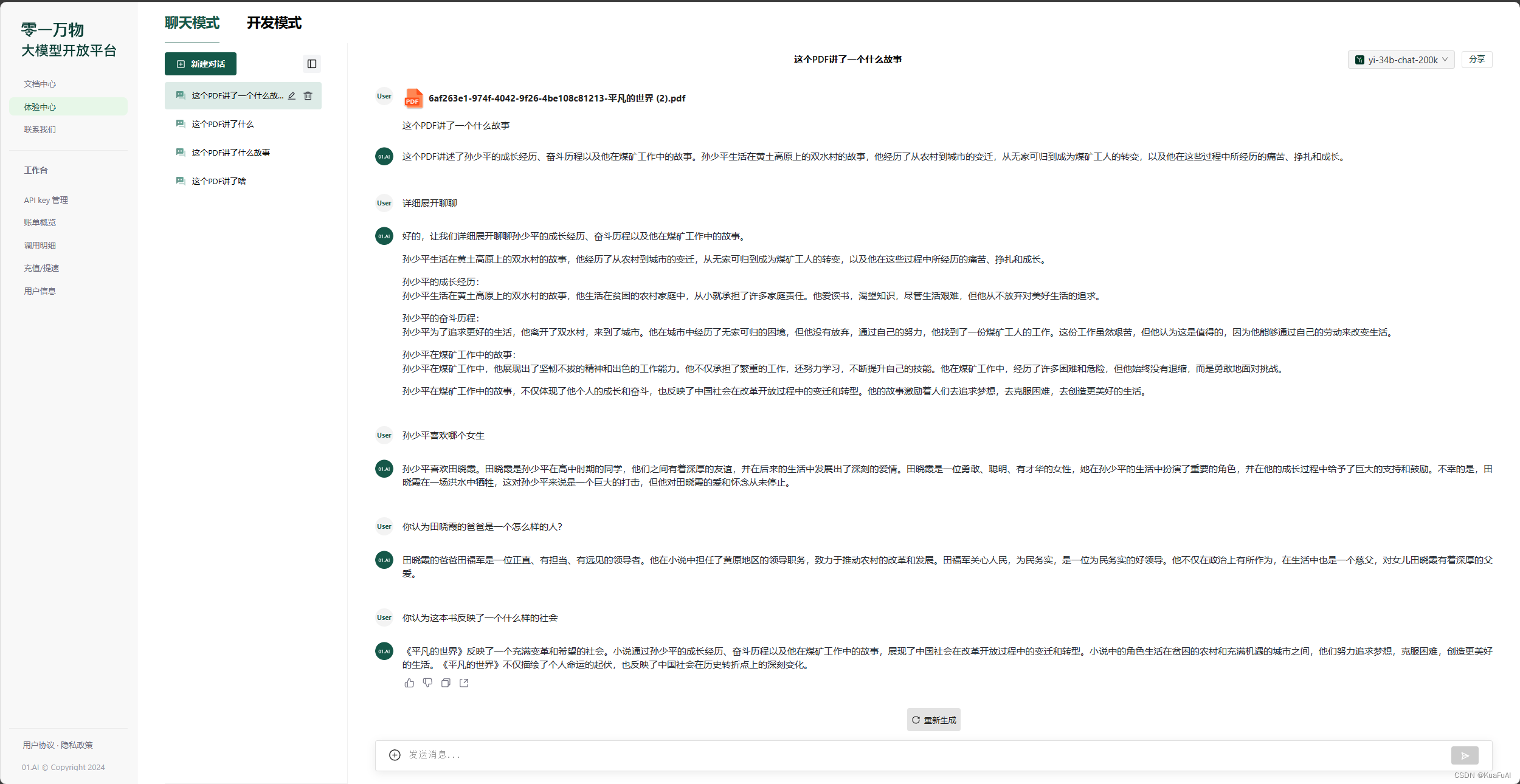
一共问了5个问题,从最基本的阅读,再到理解 ,和发表自己的看法,零一万物都给出了比较满意的答案。
不亏是霸榜SuperCLUE-256k的唯一大模型

超长文本能力确实吊,那我们再试试它的其它能力
老规矩,放上一个数学题让它解一下看看
我向它提问:565547854121的平方是多少
