本文主要是介绍本地搭建属于你自己的AI搜索引擎 支持多家AI模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FreeAskInternet 是一个完全免费、私有且本地运行的搜索聚合器,并使用 MULTI LLM 生成答案,无需 GPU。用户可以提出问题,系统将进行多引擎搜索,并将搜索结果合并到LLM中,并根据搜索结果生成答案。全部免费使用。
项目简介
GitHub:https://github.com/nashsu/FreeAskInternet
我们可以直接可以进行提问,项目将使用 searxng 进行多引擎搜索,并将搜索结果与 ChatGPT3.5 LLM 结合,基于搜索结果生成答案。
所有过程在本地运行,可以完全不需要 GPU 或 OpenAI 或 Google API 密钥。
- 🈚️完全免费(不需要任何API密钥)
- 💻 完全本地化(无需GPU,任何计算机都可以运行)
- 🔐完全私有(所有东西都在本地运行,使用自定义llm)
- 👻 无需 LLM 硬件即可运行(无需 GPU!)
- 🤩 使用免费的 ChatGPT3.5 / Qwen / Kimi / ShipuAI(GLM) API(无需 API 密钥!感谢 OpenAI)
- 🐵 定制LLM(ollama,llama.cpp)支持,是的,我们喜欢ollama!
- 🚀 使用 Docker Compose 快速轻松地部署
- 🌐 Web 和移动友好界面,专为 Web 搜索增强的 AI 聊天而设计,允许从任何设备轻松访问。
基于搜索的人工智能聊天:
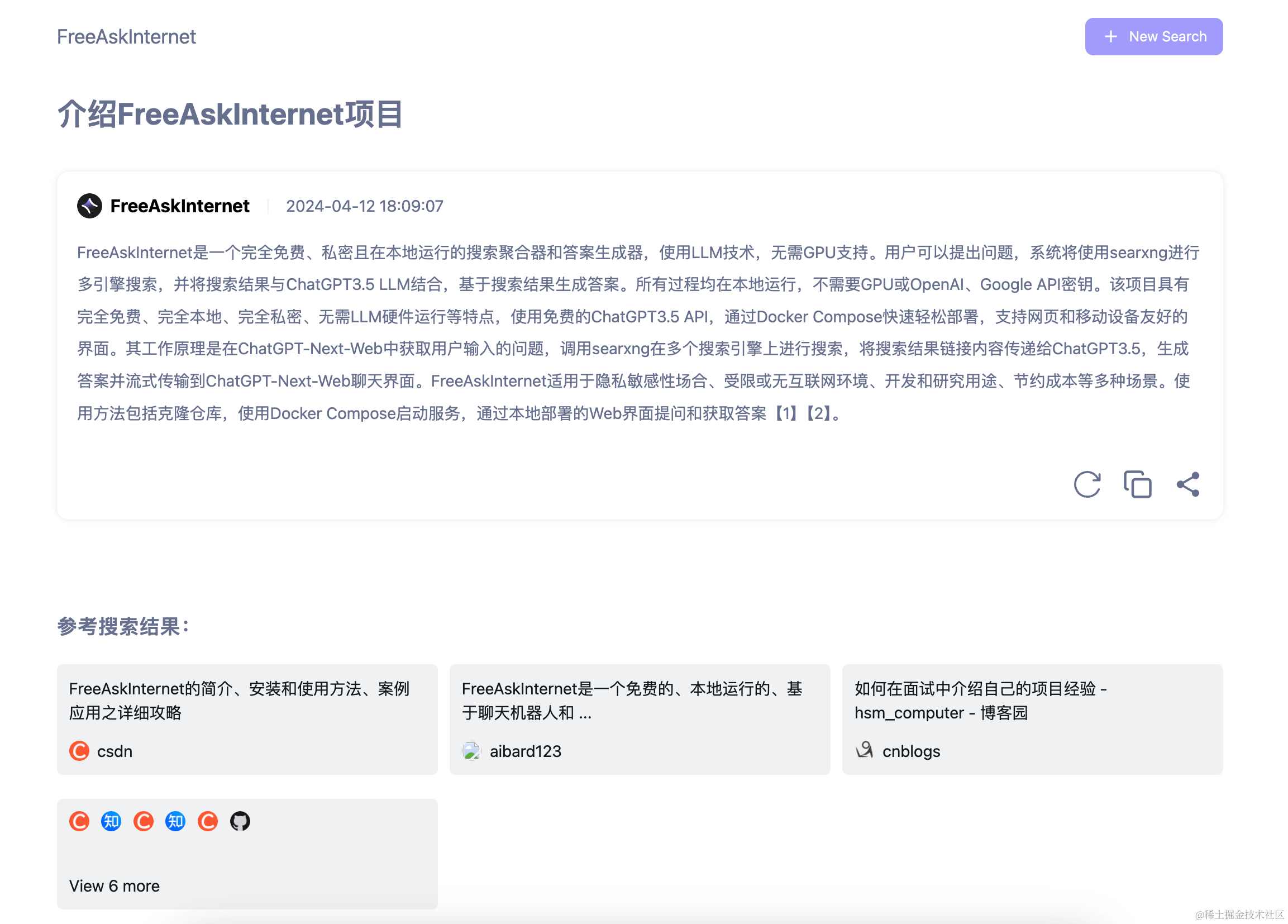
多LLM模型和自定义LLM(如ollama)支持:
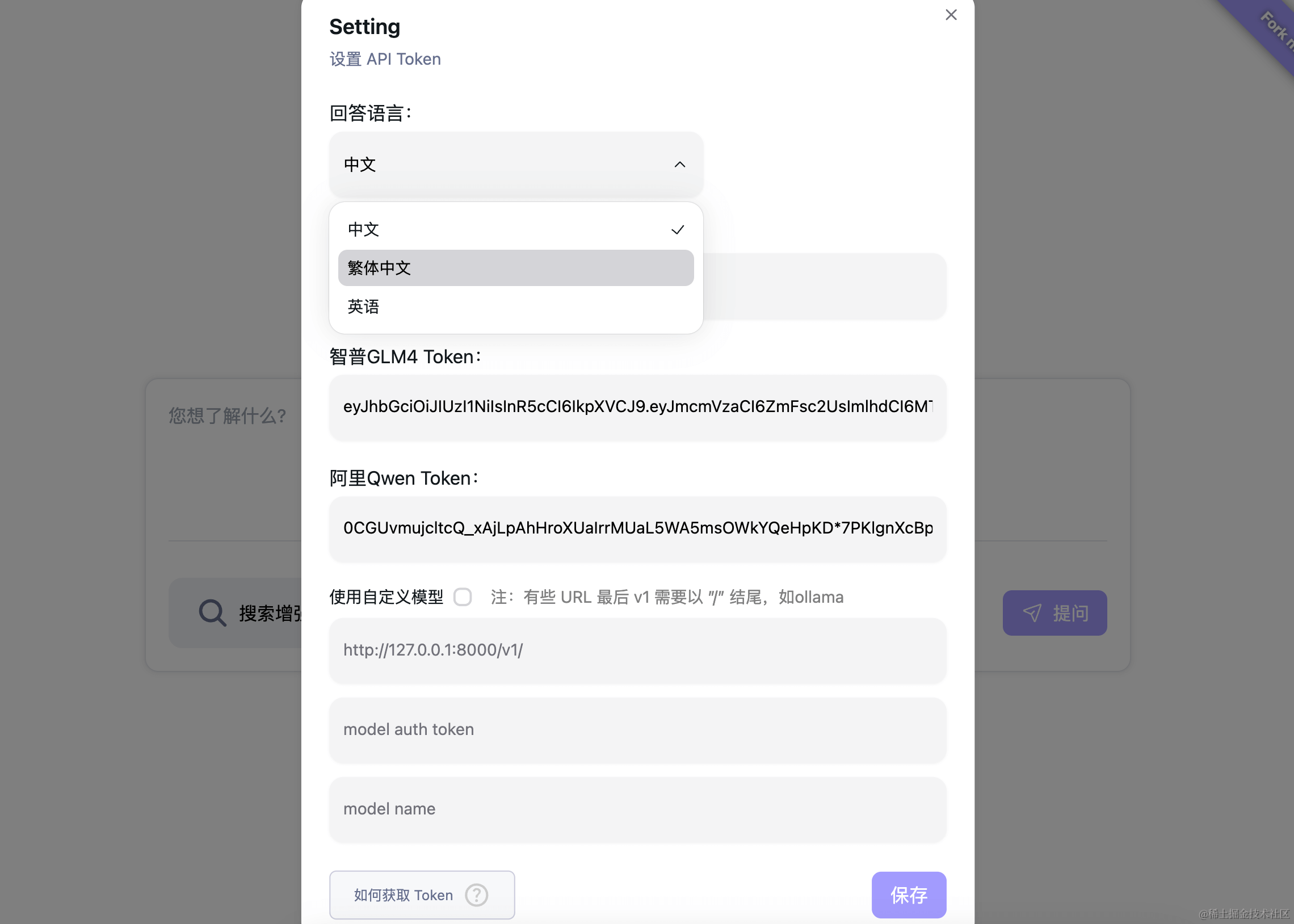
怎么运行的?
- 系统在FreeAskInternet UI界面(本地运行)中获取用户输入的问题,并调用searxng(本地运行)在多个搜索引擎上进行搜索。