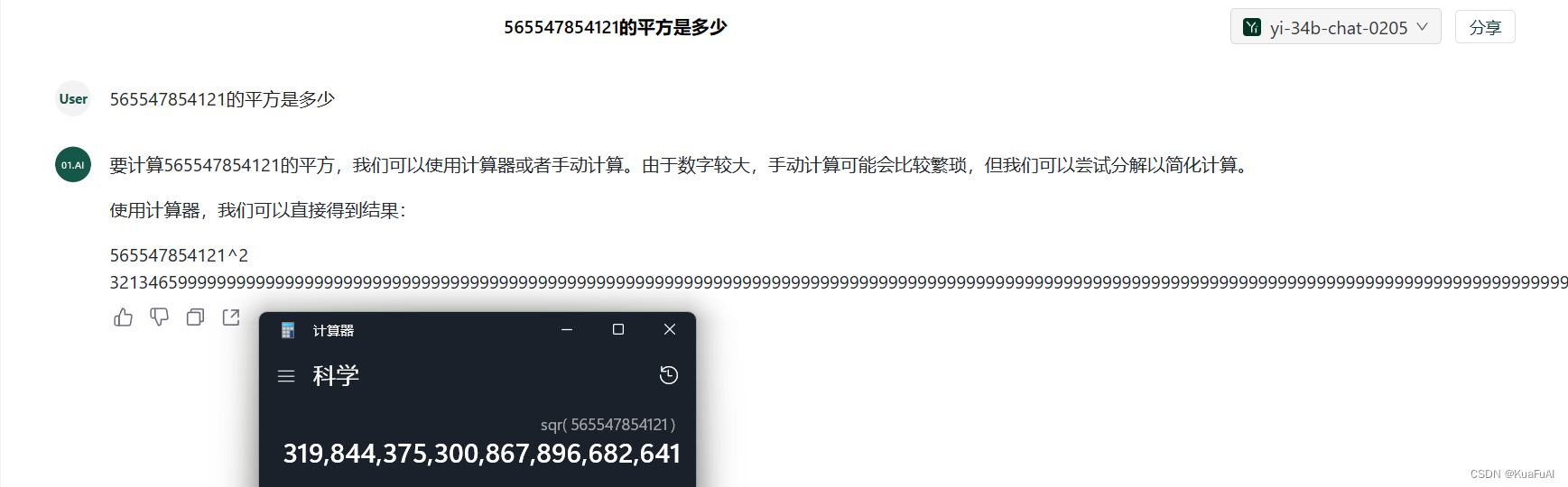
这就尴尬了不是,后面给我打了无数个9
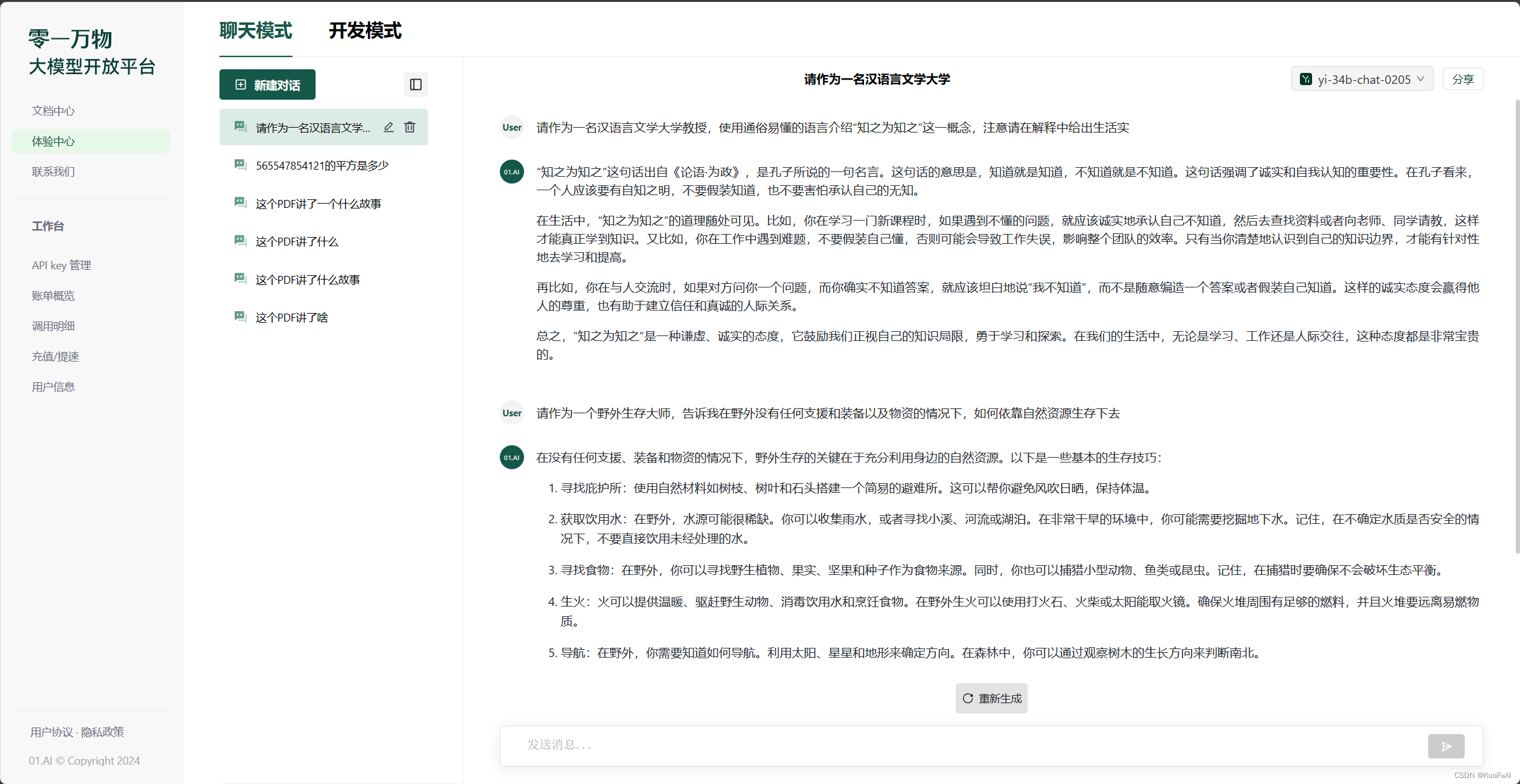
又试了一下角色扮演能力,中规中矩,跟其它几个大模型表现的水平差不多
简单总结一下,Yi-34B确实有自己的过人之处,被称之为AI独角兽确实当之无愧,但是在一些方面还是距ChatGPT有不小的差距。
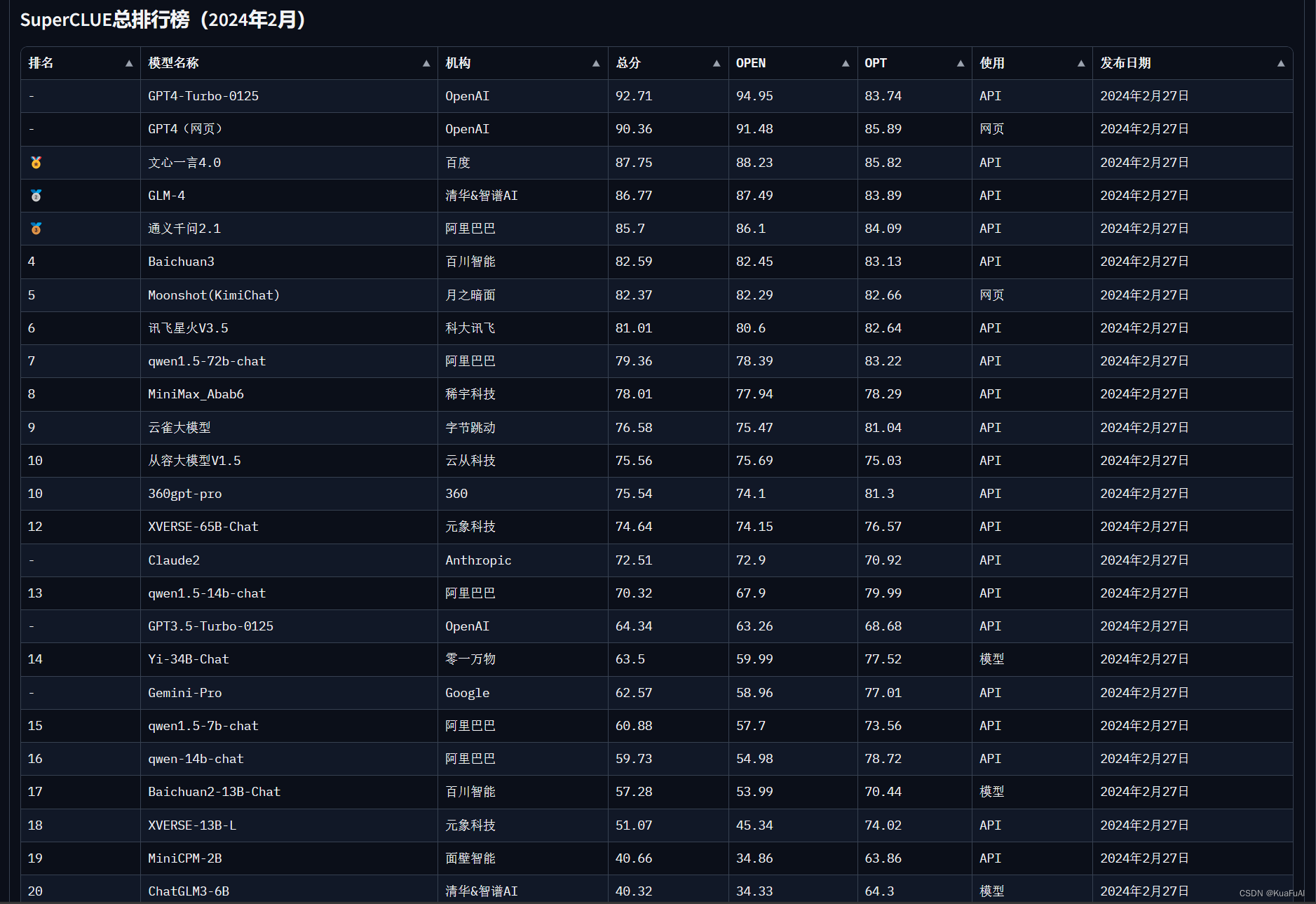
最后附上一张当前最新的国内外大模型能力总排行榜单
这篇关于支持处理30万中文汉字的超长文本大模型——“国产大模型五虎”之零一万物的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