- 抓取搜索结果链接内容并传递给ChatGPT3.5/Kimi/Qwen/ZhipuAI/ollama(通过使用自定义llm),让LLM根据此内容作为参考回答用户问题。
- 将答案传输到聊天 UI。
- 我们支持自定义LLM设置,因此理论上无限的LLM支持。
运行安装:
首先我们需要准备一台Linux服务器,这里我推荐伍六七云:https://www.vps567.com/ 香港2H2G 5M服务器只需要20元
还有国内外高防服务器,免费虚拟主机以及全球CDN加速挂机宝等业务。
并且我们需要在服务器上预先安装好Docker:Docker 一键安装脚本 再执行下面的安装命令。
git clone https://github.com/nashsu/FreeAskInternet.git
cd ./FreeAskInternet
docker-compose up -d
🎉 您现在应该能够在http://localhost:3000上打开 Web 界面。默认情况下不会公开任何其他内容。
注意:如果你的服务器不支持服务Chat GPT,那么你将无法使用免费的Chat GPT搜索结果和AI对话,只能在设置中自定义其他模型的AI接口和模型。伍六七云香港服务器完美支持链接到Chat GPT。
检查是否支持链接到gpt脚本:
bash <(curl -L -s check.unlock.media)
如何更新到最新
cd ./FreeAskInternet
git pull
docker compose down
docker compose rm backend
docker compose rm free_ask_internet_ui
docker image rm nashsu/free_ask_internet
docker image rm nashsu/free_ask_internet_ui
docker-compose up -d
原文链接:https://www.4awl.net/4898.html
这篇关于本地搭建属于你自己的AI搜索引擎 支持多家AI模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







